







首先我们打开软件,界面如下:
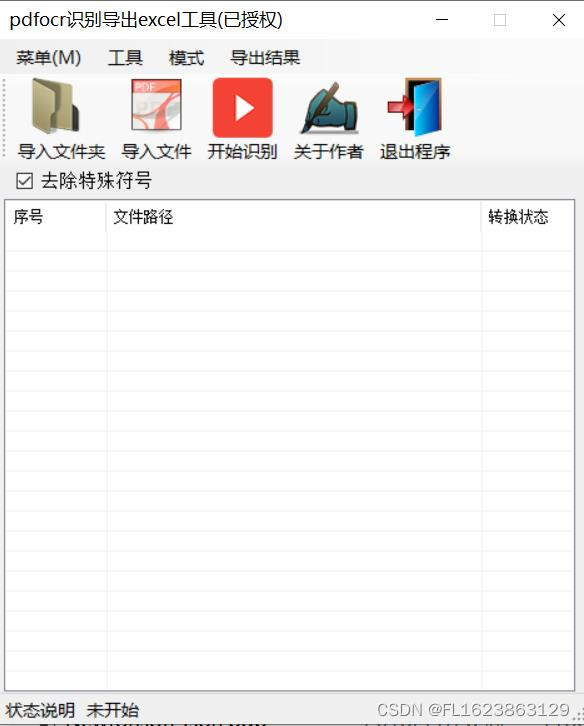
如上图,使用非常简单,步骤如下:
(1)选择工具-取模板选择一个pdf文件划定自己需要识别的区域,如果你选择第2页指定区域则软件统一识别所有pdf第2页指定区域,划定区域后需要添加区域,最后保存模板,这样下次启动软件无需再次取模板。
取模板截图:
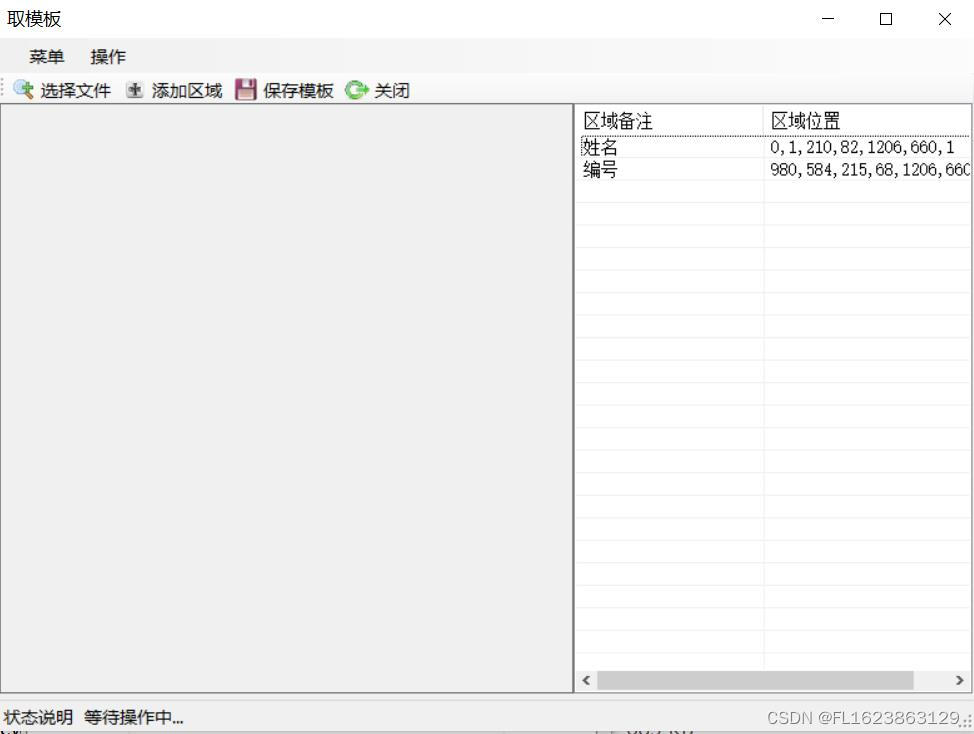
(2)把含有pdf文件的文件夹拖拽到列表即可完成导入,之后点击开始识别就可以了,最后点击导出识别结果即可导出excel,文件为xlsx格式,操作非常简单。但是有几个问题需要注意:
第一:OCR识别和划定区域有关,识别效果依照实际情况确认,比如图像质量,模糊度已经场景复杂度,理论上背景简单计算机机打文字识别效果最好;
第二:不可能做到100%识别,目前不存在100%识别情况,即使业界最先进OCR算法也是不可能的,由于图像复杂性、多样性,光照、倾斜、模糊等,有的可能根本无法识别;
第三:为了防止软件在做低效运转,请尽量保持pdf页数越少越好
具体参考视频教程:
 https://www.bilibili.com/video/BV1Yi4y1B7iX/?vd_source=989ae2b903ea1b5acebbe2c4c4a635ee
https://www.bilibili.com/video/BV1Yi4y1B7iX/?vd_source=989ae2b903ea1b5acebbe2c4c4a635ee


















 1113
1113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











