







 超级会员免费看
超级会员免费看
目录
0 写在前面
机器学习强基计划聚焦深度和广度,加深对机器学习模型的理解与应用。“深”在详细推导算法模型背后的数学原理;“广”在分析多个机器学习模型:决策树、支持向量机、贝叶斯与马尔科夫决策、强化学习等。强基计划实现从理论到实践的全面覆盖,由本人亲自从底层编写、测试与文章配套的各个经典算法,不依赖于现有库,可以大大加深对算法的理解。
本文主要通过案例宏观上介绍引入贝叶斯网络的动机及其概念,关于贝叶斯网络的微观结构、概率影响是如何通过网络流动的、有向分离、推断算法等概念,请看
- 机器学习强基计划5-3:图文详解因子分解与独立图I-Map(附例题分析+Python实验)
- 机器学习强基计划5-4:图文详解影响流动性与有向分离(D-分离)(附Python实现)
- 机器学习强基计划5-5:用一个例子通俗理解变量消除法VE原理(附Python实验)
1 从一个案例出发
例1:学生成绩 G G G不仅取决于他的智商 I I I,同时也取决于课程的难度 D D D。学生请求教授为其写推荐信,教授仅能通过查看该生的成绩单来决定推荐信的好坏 L L L。学生的智商一定程度上也影响了其高考成绩 S S S。通过一种最直观的因果关系组织本例的5个随机变量如图所示,其中除成绩可以取“优”、“良”、“中”三个值外,其他均为二值随机变量。
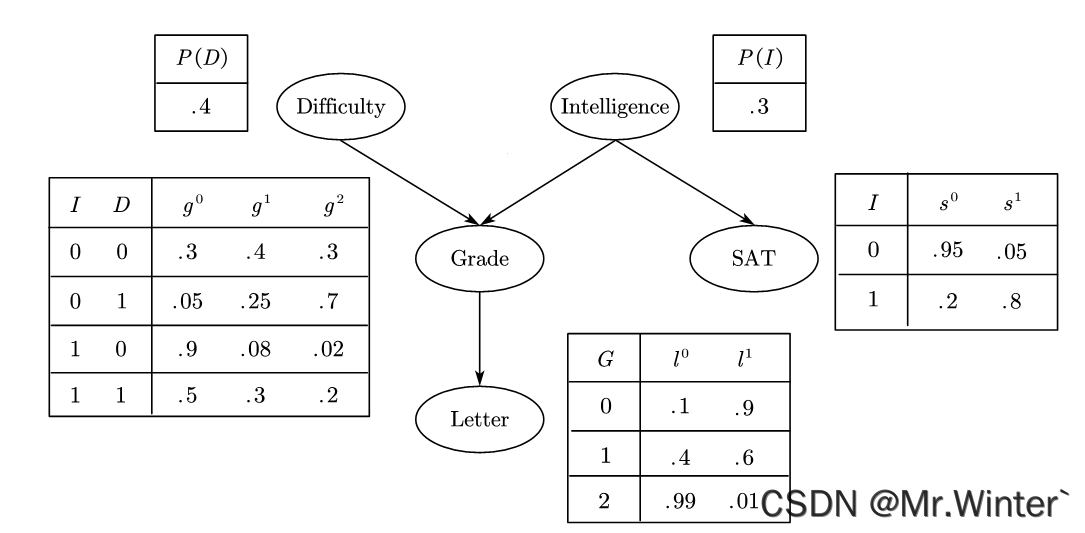
现在就这个案例提几个问题:
- 分析该生能获得好的推荐信的概率;
- 分析该生有高智商的概率;
- 课程成绩 G G G已知时,课程难度 D D D会影响推荐信 L L L的好坏吗?
- 课程难度 D D D已知时,推荐信质量 L L L会影响成绩 G G G高低吗?
- 智商 I I I已知时,课程成绩 G G G会影响高考成绩 S S S吗?
- 课程成绩 G G G已知时,课程难度 D D D会影响智商 I I I吗?
围绕这几个问题逐步引出贝叶斯网络的定义。
2 概率推断
2.1 因果推断
对于问题1,在对该生其他信息一无所知的前提下,获得好的推荐信的概率
P ( l 1 ) = ∑ g P ( l 1 ∣ g ) P ( g ) = ∑ g P ( l 1 ∣ g ) ∑ i , d P ( g ∣ i , d ) P ( i ) P ( d ) ≈ 50.2 % P\left( l^1 \right) =\sum_g{P\left( l^1|g \right) P\left( g \right)}=\sum_g{P\left( l^1|g \right) \sum_{i,d}{P\left( g|i,d \right) P\left( i \right) P\left( d \right)}}\approx 50.2\% P(l1)=g∑P(l1∣g)P(g)=g∑P(l1∣g)i,d∑P(g∣i,d)P(i)P(d)≈50.2%
如果得知该生智商不高,那么可能成绩 G G G不太好,从而影响其推荐信的质量
P ( l 1 ∣ i 0 ) = ∑ g P ( l 1 ∣ g ) P ( g ∣ i 0 ) = ∑ g P ( l 1 ∣ g ) ∑ d P ( g ∣ i 0 , d ) P ( d ) ≈ 38.9 % P\left( l^1|i^0 \right) =\sum_g{P\left( l^1|g \right) P\left( g|i^0 \right)}=\sum_g{P\left( l^1|g \right) \sum_d{P\left( g|i^0,d \right) P\left( d \right)}}\approx 38.9\% P(l1∣i0)=g∑P(l1∣g)P(g∣i0)=g∑P(l1∣g)d∑P(g∣i0,d)P(d)≈38.9%
如果进一步得知课程比较简单,那么成绩 G G G可能得到提升,从而影响其推荐信的质量
P ( l 1 ∣ i 0 , d 0 ) = ∑ g P ( l 1 ∣ g ) P ( g ∣ i 0 , d 0 ) ≈ 51.3 % P\left( l^1|i^0,d^0 \right) =\sum_g{P\left( l^1|g \right) P\left( g|i^0,d^0 \right)}\approx 51.3\% P(l1∣i0,d0)=g∑P(l1∣g)P(g∣i0,d0)≈51.3%
这类从原因顺流而下推断结果的过程称为因果推断或预测。
2.2 证据推断
对于问题2,在对该生其他信息一无所知的前提下,其具有高智商的概率即为先验概率
P
(
i
1
)
=
30
%
P\left( i^1 \right) =30\%
P(i1)=30%,假设获知该生成绩
G
G
G不太好,则可以怀疑其不具有高智商
P ( i 1 ∣ g 2 ) = P ( g 2 ∣ i 1 ) P ( i 1 ) P ( g 2 ) = P ( i 1 ) ∑ d P ( g 2 ∣ i 1 , d ) P ( d ) ∑ i , d P ( g 2 ∣ i , d ) P ( i ) P ( d ) ≈ 7.89 % P\left( i^1|g^2 \right) =\frac{P\left( g^2|i^1 \right) P\left( i^1 \right)}{P\left( g^2 \right)}=\frac{P\left( i^1 \right) \sum_d{P\left( g^2|i^1,d \right) P\left( d \right)}}{\sum_{i,d}{P\left( g^2|i,d \right) P\left( i \right) P\left( d \right)}}\approx 7.89\% P(i1∣g2)=P(g2)P(g2∣i1)P(i1)=∑i,dP(g2∣i,d)P(i)P(d)P(i1)∑dP(g2∣i1,d)P(d)≈7.89%
这类从结果逆流而上回溯原因的过程称为证据推断或解释。
3 概率独立
3.1 间接因果作用
直观地,若课程成绩 G G G未知,则当课程较难时,成绩较差的可能性提升,获得好的推荐信的概率下降;同理当课程较容易时,获得好的推荐信的概率提升。相反,若课程成绩 G G G已知,则推荐信的好坏 L L L可以直接由 G G G推断——课程难度 D D D无法改变已观测的事实来影响 L L L,换言之,课程难度 D D D的影响已被包含在课程成绩 G G G的影响中
( L ⊥ D ∣ G ) ⇒ P ( l ∣ g , d ) = P ( l ∣ g ) \left( L\bot D|G \right) \Rightarrow P\left( l|g,d \right) =P\left( l|g \right) (L⊥D∣G)⇒P(l∣g,d)=P(l∣g)
3.2 间接证据作用
直观地,无论课程难度 D D D是否已知,推荐信的好坏 L L L都可以作为证据来影响对课程成绩 G G G的判断,例如即使已知课程很难,但若该生获得好的推荐信仍可以提高其课程取得高分的概率 P ( g 0 ∣ d 1 , l 1 ) > P ( g 0 ∣ d 1 ) P\left( g^0|d^1,l^1 \right) >P\left( g^0|d^1 \right) P(g0∣d1,l1)>P(g0∣d1)。
3.3 共同的原因
直观地,若智商 I I I未知,则当课程成绩 G G G较好时,可以作为该生智商 I I I较高的证据,从而导致其高考成绩 S S S较好的信度上升;同理当课程成绩 G G G较差时,其高考成绩 S S S较好的信度下降。相反,若智商 I I I已知,课程成绩 G G G的好坏就不会对高考成绩 S S S的判断提供任何额外信息
( G ⊥ S ∣ I ) ⇒ P ( s 1 ∣ g 1 , i 1 ) = P ( s 1 ∣ i 1 ) \left( G\bot S|I \right) \Rightarrow P\left( s^1|g^1,i^1 \right) =P\left( s^1|i^1 \right) (G⊥S∣I)⇒P(s1∣g1,i1)=P(s1∣i1)
3.4 共同的作用
直观地,若课程成绩 G G G未知,则课程难度 D D D和智商 I I I互相独立 ,因为证据 G G G不充分,无法回溯影响对原因的判断。相反,若课程成绩 G G G已知且假设较差,则当课程较难时,可能以较大的权重解释了成绩较差原因,从而提升该生具有高智商的信度
同理,当课程较容易时,该生具有高智商的信度会急剧下降——低智商成为成绩较差的唯一解释。当某个结果的产生存在多个可能原因时,若其中某些原因很好地解释了结果,则该结果对其他原因的影响会被削弱,称为解释消除(Explaining Away),例如 P ( i 1 ∣ g 2 ) ≈ 7.9 % P\left( i^1|g^2 \right) \approx 7.9\% P(i1∣g2)≈7.9%但 P ( i 1 ∣ g 2 , d 1 ) ≈ 11 % P\left( i^1|g^2,d^1 \right) \approx 11\% P(i1∣g2,d1)≈11%。
4 贝叶斯网络

贝叶斯网络(Bayesian Network)又称信念网络(Belief Network),模拟了人类推理过程中因果关系的不确定性。贝叶斯网络是一个偶对 B = ( G , P ) \mathcal{B} =\left( \mathcal{G} ,P \right) B=(G,P),即由网络拓扑结构以及概率分布两部分组成,其中
-
网络结构 G = ( V , E ) \mathcal{G} =\left( V,E \right) G=(V,E)是有向无环图(Directed Acyclic Graphical, DAG), V V V是图形中所有节点——随机变量的集合; E E E是所有有向连边——变量间因果依赖的集合,如图所示。

网络结构蕴含一系列独立性断言,其中直观的是因果独立性断言
I l ( G ) = { ( X i ⊥ N o n D e s c e n d e n c e X i ∣ P a X i ) ∣ ∀ X i ∈ B } \mathcal{I} _l\left( \mathcal{G} \right) =\left\{ \left( X_i\bot \mathrm{NonDescendence}_{X_i}|\mathrm{Pa}_{X_i} \right) |\forall X_i\in \mathcal{B} \right\} Il(G)={(Xi⊥NonDescendenceXi∣PaXi)∣∀Xi∈B}
即在给定父节点的条件下,每个节点与其非后代节点条件独立,但后代节点在被观测到的前提下,仍可作为证据影响该节点 -
概率分布 P P P是在网络结构 G \mathcal{G} G上的因子分解,满足
P ( X 1 , X 2 , ⋯ , X m ) = ∏ i m P ( X i ∣ P a X i ) P\left( X_1,X_2,\cdots ,X_m \right) =\prod_i^m{P\left( X_i|\mathrm{Pa}_{X_i} \right)} P(X1,X2,⋯,Xm)=i∏mP(Xi∣PaXi)
上式也称为贝叶斯网络链式法则,单个因子称为网络的局部概率模型。
5 贝叶斯网络例题分析
例2:如图所示的贝叶斯网络,令 P ( B u r g l a r y = F a l s e ∣ J h o n C a l l s = T r u e , M a r y C a l l s = T r u e ) ≡ P ( ¬ B ∣ J , M ) P\left( Burglary=False|JhonCalls=True,MaryCalls=True \right) \equiv P\left( \lnot B|J,M \right) P(Burglary=False∣JhonCalls=True,MaryCalls=True)≡P(¬B∣J,M),求 P ( ¬ B ∣ J , M ) P\left( \lnot B|J,M \right) P(¬B∣J,M)的归一化概率


🔥 更多精彩专栏:















 620
620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











