






【独家原创未发表】KAN(Kolmogorov–Arnold Network)回归 Matlab代码
基于KAN网络(Knowledge-Adaptive Network)的数据回归预测,Matlab代码,可直接运行,适合小白新手
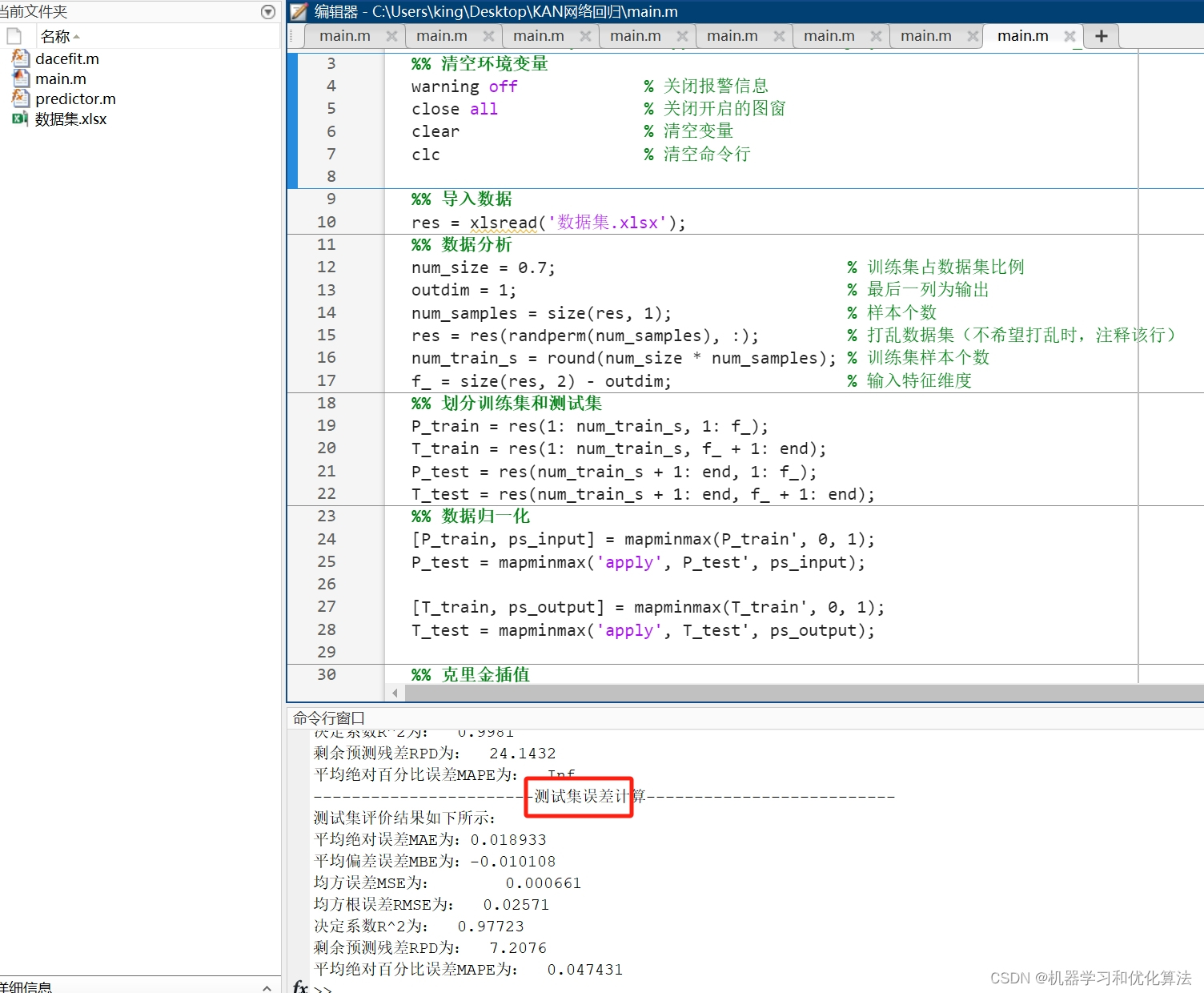
1、程序已经调试好,无需更改代码替换数据集即可运行!!!数据格式为excel!
2、KAN网络(Knowledge-Adaptive Network)是结合知识和数据驱动的方法,通过引入先验知识来提升模型的性能。该网络结构在处理复杂的机器学习问题时,尤其是在数据有限或不均衡的情况下,能够更好地发挥作用。从而提高预测精度和鲁棒性。
3、通过克里金插值(Kriging)方法,将先验知识(空间相关性)引入数据处理过程中。
4、你先用你就是创新!!!
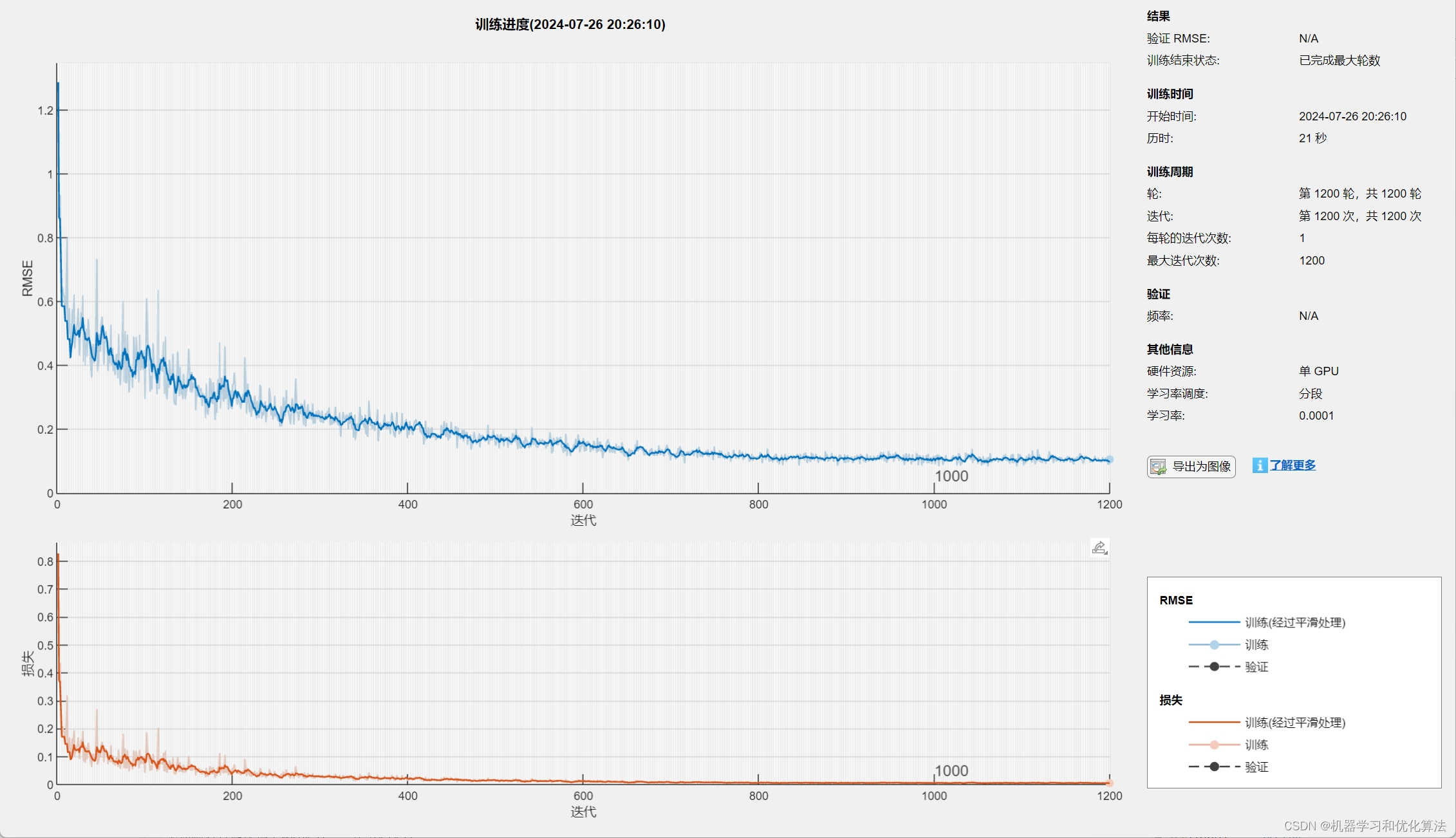
1️⃣、运行环境要求MATLAB版本为2023b及其以上【没有我赠送】
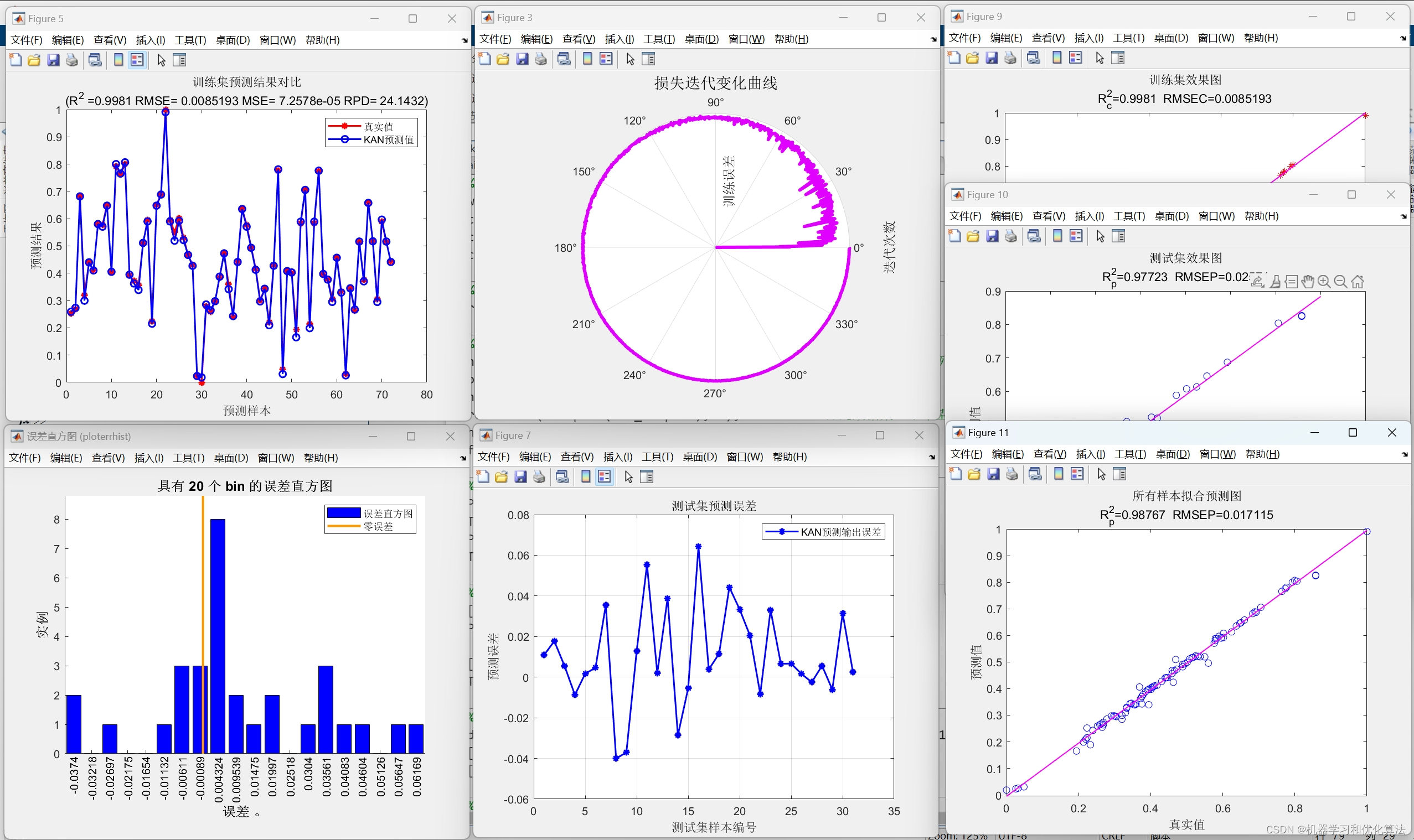
2️⃣、评价指标包括:R2、MAE、MSE、RPD、RMSE等,图很多,符合您的需要
3️⃣、代码中文注释清晰,质量极高
4️⃣、赠送测试数据集,可以直接运行源程序。替换你的数据即可用 适合新手小白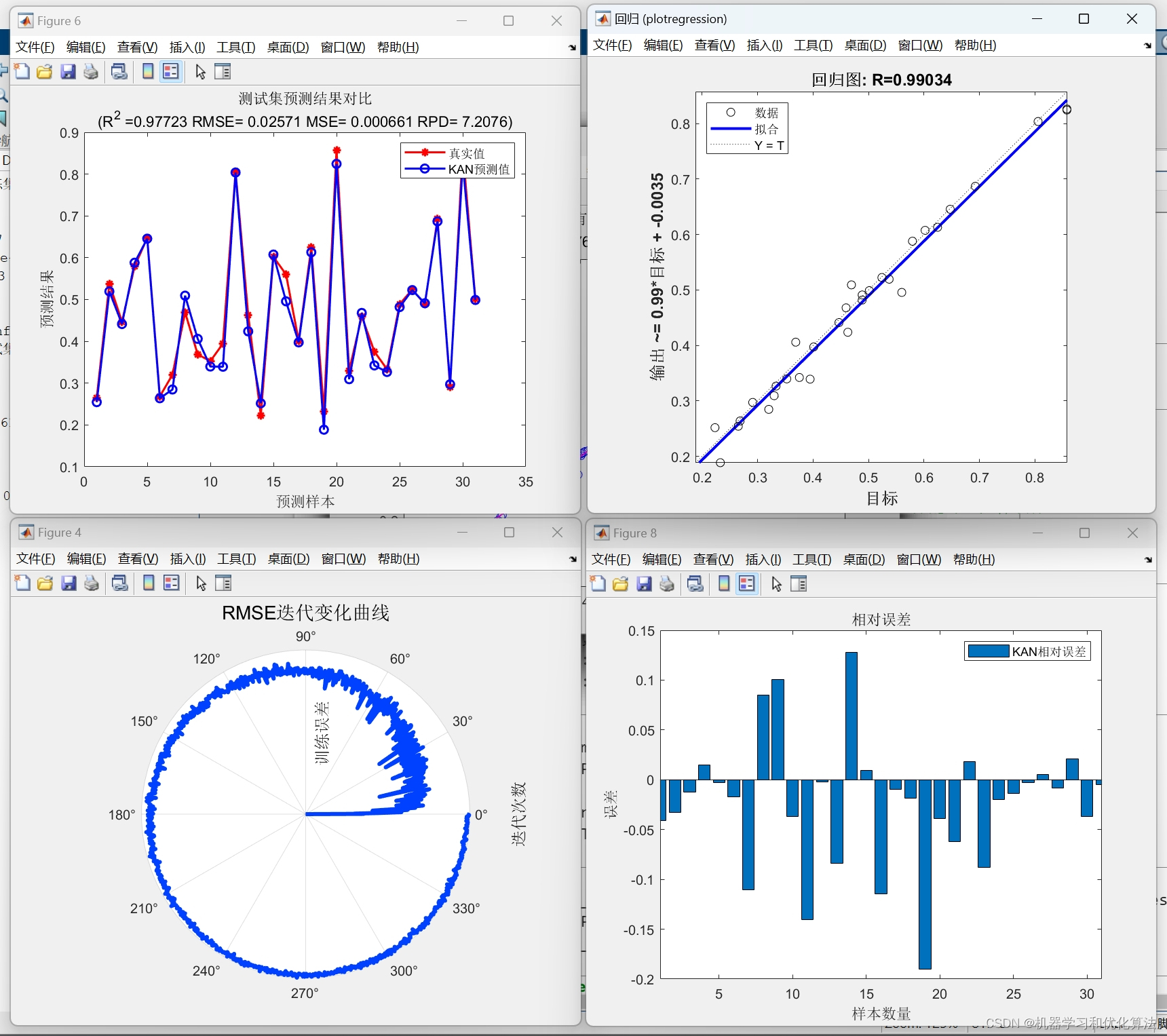















 342
342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









