






以下内容来自知乎链接:
https://zhuanlan.zhihu.com/p/620820228
作者:日暮途远 已获得作者同意转载。
最近看到了一篇广发证券的关于使用Transformer进行量化选股的研报,在此进行一个复现记录,有兴趣的读者可以进行更深入的研究。

来源:广发证券
应用的Transformer架构
其中报告中基于传统Transformer的改动如下:
1.替换词嵌入层为线性层:
在NLP领域,需要通过词嵌入将文本中的词转换为词向量作为输入,而在股票数据中大多数情况下,输入基本都会有数值型数据。所以将词嵌入层替换为常规的线性层,通过线性变换代替词嵌入的过程。
2.拓展数据输入到面板数据
虽然Transformer模型最初是设计为接收一维序列(即一个句子)作为输入的,但通过将词嵌入层替换为线性层的修改后,模型可以直接处理多维序列(即面板数据)。
这个已经通过上面的线性层实现个人认为不算明显的改动。
3.取消解码器的逐个预测机制和掩码操作
股票预测中,我们通常希望能准确预测未来一段时间的收益情况,因此模型输出一般为一个值(回归问题)或涨跌概率(分类问题),因此我们对解码器进行简化,取消了逐个预测机制和掩码操作。
数据介绍以及预处理
文章中使用的特征为个股过去20个月的月度量价数据中选取特征序列,每期的每只股票都是一个样本,特征向量可以表示为
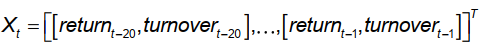
其中return表示股票每月涨跌幅;turnover表示股票每月换手率(每日换手率之和)。
这也是之后用到的每个数据的维度(20, 2), 其中20是时间步长,2是特征维度。
之后对特征进行预处理:
1. 缺失值处理:当股票某一时刻的特征值缺失时(上市不满20个月的情况除外),使用上一时
刻的特征值进行填充。
2.极值、异常值处理:均值加三倍标准差缩边。
3.截面标准化。
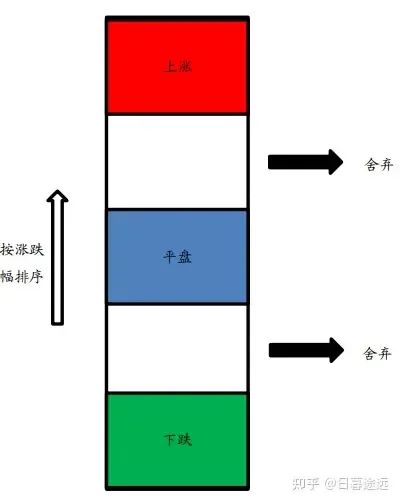
关于label的给定,这里使用的是分类的概念,对每月对样本内的所有股票按下个月相对基准的超额涨跌幅进行排序,取涨幅前20%的股票,标记为“上涨”;取涨幅居中20%的股票(涨幅位于40%分位数到60%分位数之间),标记为“平盘”;取涨幅末20%的股票,标记为“下跌”。
来源:广发证券
其中舍弃三类标签的中间两部分是因为要同时为了使不同标签样本之间的区别更明显且样本数尽可能接近,之后将标签进行热编码。
模型的参数选择和整体结构
序列向量维度(经过替代词嵌入层的线性层处理后的维度)、多头注意力机制头数、编码器和解码器层数需要提前设定,通过网格搜索方法,研报中参数组合确定为:
1. 序列向量维度d=64
2. 多头注意力机制头数h=8
3. 编码器和解码器层数N=6
最终模型结构如下:
[20,2](输入层)→[20,64](线性层)→8×[20,8](编码层1)→8×[20,8](编码层2)→8×[20,8](编码层3)→8×[20,8](编码层4)→8×[20,8](编码层5)→8×[20,8](编码层6)→8×[20,8](解码层1)→8×[20,8](解码层2)→8×[20,8](解码层3)→8×[20,8](解码层4)→8×[20,8](解码层5)→8×[20,8](解码层6)
→[3](输出层)
模型共有403075个参数需要进行训练
以下是根据文章描述搭建的transformer模型。首先构建多头注意力,编码器,解码器模块:
import torch
import torch.nn as nn
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
self.depth = int(d_model / num_heads)
self.W_Q = nn.Linear(d_model, d_model)
self.W_K = nn.Linear(d_model, d_model)
self.W_V = nn.Linear(d_model, d_model)
self.W_O = nn.Linear(d_model, d_model)
def forward(self, Q, K, V):
Q = self.W_Q(Q)
K = self.W_K(K)
V = self.W_V(V)
Q = self._split_heads(Q)
K = self._split_heads(K)
V = self._split_heads(V)
attention_weights = torch.matmul(Q, K.transpose(-1, -2)) / torch.sqrt(torch.tensor(self.depth, dtype=torch.float32))
attention_weights = torch.softmax(attention_weights, dim=-1)
output = torch.matmul(attention_weights, V)
output = self._combine_heads(output)
output = self.W_O(output)
return output
def _split_heads(self, tensor):
tensor = tensor.view(tensor.size(0), -1, self.num_heads, self.depth)
return tensor.transpose(1, 2)
def _combine_heads(self, tensor):
tensor = tensor.transpose(1, 2).contiguous()
tensor = tensor.view(tensor.size(0), -1, self.num_heads * self.depth)
return tensor
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads):
super(EncoderLayer, self).__init__()
self.attention = MultiHeadAttention(d_model, num_heads)
self.feedforward = nn.Sequential(
nn.Linear(d_model, 4 * d_model),
nn.ReLU(),
nn.Linear(4 * d_model, d_model)
)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
def forward(self, x):
attention_output = self.attention(x, x, x)
attention_output = self.norm1(x + attention_output)
feedforward_output = self.feedforward(attention_output)
output = self.norm2(attention_output + feedforward_output)
return output
class DecoderLayer(nn.Module):
def __init__(self, d_model, num_heads):
super(DecoderLayer, self).__init__()
self.self_attention = MultiHeadAttention(d_model, num_heads)
self.encoder_attention = MultiHeadAttention(d_model, num_heads)
self.feedforward = nn.Sequential(
nn.Linear(d_model, 4 * d_model),
nn.ReLU(),
nn.Linear(4 * d_model, d_model)
)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
def forward(self, x, encoder_output):
self_attention_output = self.self_attention(x, x, x)
self_attention_output = self.norm1(x + self_attention_output)
encoder_attention_output = self.encoder_attention(self_attention_output, encoder_output, encoder_output)
encoder_attention_output = self.norm2(self_attention_output + encoder_attention_output)
feedforward_output = self.feedforward(encoder_attention_output)
output = self.norm3(encoder_attention_output + feedforward再通过上述结构搭建transformer网络:
import torch
import torch.nn as nn
class Transformer(nn.Module):
def __init__(self, input_dim, hidden_dim, num_heads, num_layers):
super(Transformer, self).__init__()
self.input_layer = nn.Linear(input_dim, hidden_dim)
self.encoder_layers = nn.ModuleList([EncoderLayer(hidden_dim, num_heads) for _ in range(num_layers)])
self.decoder_layers = nn.ModuleList([DecoderLayer(hidden_dim, num_heads) for _ in range(num_layers)])
self.output_layer = nn.Linear(hidden_dim, 3)
def forward(self, x):
# Input layer
x = self.input_layer(x)
# Encoder layers
encoder_output = x.transpose(0, 1)
for layer in self.encoder_layers:
encoder_output = layer(encoder_output)
# Decoder layers
# 编码器最后一层的输出作为解码器的输入,当然也可以使用所有时间步长,则去掉这一行,将整个encoder_output传递给解码器
decoder_output = encoder_output[-1, :, :].unsqueeze(0)
for layer in self.decoder_layers:
decoder_output = layer(decoder_output, encoder_output)
# Output layer
output = self.output_layer(decoder_output.squeeze(0))
return output
其中,input_dim是输入的特征维度,这里是2;hidden_dim是模型中隐藏层的维度,这里是64;num_heads是多头注意力机制中头的个数,这里是8;num_layers是编码器和解码器中的层数,这里都是6。
训练完成后就可以读取训练好的模型进行股票分类预测了:
# 创建模型实例
model = Transformer(input_dim=2, hidden_dim=64, num_heads=8, num_layers=6)
# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练数据的维度为 (batch_size, 20, 2),标签的维度为 (batch_size, 3)
# 开始训练
for epoch in range(num_epochs):
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
# 输入数据
inputs, labels = data
inputs = inputs.float()
labels = labels.float()
optimizer.zero_grad()
outputs = model(inputs)
# 计算损失
loss = criterion(outputs, labels)
# 反向传播和优化
loss.backward()
optimizer.step()
# 统计损失
running_loss += loss.item()
# 输出统计信息
print('Epoch [%d/%d], Loss: %.4f' % (epoch+1, num_epochs, running_loss / len(train_loader)))全市场选股-多空对冲策略实证分析
在全市场A股,进行模型的训练和选股策略的回测。从2000年至2019年获取样本进行训练,在2020年到2023年(样本外),用训练好的Transformer预测模型进行策略回测,回测参数设置如下:
调仓周期:1个月
股票池:全市场股票(万得全A指数成份股),剔除交易日停牌的股票
回测期:2020年1月至2023年3月
交易成本:双边0.3%
假设可以卖空最低档(第五档)的股票,买入最高档(第一档)的股票,多空对冲策略自2020年以来,策略的年化收益率为15.58%,最大回撤为-12.09%,日度胜率为56.61%。

来源:广发证券
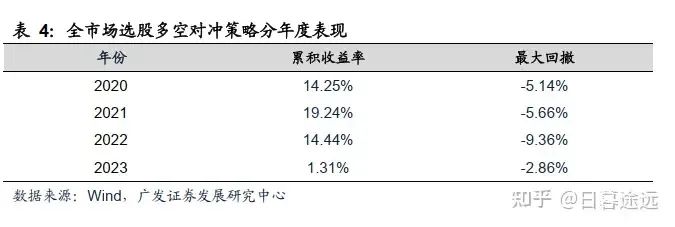
来源:广发证券
总结:本报告将Transformer模型引入投资领域,证明了Transformer因子具有一定的选股能力。从市场中众多使用时序网络(rnn)进行选股预测的研报中,为读者们提供了另一种神经网络拟合多因子的网络结构思路,有兴趣的读者可以做更深入的研究。
往期推荐阅读
【python量化】大幅提升预测性能,将NSTransformer用于股价预测
【python量化】将Transformer模型用于股票价格预测
【python量化】搭建一个CNN-LSTM模型用于股票价格预测

《人工智能量化实验室》知识星球

加入人工智能量化实验室知识星球,您可以获得:(1)定期推送最新人工智能量化应用相关的研究成果,包括高水平期刊论文以及券商优质金融工程研究报告,便于您随时随地了解最新前沿知识;(2)公众号历史文章Python项目完整源码;(3)优质Python、机器学习、量化交易相关电子书PDF;(4)优质量化交易资料、项目代码分享;(5)跟星友一起交流,结交志同道合朋友。(6)向博主发起提问,答疑解惑。















 709
709











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









