







 本文介绍了语音交互在智能座舱中的重要性及其关键技术,包括语音识别、自然语言处理和语音合成。语音识别涉及预处理、解码等步骤,自然语言处理包括理解用户意图和执行操作,而语音合成就将文本转化为语音输出。智能座舱中的语音交互系统通过硬件层、服务层、应用层和运营管理平台四个部分协同工作,提高了驾驶安全性与便利性。
本文介绍了语音交互在智能座舱中的重要性及其关键技术,包括语音识别、自然语言处理和语音合成。语音识别涉及预处理、解码等步骤,自然语言处理包括理解用户意图和执行操作,而语音合成就将文本转化为语音输出。智能座舱中的语音交互系统通过硬件层、服务层、应用层和运营管理平台四个部分协同工作,提高了驾驶安全性与便利性。
一.什么是语音交互
语音交互:语音是方式,交互的对象是任何的智能设备,顾名思义,即通过语音的方式完成人与机的交互。
在现今的各种智能化场景中,语音交互已成为一种非常关键的人机交互方式。从用户的角度来看,语音交互的核心价值主要体现在释放用户的双手,使得人与机之间的交互变的更高效便捷。
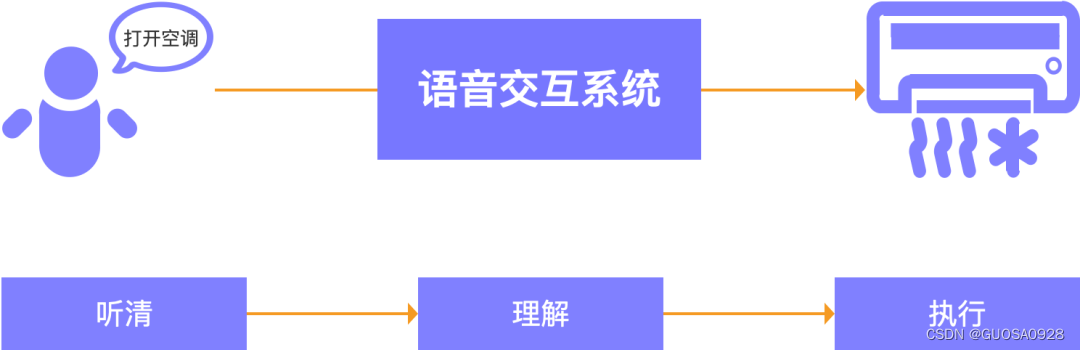
然而,从用户发出语音指令到实现与智能设备的交互,其过程并不像其名词描述的那么简单,要实现通过语音来完成人机交互,要解决解决三个关键问题,如何让机器听清用户的语音内容?如何机器理解用户的意图?如何让机器执行用户的意图?,解决这些问题的的过程是复杂的,其背后涉及到多个复杂的技术环节,如语音识别、自然语言理解、对话管理、自然语言生成、语音合成等。
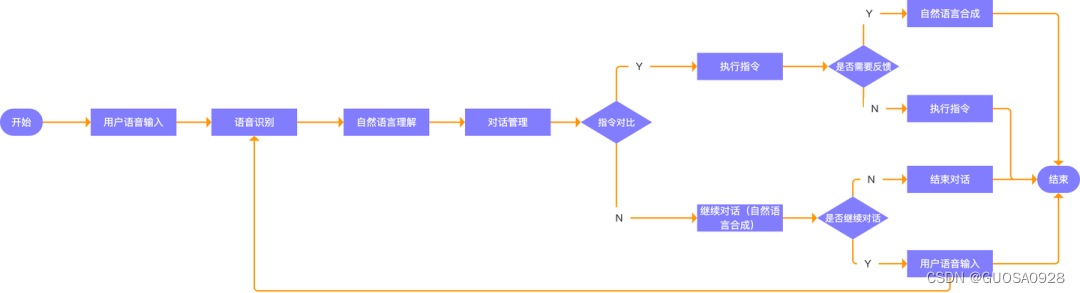
二.语音交互的底层技术
(一).语音识别
在语音交互系统中,用户的语音信号需要经过多个处理阶段才能得出正确的结果,而语音识别是实现语音交互的第一步,其在语音交互系统中负责对用户的语音信号进行前置处理,通过对用户语音信息的预处理、解码等关键任务,最终得到语音信号对应的文本内容,从而实现机器听清的用户的语音内容。
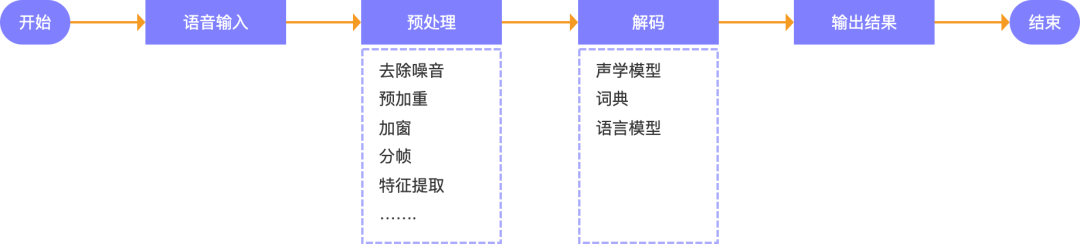
1.语音输入:用户通过麦克风输入内容语音,例如:打开空调
2.预处理:预处理是语音识别过程中的一个基础性步骤,它的意义在于对录音文件进行分帧、去除噪音、语音增强、加窗等预处理,提取出有效的声音特征,用于后续的语音内容分析处理。
-
去除噪音:由于用户环境因素影响,MIC设备录制的声音,除了人声,可能还会包各种噪音,那么为了语音识别的准确性,在识别前就需要先处理掉原始音频中的噪音部分。 去除噪音的实现过程大体可以理解为:首先提取原始音频中声音的频率、时域、能量等特征,通过对这些特征的对比分析区分原始音频中的人声和其他声音,然后通过滤波、降噪算法(基于频域的傅里叶变换、小波变换,或者基于时域的信号平滑法)等手段,实现去除噪声的目标。
-
预加重:在语音输入的过程中,由于环境和距离等影响因素,MIC录制声音可能会出现高频衰减和低频增益等失真现象,这将会影响后续语音识别的结果。
例如:用户的语音内容为“apple”,由于高频信号被衰减掉,录制的声音中可能只留下了“p”和“l”的较强信号,这将导致语音识别系统误认为说的是“pl”而不是“apple”。 针对这种现象,预加重通过加强高频成分的能量和减少低频成分的能量,让不同频率的音频信号能够在信号处理过程中均衡化,从而提高语音识别的准确性。
为了更形象的理解“预加重”,可以将其类比于在图像中的“锐化”,使得边缘更为清晰。
-
分帧:原始语音信号是一个连续的波形,是一种时间和频率上都变化较快的信号,在语音识别的过程中,如直接对连续且长的语音进行计算处理,会增加计算的难度降低识别的准确性。因此,为了提高语言识别结果的准备性,需要将连续且长的语音信号分为若干个固定长度的帧,分帧后每帧内的信号的频谱变化就会较为缓慢、稳定。
例如:以“打开空调”为例,假设录制的语音时长为2秒,采样率为16000Hz,那么原始语音信号就是一个长度为32000的一维向量,如果直接对这个声音信息进行语音识别,计算量会非常大,而且由于语音信号的频率和幅度变化非常快,很难进行有效的特征提取。
-
特征提取:完成去噪、预加重、分帧等前端处理后的语音信号,不能直接用于识别,还需要将其变换到频域,然后利用线性预测倒谱系数(L
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5915
5915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









