 本地部署DeepSeek-R1-671B大模型教程
本地部署DeepSeek-R1-671B大模型教程




DeepSeek-R1大模型具备深度思考和推理能力,在数学、代码、自然语言推理等任务上都有着极大的提升。一方面由于官方或第三方的在线服务或多或少存在不稳定的问题,另一方面考虑到数据安全和隐私问题,本地私有化部署DeepSeek开源大模型对个人或企业来说也是一种不错的选择。本文主要介绍完整参数版本 deepseek-r1-671b 模型的部署和测试过程,对 deepseek-v3-671b 以及其他更小参数版本的模型同样适用。
前言
DeepSeek-R1 模型的最大参数版本是 671B (6710亿参数),同时提供 1.5B ~ 70B的小参数蒸馏版本,可根据机器资源选择适合的模型版本。选择的依据主要看显存的大小,一般来说我们需要至少能支持把整个模型文件都加载到显存中,才能完全发挥GPU的计算能力,保证一定的运行速度。
ollama 是一个模型管理的开源框架,可以通过这个工具下载、运行、管理大模型。ollama是目前最简单的本地运行大模型的开源框架,也是本文中使用的框架。在 ollama 的模型仓库中可以查看不同模型需要占用的空间大小:
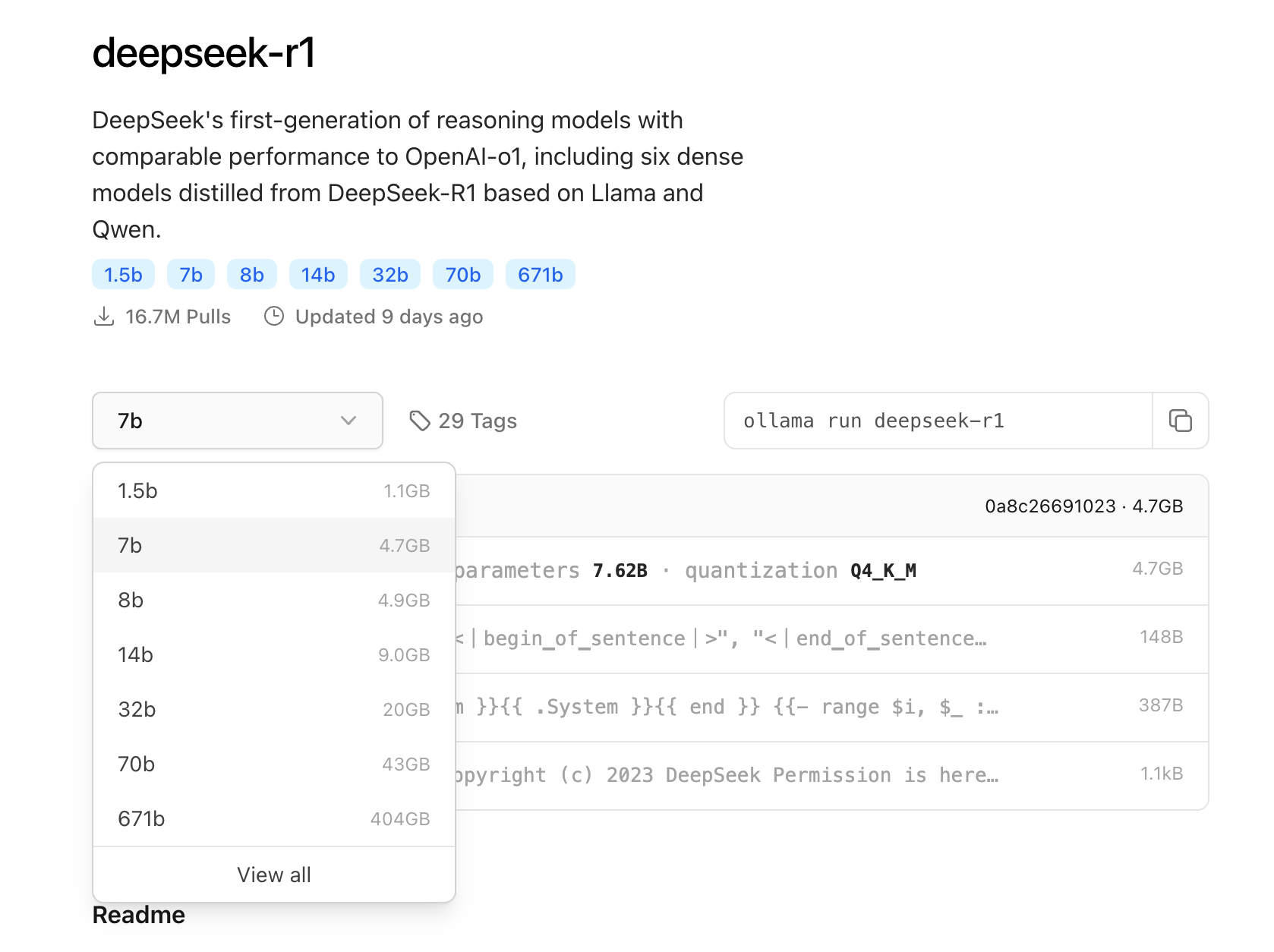
ollama 中的模型默认是经过 INT4量化的,即通过略微损失一定精度来压缩模型文件的大小。根据图中不同参数的模型大小可以看出 1.5b ~ 32b 模型都是有可能在个人电脑中部署运行的。
1.5b模型基本可以在大部分个人电脑甚至手机中运行,如果你有 6G 显存以上,那么可以部署7b模型,如果有16G显存,可以尝试14b的模型。而对于32b的模型,则需要24G显存的显卡,例如 3090 / 4090 系列;70B模型,则需要至少2张24G显存的显卡。 如果显存资源不足但内存足够,也可以尝试运行,只不过会使用CPU+GPU混合推理的模式,运行速度相比单纯的GPU模式会下降很多。
注:DeepSeek提供的1.5B ~ 70B的小参数R1模型是通过"蒸馏"产生的。蒸馏是一个知识迁移的过程,以其他开源模型(如qwen、llama)作为基座,用DeepSeek-R1大模型对这些模型进行训练,让这些参数较小的模型学习R1的生成结果、思考过程等,在显著降低模型参数规模的同时能保留一定的性能和精度。
准备
DeepSeek-R1的官方满血版精度为FP8,总大小大概在700G左右,Ollama提供的量化版本大小为 404GB,我们选择使用8块A800显卡来运行该模型,总显存为640GB,在能装下全部模型的情况下还为长上下文情况预留一定空间。
1.环境准备
硬件环境如下:
- GPU:8 * A800 (至少需要6卡)
- 显存:8 * 80G
- vCPU:112核
- 内存:224G
软件环境如下:
- 操作系统:ubuntu 20.04
- PyTorch:2.6.0
- CUDA:12.2
- ollama:最新版本
linux环境下在终端执行 nvidia-smi 可查看显卡信息:

成本:单张 A100/A800 显卡购买价格预估在10万元左右,在线上租赁平台租用的价格大概在 5元/小时/卡 左右。如果对性能有更高要求,还有 H100/H800、H20 等显卡可选择。
2.Ollama 安装
前往 ollama官网 下载并安装ollama,支持windows、MacOS、Linux。linux下需在终端运行命令:
curl -fsSL https://ollama.com/install.sh | sh
安装完成后运行 ollama -v 能看到版本信息则表示运行成功。
运行
1. ollama环境变量配置
在运行 olllama 服务前需要提前设置一些环境变量,下载的模型保存路径默认为 ~/.ollama/models,如果需要修改这个路径 (例如想保存在服务器的数据盘而非系统盘),则执行以下命令可以修改,将路径改为你需要保存的实际路径即可:
export OLLAMA_MODELS=/datadisk
另外还有几个重要的环境变量在运行671b这样的大参数模型时很有帮助,建议进行配置:
export OLLAMA_DEBUG=1 # 开启debug日志,用于查看模型加载的进度和错误信息
export OLLAMA_LOAD_TIMEOUT=120m # 加载模型的超时时间,默认为5分钟。避免加载超时退出
export OLLAMA_KEEP_ALIVE=-1 # 默认为5分钟,表示模型运行后5min未访问就会自动卸载。-1表示常驻显存
export OLLAMA_SCHED_SPREAD=1 # 多卡时需要,在多个GPU上均匀调度模型推理
Ollama默认的并发为1,即每一个请求处理完成才会执行下一个请求,如果需要提升并发可以设置:
export OLLAMA_NUM_PARALLEL=8 # 支持并发运行的请求数,默认为1,可根据剩余显存空间设置
但 OLLAMA_NUM_PARALLEL 的设置一定要根据可用的显存空间来,每一个额外的并发都会消耗一定的显存空间,设置太高会导致加载模型直接失败 (例如报错 insufficient VRAM to load any model layers、model request too large for system),或者在运行时导致ollama崩溃退出。
在上述8卡A800的环境中,671B模型基础占用为400G+,OLLAMA_LOAD_TIMEOUT 设置为1时,显存占用为420G左右;设置为8时,显存占用为 500+G; 设置为16时,已经开始使用CPU混合推理了,说明占用已经超过了 640G。大致可以估算出来,每新增一个并发配置,就需要额外 10~15G的显存空间;设置为32时,会在加载模型时直接失败。
在运行大参数模型时需要注意:
- 以上环境变量只是临时修改,需要在每次ollama运行前运行,且终端关闭后就会失效,如果需要永久生效可以在环境变量文件 (如 ~/.bashrc) 中进行修改。
OLLAMA_LOAD_TIMEOUT如果设置太小,可能无法完成加载就超时退出OLLAMA_KEEP_ALIVE需设置为-1才能常驻显存,否则超过一定时间就会被释放OLLAMA_NUM_PARALLEL需根据显存资源情况设置,太高会导致加载失败或显存溢出
2.运行 Ollama
执行以下命令运行 ollama:
nohup ollama serve &
因为这里是在linux服务器上运行,为了防止远程连接断开后ollama服务就退出了,则使用 nohup + & 指令让服务在后台长期运行,ollama 服务启动后默认监听 11434 端口。
使用 tail -f nohup.out 可以查看ollama服务运行日志,通过 ps -ef|grep ollama 命令可以查看ollama进程,使用 kill -9 <进程id> 的方式可以关闭ollama进程。
3.下载模型
执行命令下载模型:
ollama pull deepseek-r1:671b
671b量化模型总体积为400G,下载速率取决于服务器带宽以及Ollama模型仓库的带宽,假设下载速率为20m/s,大概需要 5小时左右。注意在下载过程中,如果遇到速度大幅下降的情况,可以输入 CTRL+C 终止后重新运行下载命令,会从当前进度处继续下载,并恢复原有速度。
下载完成后执行 ollama ls 可以在列表中看到该模型:

4.运行模型
由于模型运行前需要从磁盘加载到显存中,对于大参数模型需要较长时间,所以我们同样使用nohup将模型运行的命令放在后台运行,避免终端关闭后退出:
nohup ollama run deepseek-r1:671b > run.out 2>&1 < /dev/null &
执行 tail -f run.out 可以查看请求端的日志,运行 tail -f nohup.out 可以查看 ollama 服务端的日志。在服务端日志中可以看到ollama将模型加载到显存的过程,日志中会展示当前加载的百分比 model load progress 0.xx。
由于 671B模型比较大,这一加载的过程可能需要 1个小时以上的时间,加载完成后可以看到日志输出:
model load progress 1.00
llama runner started in 3770.15 seconds
执行 ollama ps 可以查看到运行的模型实例:

PROCESSOR 显示 100% GPU表示完全使用GPU进行计算。
使用
1.命令行对话
再次输入模型运行指令可以进入交互命令行:
ollama run deepseek-r1:671b
输入问题即可获取模型答案,在 标签之间为模型深度思考的内容:

2.接口调用
ollama 服务运行后会监听 0.0.0.0:11434,我们可以通过API接口访问运行后的模型实例。ollama的对话接口兼容openai接口,可以执行以下命令调用模型接口:
curl --request POST \
--url http://127.0.0.1:11434/v1/chat/completions \
--header 'Content-Type: application/json;charset=utf-8' \
--data '{
"model": "deepseek-r1:671b",
"messages": [
{
"role": "user",
"content": "你是什么模型"
}
]
}'
3.性能压测
对 deepseek-r1-671b 模型进行压力测试。大模型的性能评估方式比较特殊,请求的耗时是和响应的token长度正相关的,回复内容越长则耗时越久,所以不能单独使用并发数量或耗时这一个指标来定义,而是使用"在某一并发下的tokens生成速率"来进行评估。
我们通过编写一个python脚本来进行压测,脚本的核心逻辑是使用多线程模拟并发用户,同时请求模型API,根据响应的tokens数量 和 响应耗时,计算出平均每个请求的每秒生成tokens数量,即 tokens/s/req。
根据需求修改脚本文件 model_stress_test.py 中的模型地址、并发数量等配置项,运行 python3 model_stress_test.py 即可启动压测脚本:
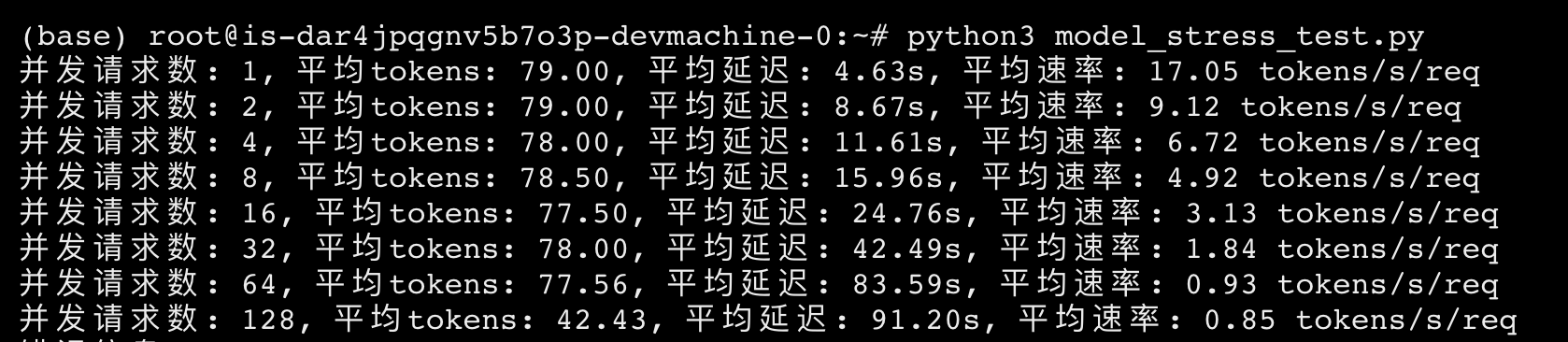
请求的问题内容为 “你是什么模型”,运行结果如下,当并发数超过128时,平均单个请求的响应时间已经超过了180s,可用性大大下降:
| 并发请求数 | 平均速率 (tokens/s/req) |
|---|---|
| 1 | 17.05 |
| 2 | 9.12 |
| 4 | 6.72 |
| 8 | 4.92 |
| 16 | 3.13 |
| 32 | 1.84 |
| 64 | 0.93 |
| 128 | 0.85 |
执行 nvitop 可以查看GPU的实时使用情况:
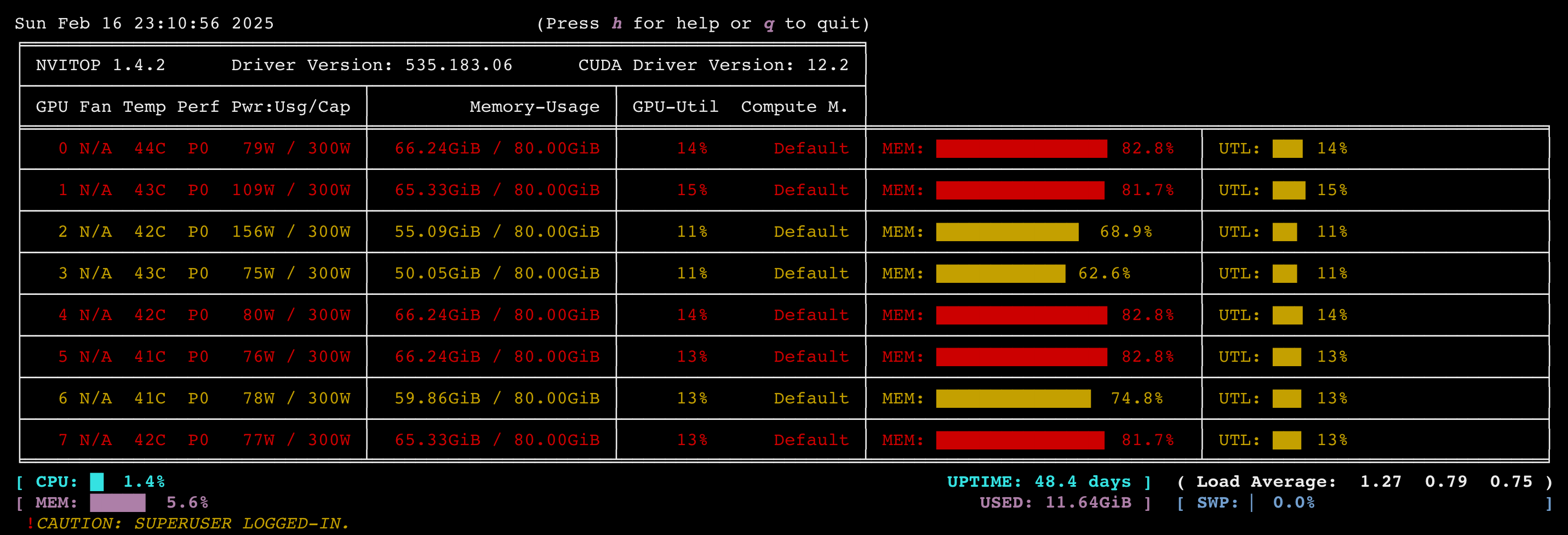
可以看出即使是在 128 并发时,GPU的平均利用率只有不到 15%,还有很大提升空间。考虑是 ollama 框架本身的性能问题,或者是相关配置需要调优,后续会继续性能优化,以及尝试其他高性能推理框架例如 vllm 等。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

DeepSeek全套安装部署资料

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 2440
2440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









