






前言
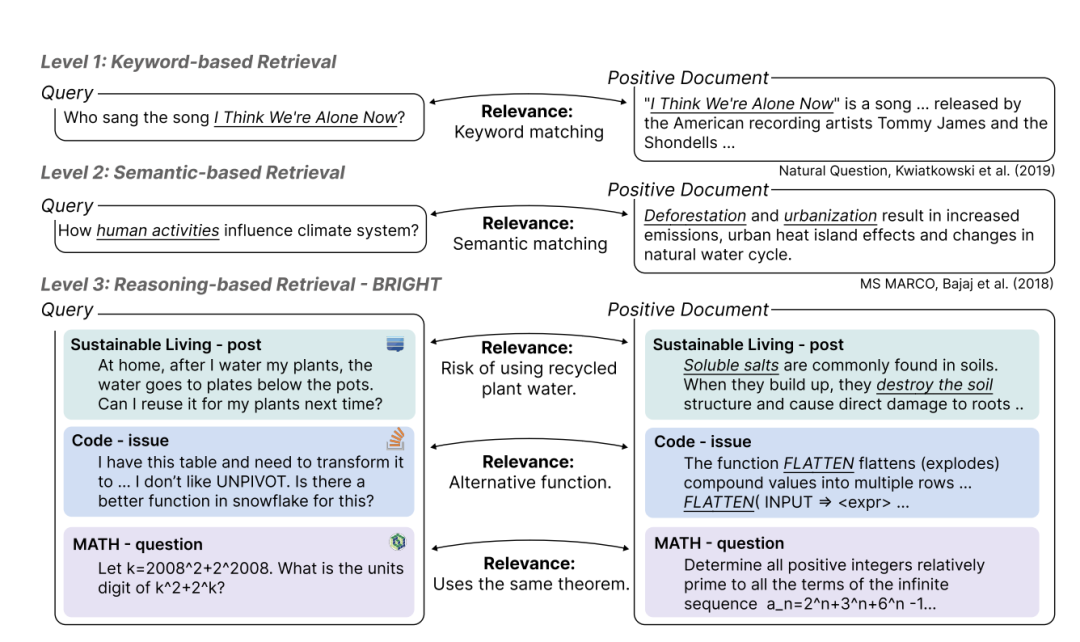
最近看到一个很有意思的研究,说的是信息检索的三个层次:
- Level 1: 关键词检索- 匹配相同的词
- Level 2: 语义检索- 理解词的含义
- Level 3: 推理检索- 需要逻辑思考才能找到答案
今天就跟大家聊聊这个"推理检索"到底是什么鬼,以及最新的一些进展。
什么是推理信息检索?
简单来说,推理信息检索就是需要动脑子思考才能找到相关信息的能力,而不是简单地匹配关键词或者理解语义。
举个例子,假设我问:
“家里给植物浇水后,盘子里的积水可以重复使用吗?对植物有害吗?”
一个真正能推理的检索系统会明白:
- 盘子里的水含有溶解的矿物质
- 这些可能包括肥料中的可溶性盐分
- 需要找关于盐分积累和根部损伤的文档
- 即使这些文档从来没提过"重复使用盘子里的水"这个说法
这就是推理检索的厉害之处 - 它能理解问题背后的逻辑,而不只是字面意思。
现有检索可能失败?
最近有个叫BRIGHT的基准测试,专门用来测试这种推理检索能力。测试结果让人大跌眼镜:
- 在MTEB排行榜上拿59分的顶级模型
- 在BRIGHT上只能拿18分
- 这差距也太大了吧!
这说明什么?现在的检索系统在面对需要推理的复杂问题时,基本上是一头雾水。
来自论文:https://arxiv.org/pdf/2407.12883
新的救星:Reason-ModernColBERT
就在最近,LightOn团队发布了Reason-ModernColBERT模型,在BRIGHT基准测试上取得了不错的成绩。虽然只有1.5亿参数,但效果相当不错。
实际测试效果如何?
笔者拿了三个文档来测试:
文档1(高度相关):讲可溶性盐分的危害
容器植物中的可溶性盐分会在水分蒸发后积累,重复使用排水会让盐分浓度升高,
难以让植物吸收水分。高盐分会直接损伤根部,导致叶尖发黄、萎蔫等问题。
最好的做法是倒掉托盘里的水,不要重复使用。
文档2(不相关但有迷惑性):讲节水园艺
节水园艺对可持续发展很重要。包括覆盖减少蒸发、选择耐旱植物、
收集雨水等技术。滴灌系统能直接给根部供水,减少浪费。
这些方法能减少50%的用水量。
文档3(有些相关):基础浇水指南
大多数室内植物在土壤表面干燥时需要浇水。
要彻底浇透直到底部排水孔流出水,然后30分钟后倒掉托盘积水防止烂根。
不同植物需求不同,多肉需要少水,热带植物喜欢土壤保持湿润。
测试结果
使用原始问题查询:
- 文档1(最相关):得分 -82.11
- 文档3(有些相关):得分 -78.09
- 文档2(不相关):得分 -69.92
排序完全正确!即使文档2里"水"这个词出现了很多次,但模型还是能准确识别出真正相关的文档。
加上推理过程效果更好
如果在查询中加上推理过程:
用户想知道重复使用植物排水是否安全。
关键问题是理解水通过土壤后会发生什么。
可能含有溶解的矿物质和肥料中的盐分。
需要找关于矿物质积累、盐浓度对植物影响的信息...
结果得分差距更大:
- 文档1:-97.82(相关性更高)
- 文档3:-83.31
- 文档2:-79.71
技术实现细节
Reason-ModernColBERT使用了多向量架构,每个文档不是用单一向量表示,而是用多个向量的集合。这样能更好地捕捉文档的不同方面。
在Weaviate中的使用也很简单:
reasoning = """
The user wants to know if reusing plant drainage water is safe.
The key issue is understanding what happens to water after it passes through soil.
It likely contains dissolved minerals and salts from fertilizers.
We need to find information about mineral buildup, salt concentration effects on plants, and whether reused water can harm plant roots through excessive salt accumulation.
"""
将推理过程和查询问题拼接,完整代码可以查看:
https://github.com/weaviate/recipes/blob/main/weaviate-features/multi-vector/reason_moderncolbert.ipynb
response = collection.query.near_vector(
near_vector=model.encode((query + reasoning), is_query=True), # Raw embedding, in [[e11, e12, e13, ...], [e21, e22, e23, ...], ...] shape
target_vector="multi_vector",
return_metadata=weaviate.classes.query.MetadataQuery(
distance=True,
),
)
for result in response.objects:
print(result.properties)
print(result.metadata.distance)
BRIGHT基准测试收集了1398个真实世界的复杂查询,涵盖经济学、心理学、机器人学、软件工程等多个领域。
为什么现有模型表现这么差?
主要原因是现有的检索基准测试太简单了,都是一些直接的信息查询,用关键词或语义匹配就够了。但现实世界的问题往往需要:
- 逻辑推理- 理解问题背后的原理
- 知识连接- 将不同概念联系起来
- 深层理解- 不只是表面的词汇匹配
真实案例分析
比如编程问题:要找到某个函数的文档,不仅需要知道函数名,还要理解代码的逻辑和语法结构。
再比如数学问题:要找到相关的定理证明,需要理解数学概念之间的逻辑关系。
对RAG系统的影响
这项研究对检索增强生成(RAG)系统有重要意义:
传统RAG的问题
- 检索到的文档质量不高
- 无法处理复杂的推理问题
- 生成的答案缺乏逻辑性
推理检索的改进
- 能找到真正相关的背景知识
- 支持复杂问题的回答
- 提高答案的准确性和可信度
结语
推理信息检索代表了搜索技术的一个重要发展方向。虽然目前的模型表现还不够完美,但Reason-ModernColBERT等新模型已经展现了很大的潜力。
随着技术的不断发展,我们期待看到更多能够真正"理解"用户问题的智能检索系统。这不仅会改变我们获取信息的方式,也会推动人工智能向更高层次的推理能力发展。
毕竟,真正的智能不应该只是记住很多信息,而是要知道如何思考和推理。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 321
321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









