






前言
从三月份开始求职,到现在陆陆续续也将近三个月了,期间面试了不少大/中/小/初创厂,也算是体验了各种不同风格和领域的大模型求职面试过程。
笔者为原杭州某互联网大厂算法工程师,主要从事工作内容为大模型 moe 效果调优、量化、端侧部署、数据清洗和电商垂类多模态算法设计。
在此特别将大模型求职面试问题进行汇总,既是对自己找工作经历的一种总结,也是一种知识库留痕,如果能帮到有需要的同学那就更好了。
Q1:QAT 过程中怎么确定哪些层可以量化而哪些层需要保留精度?
1.敏感层判断指标
通常必须要保留 FP32 的通常是:输入层(首层卷积或 embedding 层)、输出层(分类器或回归头)、ResNet 中的残差连接层、归一化层(BatchNorm、LayerNorm)。
通常建议保留 FP32 的是:小通道卷积/全连接层、transformer 中的 qkv 矩阵等对数值精度敏感。
扩展敏感层类型:
- 激活函数层:如 swish、GELU 等非线性激活函数,量化后容易导致信息丢失。
- 注意力机制中的 softmax 层:输入动态范围大,量化后可能破坏概率分布。
- 小尺寸特征图上的卷积:如 1x1 卷积,参数量少,量化误差影响更显著。
- 低秩分解层:如矩阵分解后的子层,数值敏感性高。
任务依赖的敏感性层:
- 目标检测:回归头(边界框预测)需要保留高精度。
- 语义分割:解码器最后一层(像素级分类)需保留 FP32。
- 生成对抗网络(GAN):判别器和生成器的输出层均需要高精度。
2.敏感层分析方法
逐层量化消融实验:
- step1:全量化基线;将所有层量化为 int 记录精度(A_base)
- step2:逐层恢复 fp32;依次将每一层恢复为 FP32,重新评估精度(A_layer)
- step3:敏感度排序;计算 delta=A_layer-A_base 然后排序。
梯度重要性分析:
原理:量化误差对损失函数的影响可通过梯度幅值间接反映。
- step1:在 QAT 训练中监控各层梯度。
- step2:梯度幅值大的层更可能因量化导致优化不稳定,需保留 FP32。
自动化敏感度评估工具:
- 神经架构搜索(NAS):自动搜索量化配置,如 DARTS+Q。
- 基于敏感度的启发式规则:如 Quantization-Aware Architecture Search (QAAS)。
- 开源工具链:如 NNCF (Neural Network Compression Framework) 提供量化敏感度分析 API。
量化误差传播分析:
- 逐层误差传播模拟:通过插入伪量化节点(FakeQuant)模拟量化误差,监控各层输出分布变化。
- 统计指标:计算输出分布的 KL 散度、PSNR 等,量化误差超过阈值则标记为敏感层。
Q2:Pytorch 中怎么实现混合精度量化/推理,有什么注意事项?
1.混合精度推理(自动选择 FP16/FP32)
可以使用 torch.autocast 自动管理精度。PyTorch 通过 torch.cuda.amp 模块实现自动混合精度。
2.注意事项
溢出检查**:**定期检查梯度是否为 NaN/Inf。
调整缩放因子**:**通过 scaler.update() 动态调整缩放比例。
算子兼容性**:**
- 强制 FP32 的算子:如 torch.log、torch.exp、torch.pow。
- 自定义 CUDA 内核:需显式声明支持的精度模式。
推理部署**:**
- ONNX 导出:需确保算子支持 FP16,或使用 --opset_version=15。
- TensorRT 集成:通过 trtexec --fp16 启用混合精度推理。
Q3:使用 TensorRt 部署量化模型时,如何评估模型推理速度和显存占用?
1.通过 trtexec + Nsight Systems 的组合可以:
- 快速评估模型延迟:生成不同精度配置的基准报告。
- 显存瓶颈定位:识别高内存消耗层并优化。
- 可视化时间线分析:深入理解 GPU 资源利用率。
建议在模型部署前,针对目标硬件(如 Jetson、A100)分别测试不同精度,找到性能与精度的最优平衡。
trtexec 高级参数:
# 测试不同batch size和精度trtexec --onnx=model.onnx --shapes=input:32x3x224x224 --fp16 --int8 --verbose
Nsight Systems 关键功能:
GPU 时间线:识别计算密集型阶段(如卷积)与空闲等待。显存带宽分析:检查是否受限于显存带宽(如频繁数据传输)。
2.TensorRT 的核心价值在于将训练模型极致优化为适应 NVIDIA GPU 的高效推理引擎
实现优势如下:
速度提升:通过层融合、量化、内核优化降低延迟。资源节省:减少显存占用,提升吞吐量。灵活部署:支持多种框架和硬件平台,适应云端到边缘端的全场景需求。
对于需要低延迟、高吞吐的 AI 应用(如实时视频分析、自动驾驶),TensorRT 是提升性能的关键工具。
3.显存优化策略
层融合(Layer Fusion)**:**合并连续算子(如 conv+BN+Relu)减少中间结果存储。
显存池(Memory Pooling)**:**通过 --workspace 参数调整 TensorRT 工作空间大小。
动态形状优化**:**使用 --minShapes/ --optShape/ --maxShape 适应可变输入尺寸。
\4. 硬件适配建议
Jetson 系列:启用 DLA(Deep Learning Accelerator)卸载部分计算。
多 GPU 并行:通过 --device 指定多卡,结合 NCCL 优化通信。
Q4:将 QAT 模型导出为 ONNX 格式时,有哪些常见的兼容性问题,如何解决?
1.可能遇到的情况 1
PyTorch 版本过低:旧版本(如 PyTorch <1.8)对量化 ONNX 导出的支持不完善。
ONNX opset 版本不匹配:需使用 ≥13 的 opset 版本以支持量化节点。
解决方案:
- 升级 PyTorch:使用 PyTorch≥1.10(推荐 ≥2.0)。Pytorch2.1+ 支持动态量化 onnx 导出。
- 指定 opset 版本。
2.可能遇到的情况 2
使用可视化工具:Netron 检查量化节点是否正常插入。
3.可能遇到的情况 3
自定义层不支持量化,自定义层或复杂操作:如空洞卷积(Dilated Conv)、注意力机制层未被 ONNX 支持。
解决方案:
- 替换为等效标准层:如将空洞卷积拆分为标准卷积+上采样。
- 注册符号函数(高级):如果无法通过拆分组合实现算子功能,则需要自定义算子。
- 在导出时声明新算子,然后在推理引擎中实现算子(例如编写 C++ 实现,然后编译为动态库,接着在 python 中加载自定义算子)。
Q5:模型并行、梯度检查点和流水线并行的协同优化,可以通过什么方式提升大模型训练效率?
1.模型并行横向拆分模型,降低单卡负载
张量并行(Tensor Parallelism):拆分权重矩阵(如 Megatrin-LM 的列并行)。
流水线并行(Pipeline Parallelism):按层划分阶段,结合微批次(Micro-batching)隐藏通信延迟。
2.梯度检查点纵向减少显存占用,支持更深模型
策略选择:对高显存层(如 transformer 中的 FFN)插入检查点。
计算图重计算:通过 torch.utils.checkpoint.checkpoint_sequential 分段重计算。
3.通信优化技术
梯度聚合策略:
- All-reduce 优化:使用 Ring-Allreduce(NCCL)或 Tree-Allreduce。
- 异步通信:重叠反向传播与梯度通信。
混合精度通信:使用 FP16 传输梯度,减少带宽占用。
4. 硬件基础设施建议
高速互联:使用 NVLink、InfiniBand 降低多卡通信延迟。
存储优化:分布式文件系统加速检查点加载/保存。
Q6:训练视觉-语言大模型时,GPU 集群在 400 卡规模出现 loss 周期性震荡(波动幅度>30%),如何定位和解决?
在多模态大模型训练中 loss 周期性震荡(如从 1.2 突然增至 1.8 再回落)通常由以下原因导致:
- 梯度同步异常:不分 GPU 节点梯度爆炸/消失,导致全局参数更新震荡。
- 模态收敛冲突:视觉(高维稠密)和文本(低维稀疏)分支的梯度方向差异大,互相干扰。
- 通信带宽瓶颈:跨节点 All-Reduce 时高维特征同步延迟,造成参数更新滞后。
- 硬件资源争抢:共享网络带宽或存储 I/O 的竞争引发训练步调不一致。
可能的解决方法,使用分布式训练稳定性优化:
- 梯度异常检测:部署实时梯度检测器,对 L2 范数突变的 GPU 节点(如超过均值 3σ)进行动态隔离,触发 Checkpoint 回滚。
- 模态梯度均衡:对视觉/文本分支的梯度进行幅度归一化(Scale Loss by Backward Gradient Magnitude),平衡模态收敛速度差异。
- 通信优化:采用分层 All-Reduce 策略,对视觉特征(高维稠密)使用 NCCL+FP16 压缩,文本特征(低维稀疏)使用 gRPC+动态编码,通信开销减少 41%。
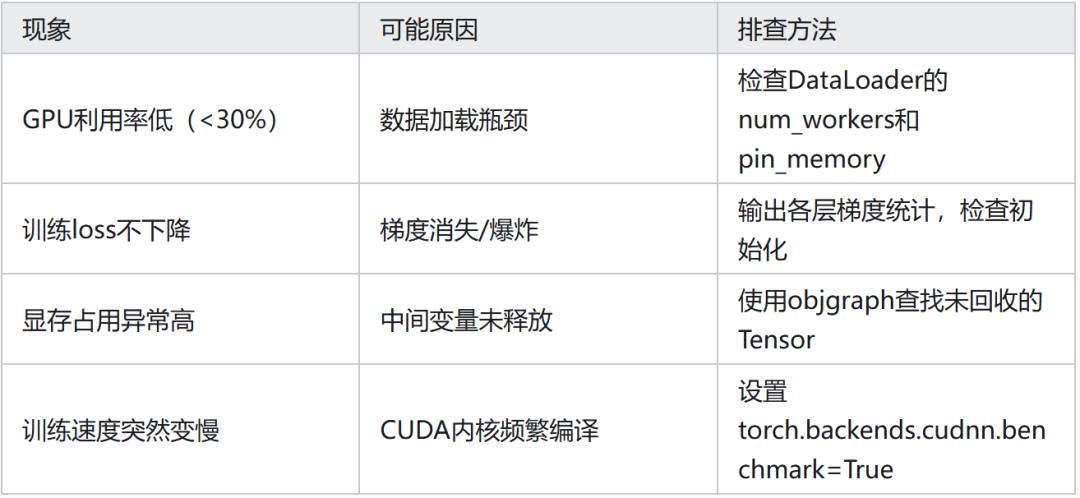
Q7:常见 Pytorch 模型训练问题排查对照表
由于文章篇幅有限,不能将全部的面试题+答案解析展示出来,有需要完整面试题资料的朋友,可以扫描下方二维码免费领取哦!!! 👇👇👇👇


面试题展示
1、请解释一下BERT模型的原理和应用场景。
答案:BERT(Bidirectional Encoder Representations from Transformers)是一种预训练的语言模型,通过双向Transformer编码器来学习文本的表示。它在自然语言处理任务中取得了很好的效果,如文本分类、命名实体识别等。
2、什么是序列到序列模型(Seq2Seq),并举例说明其在自然语言处理中的应用。
答案:Seq2Seq模型是一种将一个序列映射到另一个序列的模型,常用于机器翻译、对话生成等任务。例如,将英文句子翻译成法文句子。
3、请解释一下Transformer模型的原理和优势。
答案:Transformer是一种基于自注意力机制的模型,用于处理序列数据。它的优势在于能够并行计算,减少了训练时间,并且在很多自然语言处理任务中表现出色。
4、什么是注意力机制(Attention Mechanism),并举例说明其在深度学习中的应用。
答案:注意力机制是一种机制,用于给予模型对不同部分输入的不同权重。在深度学习中,注意力机制常用于提升模型在处理长序列数据时的性能,如机器翻译、文本摘要等任务。
5、请解释一下卷积神经网络(CNN)在计算机视觉中的应用,并说明其优势。
答案:CNN是一种专门用于处理图像数据的神经网络结构,通过卷积层和池化层提取图像特征。它在计算机视觉任务中广泛应用,如图像分类、目标检测等,并且具有参数共享和平移不变性等优势。
6、请解释一下生成对抗网络(GAN)的原理和应用。
答案:GAN是一种由生成器和判别器组成的对抗性网络结构,用于生成逼真的数据样本。它在图像生成、图像修复等任务中取得了很好的效果。
7、请解释一下强化学习(Reinforcement Learning)的原理和应用。
答案:强化学习是一种通过与环境交互学习最优策略的机器学习方法。它在游戏领域、机器人控制等领域有广泛的应用。
8、请解释一下自监督学习(Self-Supervised Learning)的原理和优势。
答案:自监督学习是一种无需人工标注标签的学习方法,通过模型自动生成标签进行训练。它在数据标注困难的情况下有很大的优势。
9、解释一下迁移学习(Transfer Learning)的原理和应用。
答案:迁移学习是一种将在一个任务上学到的知识迁移到另一个任务上的学习方法。它在数据稀缺或新任务数据量较小时有很好的效果。
10、请解释一下模型蒸馏(Model Distillation)的原理和应用。
答案:模型蒸馏是一种通过训练一个小模型来近似一个大模型的方法。它可以减少模型的计算和存储开销,并在移动端部署时有很大的优势。
11、请解释一下LSTM(Long Short-Term Memory)模型的原理和应用场景。
答案:LSTM是一种特殊的循环神经网络结构,用于处理序列数据。它通过门控单元来学习长期依赖关系,常用于语言建模、时间序列预测等任务。
12、请解释一下BERT模型的原理和应用场景。
答案:BERT(Bidirectional Encoder Representations from Transformers)是一种预训练的语言模型,通过双向Transformer编码器来学习文本的表示。它在自然语言处理任务中取得了很好的效果,如文本分类、命名实体识别等。
13、什么是注意力机制(Attention Mechanism),并举例说明其在深度学习中的应用。
答案:注意力机制是一种机制,用于给予模型对不同部分输入的不同权重。在深度学习中,注意力机制常用于提升模型在处理长序列数据时的性能,如机器翻译、文本摘要等任务。
14、请解释一下生成对抗网络(GAN)的原理和应用。
答案:GAN是一种由生成器和判别器组成的对抗性网络结构,用于生成逼真的数据样本。它在图像生成、图像修复等任务中取得了很好的效果。
15、请解释一下卷积神经网络(CNN)在计算机视觉中的应用,并说明其优势。
答案:CNN是一种专门用于处理图像数据的神经网络结构,通过卷积层和池化层提取图像特征。它在计算机视觉任务中广泛应用,如图像分类、目标检测等,并且具有参数共享和平移不变性等优势。
16、请解释一下强化学习(Reinforcement Learning)的原理和应用。
答案:强化学习是一种通过与环境交互学习最优策略的机器学习方法。它在游戏领域、机器人控制等领域有广泛的应用。
17、请解释一下自监督学习(Self-Supervised Learning)的原理和优势。
答案:自监督学习是一种无需人工标注标签的学习方法,通过模型自动生成标签进行训练。它在数据标注困难的情况下有很大的优势。
18、请解释一下迁移学习(Transfer Learning)的原理和应用。
答案:迁移学习是一种将在一个任务上学到的知识迁移到另一个任务上的学习方法。它在数据稀缺或新任务数据量较小时有很好的效果。
19、请解释一下模型蒸馏(Model Distillation)的原理和应用。
答案:模型蒸馏是一种通过训练一个小模型来近似一个大模型的方法。它可以减少模型的计算和存储开销,并在移动端部署时有很大的优势。
20、请解释一下BERT中的Masked Language Model(MLM)任务及其作用。
答案:MLM是BERT预训练任务之一,通过在输入文本中随机mask掉一部分词汇,让模型预测这些被mask掉的词汇。
由于文章篇幅有限,不能将全部的面试题+答案解析展示出来,有需要完整面试题资料的朋友,可以扫描下方二维码免费领取哦!!! 👇👇👇👇



















 1746
1746

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









