







 本文介绍了如何使用精确率、召回率及F1分数等指标评估分类模型的性能,通过实例讲解了这些指标的计算方法,并对比了它们与准确率的区别。
本文介绍了如何使用精确率、召回率及F1分数等指标评估分类模型的性能,通过实例讲解了这些指标的计算方法,并对比了它们与准确率的区别。
准确率
在聊精确率、召回率之前,一般我们会看模型预测的准确率,即所有预测正确样本数/样本总数。
但分类准确度不能完全衡量模型好坏。
比如一个癌症预测系统,输入体征信息,判断是否有癌症。如果癌症在人类身上发生的概率为0.1%,那模型只要都判断没有癌症,即可达到99.9%的准确率。
如果去训练机器学习模型,但是最后准确率有99%,但其实这个模型还是失败的,即使这个模型什么都不做,完全输出无癌症,依然能有99.9%的准确率。
所以对于极度偏斜的数据,只使用分类准确度是不能完全衡量一个模型的好坏的。
接下来将介绍精确率和准确率指标,但之前先引入一个概念:混淆矩阵
混淆矩阵
0-Negative
1-Positive
行代表真实值,列代表预测值
| 真实\预测 | 0-Negative | 1-Positive |
|---|---|---|
| 0-Negative | 预测Negative正确TN(True Negative) | 预测Positive错误FP(False Positive) |
| 1-Positive | 预测Negative错误FN(False Negative) | 预测Positive正确TP(True Positive) |
例:10000个人进行癌症预测,1-患病 0-不患病
| 真实\预测 | 0 | 1 |
|---|---|---|
| 0 | 9978 | 12 |
| 1 | 2 | 8 |
10000个人中:
1)TN:9978人实际未患病,算法评估未患病
2)FP:12个人实际未患病,算法评估患病
3)FN:2个人实际患病,算法评估未患病
4)TP:8个人实际患病,算法评估患病
精确率&召回率
精确率 precision = TP/(TP + FP)
精确率 = 8/(8+12) = 40%
即预测数据为Positive中,预测正确的比例
在上述癌症预测案例中,即100次患病预测中,40%预测为正确的
召回率 recall = TP/(TP + FN)
召回率 = 8/(8+2) = 80%
事件positive真实发生并且被正确预测的比例
在上述癌症预测案例中,即10个已患病的病人中,80%的人能被算法模型预测为患病
为什么精确率召回率优于准确率
假设还是癌症预测系统对10000个人进行预测。癌症发病率为0.1%(即有10人为患病),模型无论什么输入,都输出未得癌症。则我们可以获得如下混淆矩阵。
| 真实\预测 | 0 | 1 |
|---|---|---|
| 0 | 9990 | 0 |
| 1 | 10 | 0 |
此时准确率 = (9990 + 0)/10000 = 99.9%
精确率 = 0 / (0 + 0) 无意义
召回率 = 0/(0 + 10) = 0%
通过精确率和召回率发现这个模型的表现是非常差的。
F1 score
那么计算出了精确率和召回率,到底该用哪个指标呢?到底哪个指标高才能说明一个模型效果好呢?
答案是需要具体情况具体分析。
例子1:我们做出一个股票预测模型,按照上述混淆矩阵中0为预测跌,1为预测涨,那么我们希望尽可能少的出现FP(实际是跌但是预测涨)的错误,但是对于出现FN(实际是涨但是预测跌)错误的情况,我们没有那么关注,所以在这个模型中我们更关注精确率。
例子2:癌症监测模型,定义0为未患病,1为患病。那么我们希望尽可能少的出现FN(实际患病但是预测未患病),但是对于FP(实际未患病但是预测患病)的错误是可以容忍的,所以在这个模型中我们更关注召回率。
虽然实际中不是所有模型都像上面两个例子中这么决定,大部分模型要综合参考精确率和召回率的值。由此引入f1 score指标。
f1 score 是精确率和召回率的调和平均数
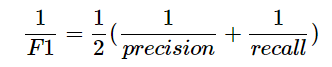
整理一下:

只有当精确率和召回率二者都非常高的时候,它们的调和平均才会高。如果其中之一很低,调和平均就会被拉得接近于那个很低的数。
F1 socre的值域是在(0,1]之间。
混淆矩阵,精确率,召回率,f1score的sklearn实现
先构建一个偏斜的数据集,这里采用sklearn中的digits手写数据集。digits里面的特征是64的像素,不同像素中存的是颜色深度,结果是0-9这10个数字。
from sklearn import datasets
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression,LogisticRegression
from sklearn.model_selection import train_test_split
digits = datasets.load_digits()
X = digits.data
y = digits.target.copy()
y[digits.target == 9] = 1
y[digits.target != 9] = 0
print(np.count_nonzero(y==1))
print(np.count_nonzero(y==0))
为了构建偏斜数据,将y中所有等于9的数字置为“1”,将不等于9的数字置为“0”。最后看到y中等于1的有180个样本,等于0的有1617个样本。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=666)
将原X,y进行拆分,一部分当做训练数据集供模型进行训练,一部分当做测试数据集,当模型训练好了之后输入测试数据集的数据去评估模型效果。
log_reg = LogisticRegression() #构建逻辑回归模型
log_reg.fit(X_train,y_train) #使用训练数据集训练模型
y_predict = log_reg.predict(X_test) #将测试数据传入训练好的模型中,让模型预测测试数据的结果
print(log_reg.score(X_test,y_test)) #基于预测的结果和测试数据中实际的结果打印准确率0.9755555555555555
下面看下sklearn包中封装好的混淆矩阵、精确率和召回率的计算
from sklearn.metrics import confusion_matrix,precision_score,recall_score,f1_score
confusion_matrix = confusion_matrix(y_test,y_predict)
precision_score = precision_score(y_test,y_predict)
recall_score = recall_score(y_test,y_predict)
f1_score = f1_score(y_test,y_predict)
结果如下:
混淆矩阵
[[403 2]
[ 9 36]]
精确率:0.9473684210526315
召回率:0.8
f1 score: 0.8674698795180723
准确率:0.9755555555555555
由此可见f1 score综合反映了精确率和召回率的情况。
通过f1score(0.86)来评估一个分类模型比准确率(0.97)更客观。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









