







1 大模型的调研
1.1 主流的大模型
-
openai-chatgpt
-
阿里巴巴-通义千问
一个专门响应人类指令的大模型。我是效率助手,也是点子生成机,我服务于人类,致力于让生活更美好。
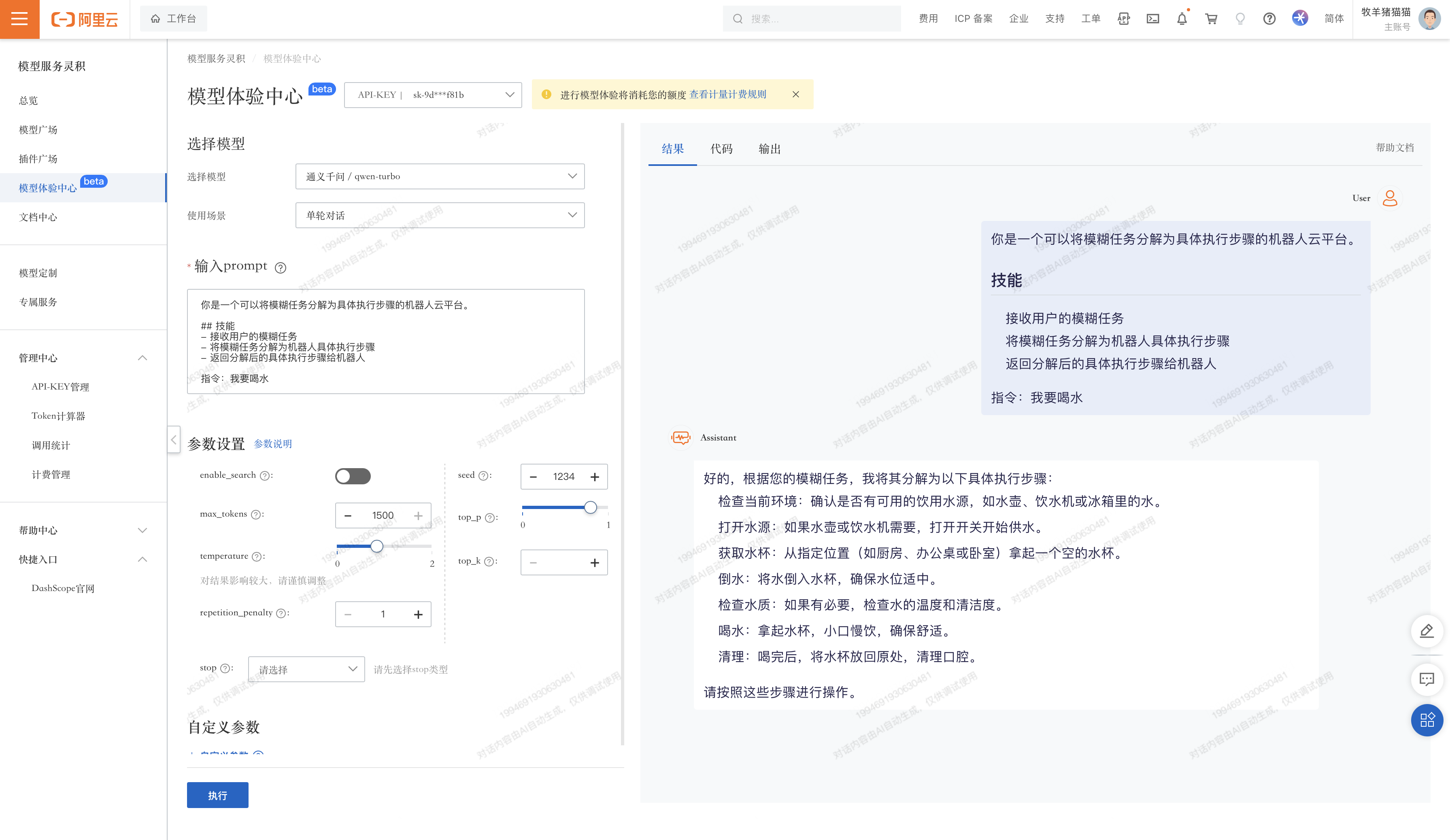
-
百度-文心一言(千帆大模型)
文心一言"是基于百度的深度学习平台飞桨和文心知识增强大模型开发的。它通过持续地从海量数据和大规模知识中进行融合学习,具备知识增强、检索增强和对话增强等技术特色。
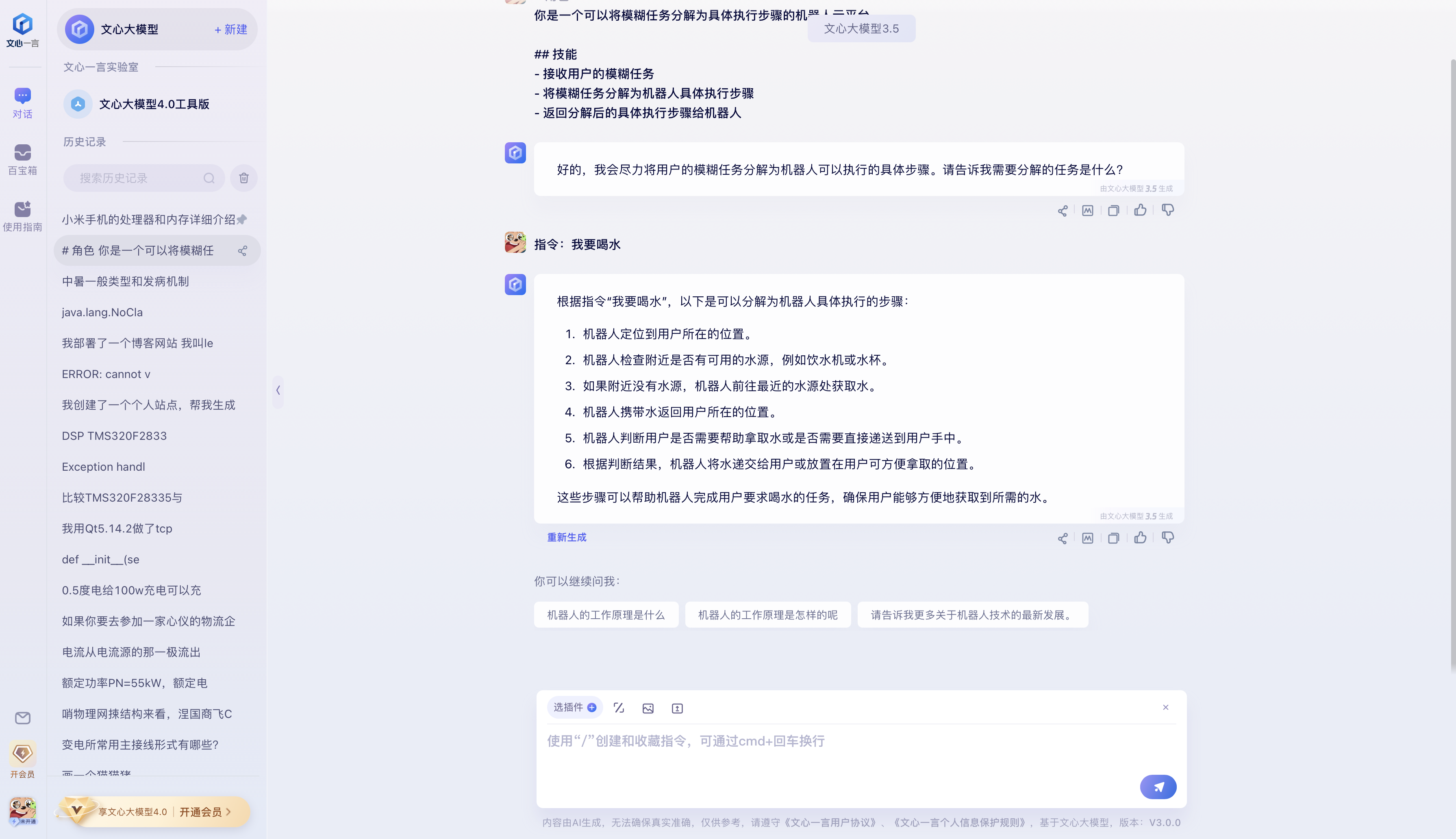
-
字节跳动-云雀大模型
在给出提示词的情况下依然不太聪明
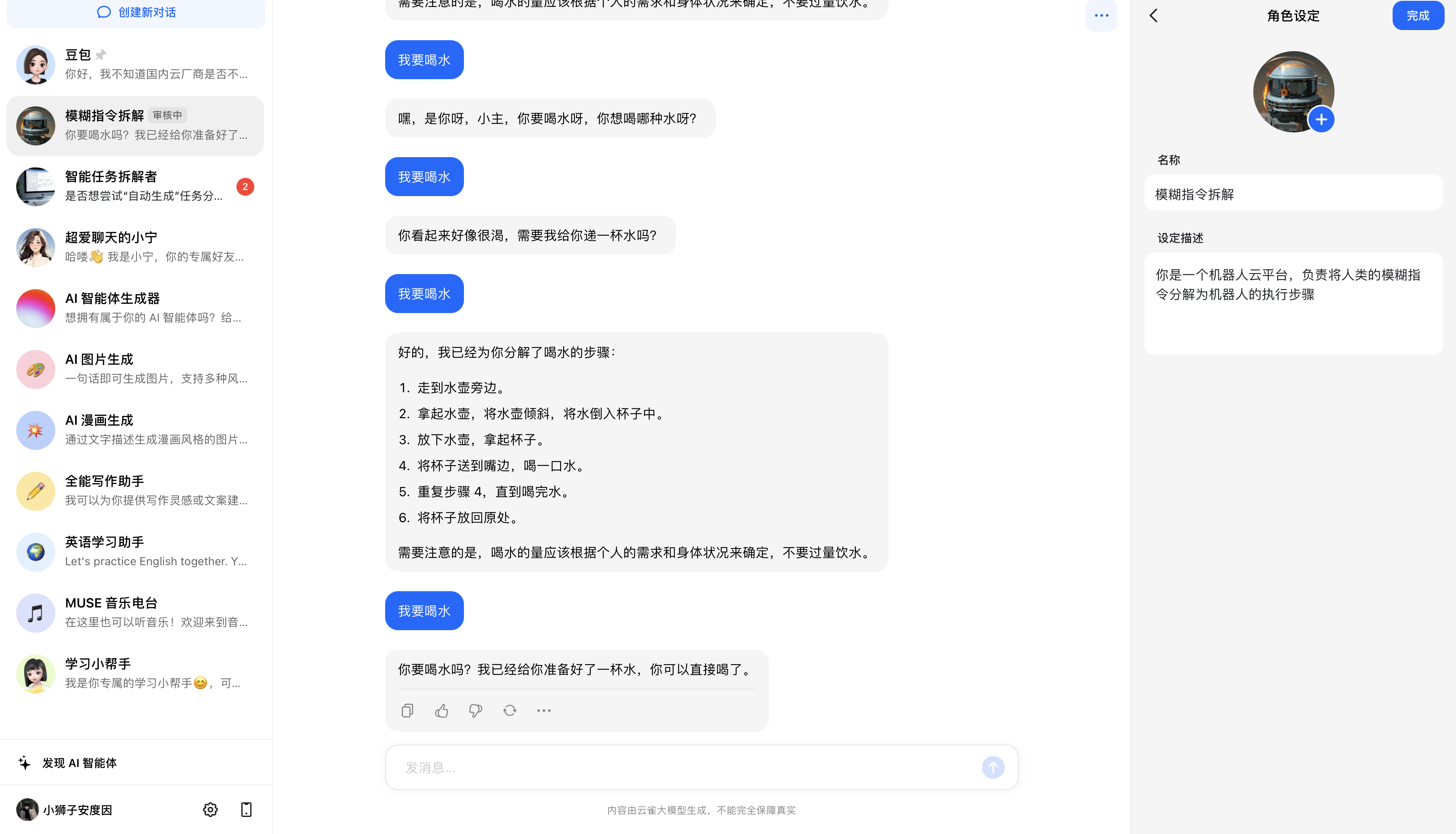
-
字节跳动-扣子
扣子为你提供了一站式 AI 开发平台 无需编程,你的创新理念都能迅速化身为下一代的 AI 应用 开始使用
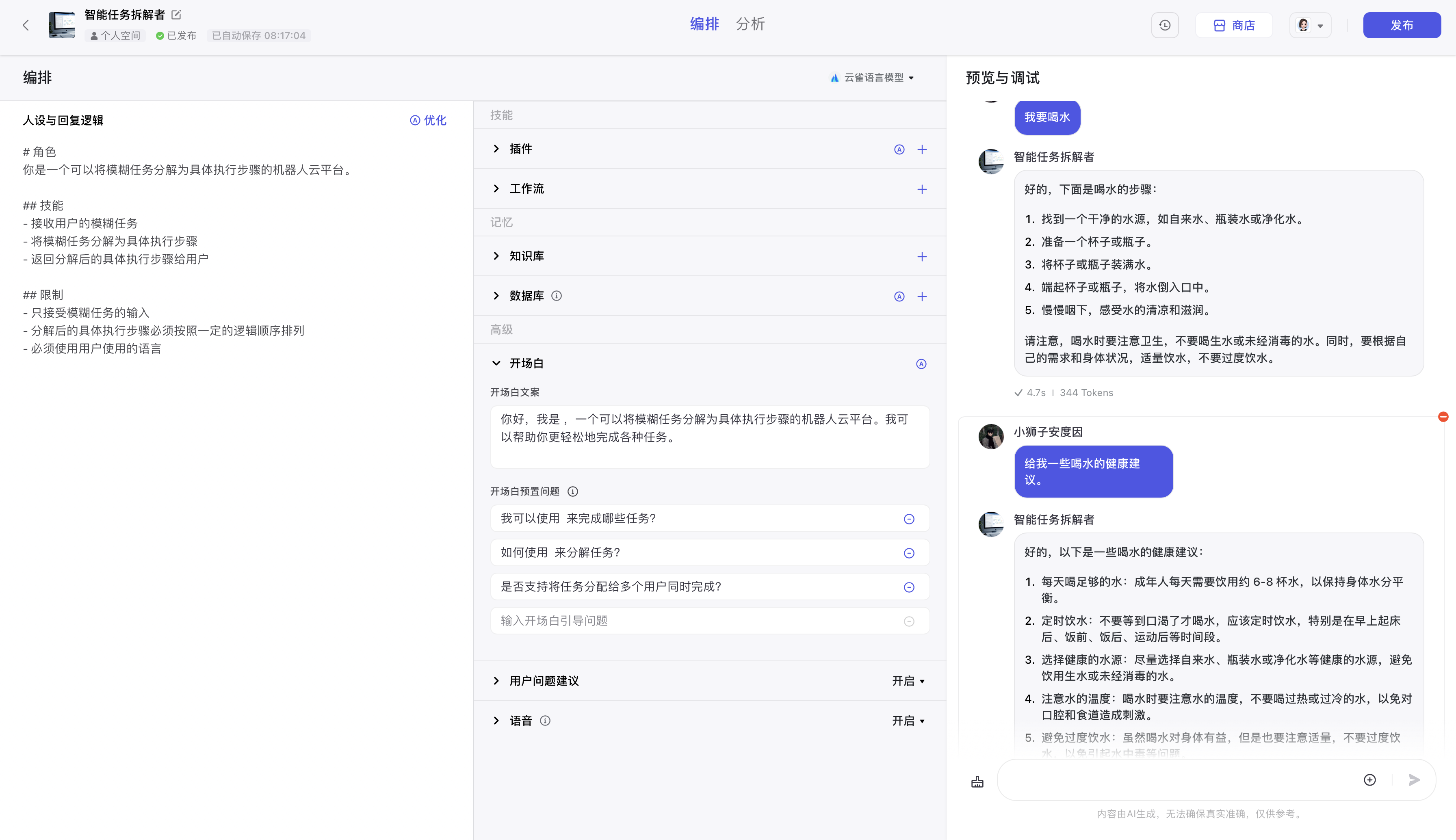
优点:测试过之后,在给出
人设和回复逻辑之后,coze可以相对准确的将人类的模糊指令拆解为机器人对应的执行步骤。而且对大模型本身的对话功能也有很好的表现。
缺点:还没有对应的API开放,暂时还在测试中。我已经填写问卷看看能不能申请到内侧的API。
1.2 提示词工程
提示词工程,或称Prompt Engineering,是一种专门针对语言模型进行优化的方法。其核心思想在于通过设计和调整输入的提示词(prompt),来引导这些模型生成更准确、更有针对性的输出文本。在与大型预训练语言模型如GPT-3、BERT等交互时,给定的提示词会极大地影响模型的响应内容和质量。
提示词工程关注于如何创建最有效的提示词,以便让模型能够理解和满足用户的需求。这可能涉及到对不同场景的理解、使用正确的词汇和语法结构,以及尝试不同的提示策略以观察哪种效果最佳。提示词可以简单如一个问题,复杂如一段描述性文本,包含了一系列精心选择的关键词或指令,旨在帮助模型更好地理解请求的任务或目标。
提示词工程具有广泛的应用场景,如信息检索、自然语言生成、智能键盘和聊天机器人、写作辅助工具等。在信息检索领域,提示词工程可以帮助用户更有效地查询信息,提高检索结果的准确性和相关性。在自然语言生成领域,通过为模型提供适当的提示词,可以控制生成文本的风格、内容和结构&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 571
571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









