






 本文探讨了通过引入隐变量来简化复杂多元高斯分布的方法。当隐变量取不同值时,变量x,y服从不同的二维高斯分布,从而将原本复杂的3元混合高斯分布分解为更易处理的形式。此外,还讨论了隐变量的不同状态对应于不同区域点的密度,即隐变量的分布。
本文探讨了通过引入隐变量来简化复杂多元高斯分布的方法。当隐变量取不同值时,变量x,y服从不同的二维高斯分布,从而将原本复杂的3元混合高斯分布分解为更易处理的形式。此外,还讨论了隐变量的不同状态对应于不同区域点的密度,即隐变量的分布。
假如有
x
,
y
x,y
x,y服从如下分布关系: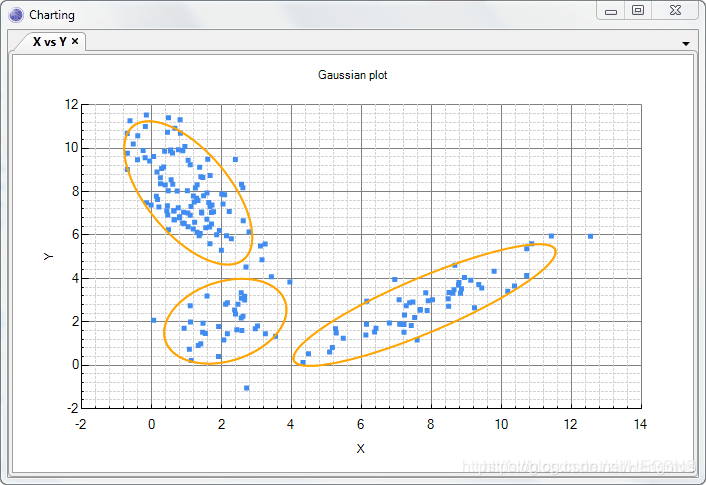
看起来像是3元混合高斯分布,比较复杂。
如果我们再引入隐变量 z z z,使得 z = z 1 z = z_1 z=z1时, x , y ∼ N ( μ 1 , Σ 1 ) x, y \sim N(\mu_1, \Sigma_1) x,y∼N(μ1,Σ1); z = z 2 z = z_2 z=z2时, x , y ∼ N ( μ 2 , Σ 2 ) x, y \sim N(\mu_2, \Sigma_2) x,y∼N(μ2,Σ2); z = z 3 z = z_3 z=z3时, x , y ∼ N ( μ 3 , Σ 3 ) x, y \sim N(\mu_3, \Sigma_3) x,y∼N(μ3,Σ3)。问题就变得简单多了。
而从图中可以看出每个区域点的密度也不一样,这对应隐变量 z z z的分布,即 P ( z = z i ) = p i P(z = z_i) = p_i P(z=zi)=pi。

















 93
93

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









