




目录
1. 图形学CLIPasso: Semantically-Aware Object Sketching
1.3 如何摆脱对有监督训练数据集的依赖,去哪儿找能把一个图像的语义信息抽取得特别好的模型?CLIP
1.5 主体方法:计算机图形学的文章是怎么用CLIP 模型的
2.视频CLIP4Clip: An Empirical Study of CLIP for End to End yideo Clip Retrieval
1、Multi model framework 到底有没有用
初始化视觉编码器:How much can clip benefit vision-and-language tasks?
语音:Audioclip: Extending clip to image, text and audio
3D:Pointclip: Point cloud understanding by clip
理解深度信息:Can language understand depth?
1. 图形学CLIPasso: Semantically-Aware Object Sketching
今天我们就接着上次没有讲完的这个 CLIP 的一些后续延展工作,接着来看一下 CLIP 还能用在别的什么领域。虽然上次我就提到了 CLIP puzzle 这篇论文,说他获得了 CGRAPH 的最佳论文奖,但因为时间原因,上次只说了 CLIP 在这个分割和检测里的应用。那今天我们就先来看一下。CLIP puzzle。
1.1 目的:minimum representation
那打开论文,其实第一眼就看到这个图一了。不用看论文,我们也大概知道这篇工作可能就是想把一个这个真实的图片,然后一步一步变成后面这种简笔画的形式。然后我们又看到了毕加索画的这幅画,所以其实立马就意识到这个 CLIP puzzle 就是 clip 和这个毕加索的这个合体。

那题目接起来说, semantically aware object sketching。就是保持语义信息的这种物体的素描。那为什么加上这个semantically aware?是因为作者觉得这种简笔画这种素描其实是非常难的,尤其是对于计算机来说,因为它不光要把这个真实的物体变成一个非常简单的这么一个形象。而且还要确保这个观众能看出来这个简笔画到底描述的是什么物体,它有没有抓住原来这个物体的一些最关键的那些特征。作者这里说他们想达到的目的。就是使用这种 minimum representation,就是最简单最简单的形式,可能就是画几条线,甚至只有一条线。它就能把这个物体表示出来。但是别人一定能够认出来这个物体,就是同时语义上和这个结构上都能识别出来这个物体才行。
那接下来作者为了更加形象的让大家明白他到底在做是一个什么问题,而且这个问题的难点到底在哪?所以他又用毕加索的这幅画做了一个阐述,这幅画的名字其实就是叫。一头公牛。 
这是一个系列了,就是从最开始的第一张图,然后一点,然后一直画到最后一张图,中间的过程可能有快一年。这个一头公牛的这个画作系列其实。非常著名。我在网上查了一下,上次 2015 年最高的这个拍卖价格已经到了 2 亿美金了。所以现在搞研究也真是很卷,不光想法要好,论文写得要好,你这还得懂艺术。
作者这里想展示给大家的其实就是说这个抽象是非常难以做到的,从最开始的这张画细节非常丰富,你如何能够一步一步把那些不必要的元素从这幅画里移掉,到最后的这种极简的形式,但是你还能识别出来它是一头公牛。这个就是这篇论文想做的事儿,他想给一个机器,只要提供了一张真实的这个照片,这个机器就能还给他一张最简形式的这个简笔画。
1.2 相关工作:抽象程度固定、形式风格受限
那这个任务既然这么困难,之前有没有工作去研究过这个方向?基本上任何一个你能想到的研究方向之前,多多少少都是会有一些相关工作的,那在这里也不例外。比如作者这里说的这几个方法就是文献3 25 30,但是作者说这几个方法都是怎么做的?他们其实都是去收集了一些数据集,比如这种 Sketch data set,就这种素描数据集,而且这个抽象程度也都是固定好的,比如说笔画很多不那么抽象,或者说笔画很少特别抽象,这些都是数据集里提前定义好的。有什么数据,那这种 data driven 的方式就会学到什么样的模型,这样最后生成的这种素描画,它的这种形式和这种风格就会非常的受限,这就违背了这个图像生成的初衷了。而且除了这个生成数据的这个风格问题之外,这种用固定的数据集还有一个劣势就是它的种类不能做到很丰富。尤其是已有的那些素描数据集,它的种类非常的有限。
作者这里也带图 4 做了一下简单的总结,在这个领域大概就有这么几个数据集,从一开始这种更偏重于几何的数据集,一直发展到最近的更偏重语义的数据集。
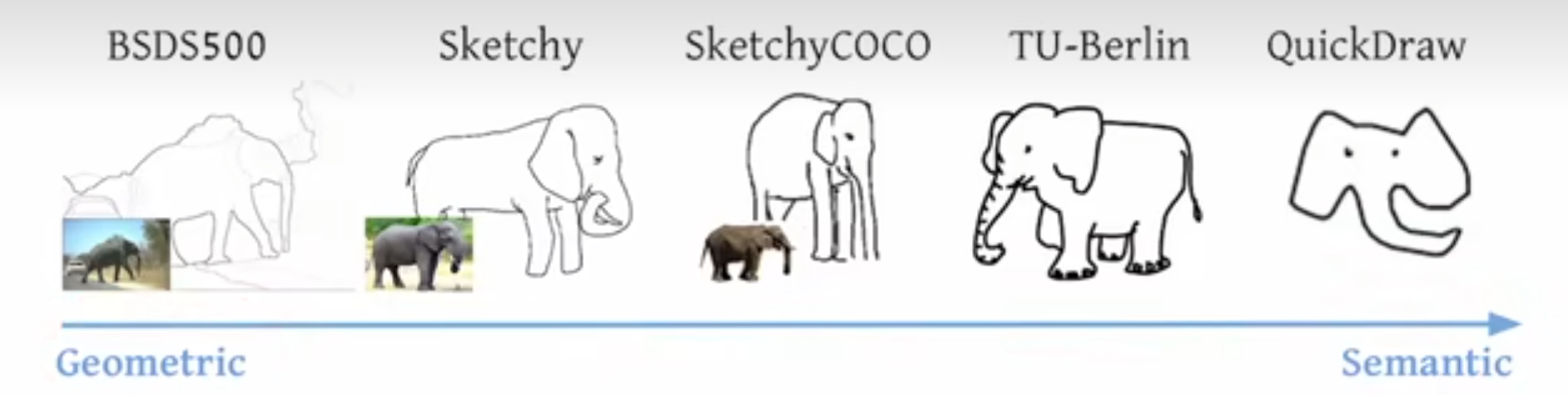
那举几个例子来说,比如最开始的这个 BSD 500 数据集,它其实就是一个分割的数据集,当然了它也不算是语义分割,它更多的是介于一种在这个边缘检测和语义分割中间的一个过程,就是有点像细粒度的这种分割。就像这里画的一样,它虽然把大象好像标记成整个一个物体了。但是旁边的这个树不光是一个物体,它中间还有很多这种树叶。树枝的这种纹理看起来仿佛像做了一个 edge detector,但是又是一个比较具备语义信息的 Ash Detector,属于最原始的分割了,当然这个数据集也是十几年前的数据集了
然后再往后发展就有了 Sketchy 数据集,然后基于这个 Sketchy 数据集又发展出了 Sketchy Coco数据集。但其实这个 Sketchy Coco 数据集里面只有9类,就是一些常见的动物,什么大象,然后还有一些汽车什么这种类别,非常的有限。
然后再往后发展到最新的这个 quick draw 数据集,这个其实是谷歌之前做的一个应用,就是你在它的网站上可以随意的去涂鸦,很短的时间内你画一个物体出来,然后他就把这些数据全都收集起来,做成了一个数据集。然后这整个数据集里有 5000 万个图像,但即使这么大的数据集其实也就 300 多类,所以它的类别数依旧是很受限制的。如果你在它上面训练了一个从真实图像到这种素描的模型,那它也就只能对这几个物体类别起作用,那其他的物体类别可能就还需要收集新的数据,然后再去做 fine tuning。
1.3 如何摆脱对有监督训练数据集的依赖,去哪儿找能把一个图像的语义信息抽取得特别好的模型?CLIP
那如何能够摆脱对这种有监督训练数据集的依赖,然后又去哪儿找能把一个图像的语义信息抽取得特别好的模型?那这两个问题一问出来,那其实对应的答案就只有一个,或者说最直接的答案就是 clip 模型。因为这种文本和语言配对的学习方式,所以它对物体特别的敏感,它对这种物体对语义信息抓取得非常好,而且它又有出色的这种 Zero shot 的能力,它完全不需要在下游的数据集上去做任何的微调,拿过来就能直接用。上一期我们已经在风格和检测里全都见识过了,都工作得非常好,所以在这里也不例外。作者直接就把CLIP运过来。于是就有了CLIP puzzle了。
能把 CLIP 用在这种场景下,让它能work,而且觉得这是一个可做的方向。其实并不像我刚才说的那样,直接问一个问题,你就有一个答案,你就知道 CLIP 就是最后的解决方案,这里面也需要前人的一些 insight 和积累,还有自己的一些改动。
那说到前人的积累,其实作者这里也说了,之所以使用clip,之所以clip,能够不管这个图像的风格,始终都能把这个物体的视觉特征都编码得非常好,也就是说它非常的稳健,它不会受这种图像分割的影响。也就是这篇文献 14 的这个观察才奠定了这篇工作的基础。因为毕竟之前你说 clip 好,那是因为 clip 始终工作的区域都是这种自然图像,不论是检测还是分割,你见的都是这种 RGB 的这种普通的图像。所以说 CLIP 模型迁移得很好,但是现在你是从一个图像迁移到简笔画,它就只有几个线条,剩下大部分区域全都是白色的。你怎么知道 clip 模型还能工作得很好?那其实这时候前人的工作 14 就给出了这个答案。这个文献 14 其实我非常推荐大家去看一下,它是发表在那个可视化的那个期刊 distill 上的作者花了很大的功夫去写,而且真是把 CLIP 的模型分析得特别的透彻,可视化做得特别的炫酷。而且要对模型的稳健性,对抗性攻击,还有 OCR 攻击,各种各样有趣的实验非常值得一读。
1.4 本文改进
那说完了前任工作对这篇工作的影响,那其实还有自己的一些改进,那这篇工作不仅是在训练方式上,还有在 lost 选择上,还有在这个简笔画的初始设置位置上,都有独到的贡献,所以才能达到这么惊艳的。最后的这种生成的效果,也就是作者在图 3 里展示的这些结果类。

Parcel 不光是能把一个图像变成任意一个简笔画,而且它能通过控制这种笔画的多少来实现这种不同层次的这个抽象?如果你给定的这个笔画多,它就不那么抽象,你还能看出来它是很好的一个花,然后长颈鹿什么的。但如果你把这个笔画不停地缩小缩减,到最后可能是有三四画的时候,它还是能够兼顾这个几何和语义性,给你画出一个 Semantic aware 的这个简笔画。
1.5 主体方法:计算机图形学的文章是怎么用CLIP 模型的
那介绍了这么多,接下来我们就来看一下文章的主体方法部分。看看一篇计算机图形学的文章是怎么用CLIP 模型的。
1.5.1 问题定义
那首先作者先定义了一下问题,他说他现在的任务其实就是在一张白纸上,然后画几个这个曲线,也就他这里说的这种贝塞尔或者贝兹曲线。然后这些曲线当然都是随机初始化的,然后通过这种不停地训练,他希望这些曲线最后就变成了这个简笔画。
那现在我们就来具体地看一下每一步是怎么完成的。首先我们说到了这个倍资曲线这个概念,倍资曲线其实是通过一系列的这个空间上二维的点控制的一个曲线。比如说你现在有这样的几个点,那它可能就定义了这么一个曲线。如果用数学表达式来说,每一个曲线这个 SI 它用 s 的原因是 Stroke 的缩写,就是笔画。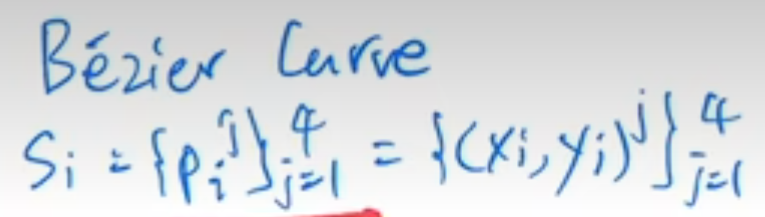 在这篇文章里,一个笔画它用了四个点去控制,所以是 1- 4四个点。然后每一个点在空间上是一个二维的,所以是有一个 x 值,有一个 y 值,所以也就是说你这四个点控制了这个曲线,然后你通过这个模型的训练,你去更改这四个点的位置,然后通过倍资曲线的计算,你就能慢慢改变这条曲线的形状,最后变成你想要的简笔画的形式。那至于更深入地对倍资曲线的讨论,或者说怎么用这些点去控制生成这个倍资曲线,这些都是图形学那边的事情了,我这里就不过多介绍。
在这篇文章里,一个笔画它用了四个点去控制,所以是 1- 4四个点。然后每一个点在空间上是一个二维的,所以是有一个 x 值,有一个 y 值,所以也就是说你这四个点控制了这个曲线,然后你通过这个模型的训练,你去更改这四个点的位置,然后通过倍资曲线的计算,你就能慢慢改变这条曲线的形状,最后变成你想要的简笔画的形式。那至于更深入地对倍资曲线的讨论,或者说怎么用这些点去控制生成这个倍资曲线,这些都是图形学那边的事情了,我这里就不过多介绍。
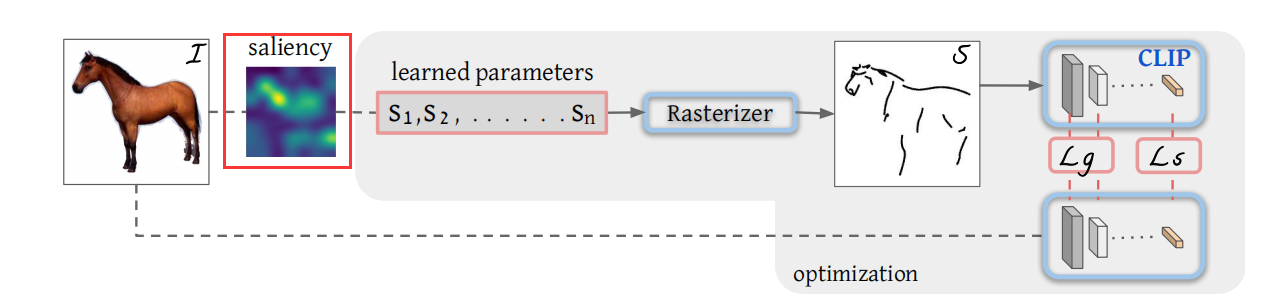
然后假设说我们现在在一个空白的纸上已经定义了这几个曲线,也就这里说的 S1 到 SN 就是 n 个笔画,然后作者就把这 n 个笔画扔给了一个光栅化器 restrizer,他就能把这些笔画到这个二维的这个画布上,变成一个我们能看懂的图像。然后这里的这个光栅化器其实是一个可导的,而且就是用的图形学那边已有的一个工作没有做任何的改动。所以也就是说整个这一部分是没有任何 contribution 的。
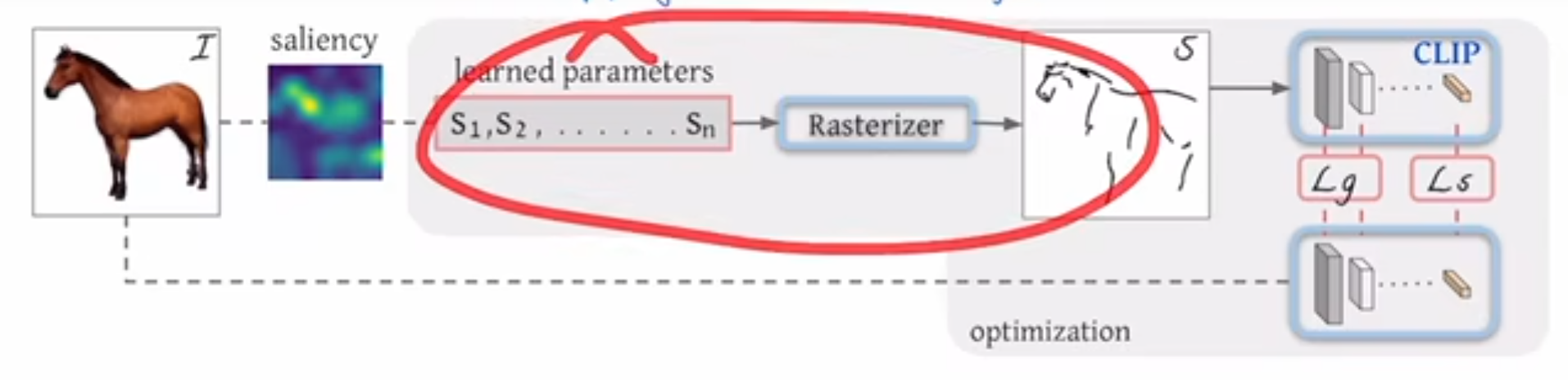
这篇文章主要的 contribution 就在前面和后面,就是前面如何去做一个更好的初始化,后面如何选择一个更合适的 loss function
1.5.2 两个目标函数
那我们现在先按照文章的一个顺序说一下这个目标函数,那我们现在得到的模型的输出,也就是这里这个不太像马的这个简笔画之后,我们肯定是要算一些这个目标函数,然后再回去更新一些参数的。
那我们这里的 ground truth 是什么呢?或者说我们能选一个什么样的这个目标函数?这里其实就是 clip 模型发挥作用的地方,就跟之前我们讲目标检测里的 ViLD一样,它其实就是把 clip 模型当做了一个teacher,然后用它还去蒸馏自己的模型,去把 CLIP 模型里已有的那些概念都学过来。这里面大概就是这个意思,它就借助了我们之前讲过的 CLIP 模型的这个稳健性,就是不论对这种原始的好的这个图像,还是对后面的这个简笔画图像。如果他们描述的都是同一个物体,比如说是马。那它通过这个 CLIP 模型最后得到的这个特征,那它应该都是对马这个物体的描述,他们应该相差不远,八九不离十。所以这个时候我就应该让这两个特征尽可能的接近,于是乎第一个这个目标函数就出来了,也就他这里说的这个LS,也就是 Semantic loss,就是这种基于语义性的一个目标函数,它就是希望这种简笔画生成的特征和原始图像生成的特征尽可能的接近,那这个确实很好想了。但是这里还有一个问题,就是如果你只是保证它的这个语义接近,那还是会出很多问题。比如说你这里生成的简笔画,比如说码头,如果在这边怎么办?它最后编码出来其实还是码,但是这就不是你想要的那种简笔画,因为和你的原始输入图像不匹配了。
也就是说我们除了这个语义上的这个限制之外,我们还应该在这个几何形状上也对这个模型的输出做一些限制,这也就是作者这里提出的第二个目标函数,就这个基于 geometric 的目标函数,具体来说就是作者借鉴了之前一些 low level 视觉里的一些任务者,说那些衡量指标像 perceptual loss 一样,它是把模型前面几层的输出拿出来去算这个目标函数。我们拿最简单的 Resnet 50 做例子的话, Resnet 50 有四个阶段, RES 2345,它现在的意思其实就是把 REST 234 这些层的这个特征拿出来去算loss,而不是用最后的那个 2048 维的特征去算,这样子因为前面的这些特征它还有长宽的这个概念,所以说它对几何的这种位置更加的敏感。那用这种特征去算 loss 就能最大程度上保证这种几何形状,然后这种物体的朝向这种的一致性,那这篇文章里,其实这个 LG 就是在 clip 预训练的模型,比如说什么 rise 50、 rise 101 的前几层去算这两个图像不同层之间这个特征的相似性。那尽可能地让它们也保持一致。
这样在这两个目标函数的齐心协力的作用下,就能保证最后生成的这个简笔画,无论是在几何形状上、位置上跟原有的图像尽可能的一致,而且在语义信息上也能尽可能的保持一致。
1.6 初始化方法
所以到这里作者已经能够非常愉快地生成各种各样的图片了。但是经过很多张图片的生成之后,作者发现这个被资曲线的这个初始化就是最开始的一个点,放在那其实是很有讲究的,不同的初始化会带来很不一样的生成效果,有的生成的简笔画就又简单又好看,有的生成的简笔画那个语义信息就还是恢复不了,甚至就是一团糟。那这个时候作者就想得有一个比较稳定的这个初始化方式,才能让这个方法变得更普适,而且更加容易让大家去复现。所以这里作者又提出了一个基于 silency 的一个初始化的方式,具体来说它就是用一个已经训练好的一个 vision Transformer,然后把这个图片扔给那个 vision Transformer,然后把最后一层的那个多头自注意力取个加权平均,然后就做成了这么一个 sailency map,然后就在这个 sailency map 上去看哪些区域更显着,然后就在这些显着的区域上去采点,这样作者就发现最后的一个生成就稳定了很多,而且效果普遍也都好了许多。当然这个其实是很容易理解了,毕竟你在这些显著性的区域去踩点,其实说白了你已经知道这里有一个物体,或者其实你已经是沿着这个物体的边界再去画这条被滋曲线了。所以你的初始化曲线很有可能就跟你最后的那个简笔画已经相差不了多少了。这个其实在作者后面这个补充材料里也有验证,作者说他们这个模型的训练一般需要花 2000 个iteration,但往往在 100 个 iteration 的时候,你就已经能看出来这个模型工作的怎么样,就大致的那个简笔画轮廓就已经出来了,所以收敛是非常快的。
那我们来看一下它这个收敛过程。在文章的图 7 里,作者给了一个例子,如果这个输入是一个人脸,那总共这个训练一般是花 2000 个iteration。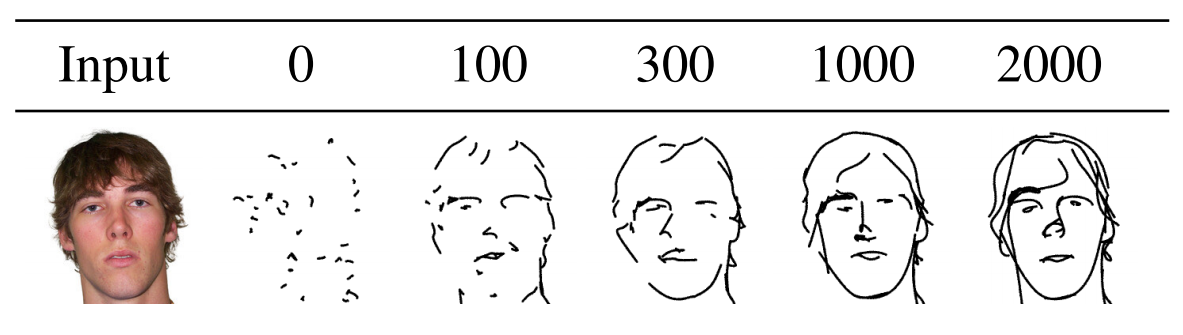
我们可以看到,从 100 个 iteration 开始,就已经基本能看出来是个人脸的形状了,而且眼睛、鼻子、嘴其实都在那了。然后在 300 iteration 或者 1000 个 iteration 的时候,其实这个人脸的简笔画就已经不错了,然后最后一直收敛到 2000 个iteration,变成一个更像简笔画的一个输出。
然后这篇论文其实还有一个很好的点,就是它的模型训练很快,作者在
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2688
2688

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









