







 本文详细介绍了形式验证中的Bounded Model Checking(BMC)技术,用于解决状态空间爆炸的问题。BMC通过限定步数寻找Counter Example(CEX)来证伪属性。当属性对应的Confidence of Interest(COI)复杂时,BMC能有效避免BDD引擎的局限。文章讨论了如何评估proofdepth,包括延迟分析、微架构分析和错误案例覆盖等,并提出了深Bug狩猎(DeepBugHunting,DBH)策略,以在验证稳定阶段进一步收敛。DBH策略如CycleSwarm、BoundSwarm等提供了更深入但稀疏的状态空间搜索。此外,文章还提到了local over-constraining技术以减少状态空间,提高收敛效率。
本文详细介绍了形式验证中的Bounded Model Checking(BMC)技术,用于解决状态空间爆炸的问题。BMC通过限定步数寻找Counter Example(CEX)来证伪属性。当属性对应的Confidence of Interest(COI)复杂时,BMC能有效避免BDD引擎的局限。文章讨论了如何评估proofdepth,包括延迟分析、微架构分析和错误案例覆盖等,并提出了深Bug狩猎(DeepBugHunting,DBH)策略,以在验证稳定阶段进一步收敛。DBH策略如CycleSwarm、BoundSwarm等提供了更深入但稀疏的状态空间搜索。此外,文章还提到了local over-constraining技术以减少状态空间,提高收敛效率。
bounded proof
形式验证本质上是一种model checking;不同类型的模型检查,调用不同的算法引擎;对于特定的属性求解,需要调用合适的engine;symbolic model checking基于BDD(binary decision diagram);BMC (bounded model checking)基于SAT(satisfiability)🔗Bounded Model Checking;
如果一个属性(如 end-to-end checker) 对应的COI很复杂,状态空间“爆炸”的特性,使得BDD的engine很难求解出结果;此时可以采用BMC的模型检查,通过找到一个CEX来证伪;BMC的主要思想是:在一个限定的步数k内,考察系统运行的情况,确定性质是否满足。若不能确定性质是否存在,则提高k值,重新进行检验。在每一个检查周期内,BMC问题被转化成SAT问题求解。
所以BMC的结果可能是inconclusive或者undetermined的,但是在cycle N内,没有找到CEX, 则称为bounded proof;其中cycle N为proof depth;
相比之下,结果为full proof时,对应的cycle为infinite。在无穷尽的cycle中,都找不到CEX,也称为 unbounded proof。
那么bounded proof的结果可以用来sing-off吗,答案是肯定的,只要在proof depth内我们需要的所有场景都被收集处理即可;所以对于proof depth的评估需要建立一套标准,一味追求更大的proof depth并不可取,因为随着depth的增加,资源消耗可能呈指数倍增加(上篇梳理了常见的abstraction strategy,但即使采用也无法保证工具一定能full proof)如下图:
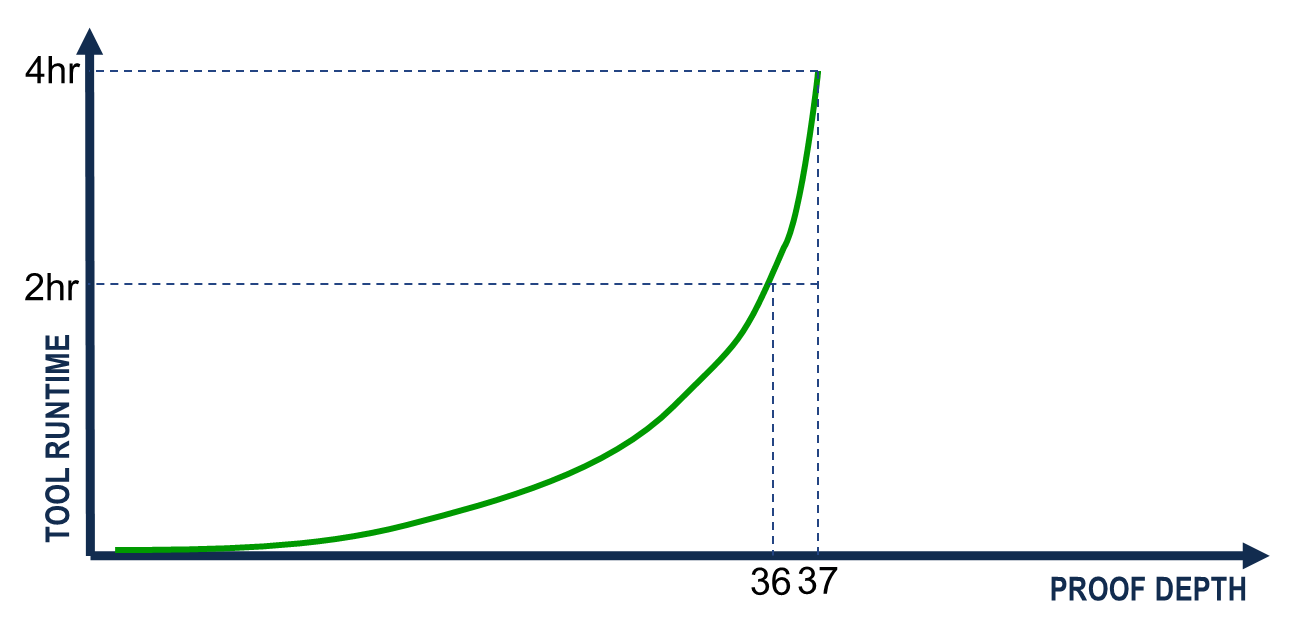
那么多大的proof depth可以提供足够的“信心”用于sign-off呢,可以依据以下方式判断:
-
Latency analysis of design
数据从一端到另一端的latency,根据DUT具体判断,需要考虑Initialization,Multiple input streams,Long packets (if it matters to the design),Error cases等因素

-
Micro-architectural analysis (with designer)
对DUT微架构分析,分析State machines,Counters,FIFOs,Linked lists等,判断覆盖特定场景需要的depth。 -
Covers for “interesting” corner-cases
增加一些感兴趣的corner point,参照覆盖这些corner的depth,作为最小的proof depth。 -
Formal Coverage
在当前proof depth下,如果Formal Coverage还未达要求,分析具体原因。 -
Failures seen during Formal Verification
从统计角度,创建并分析多维度的dashboard;如果在当前depth仍遇到bug,则需加深proof depth。 -
Safety Nets
如果仿真平台中发现了bug,需要在formal上复现,判断proof depth是否合理;
在日常回归中,执行deep bug hunting,监测更深的proof depth是否遇到bug,判断当前proof depth 是否合理。上述方式比较适合end-to-end的属性,其他属性也可以部分参照执行。
advanced topic
Deep Bug Hunting
当验证到达一个稳定的阶段(assertion完备,CEX没有新增,undetermined的属性无法进一步在cycle depth上推进) 时,传统的formal手段无法进一步收敛,可以考虑采用 DBH ( Deep Bug Hunting)的策略。
传统的formal是从复位状态开始,依次递增cycle并穷尽分析每个cycle下的所有状态空间;而DBH侧重于对状态空间进行更深入但稀疏的搜索。“稀疏”体现在DBH会跳过一些cycle和state,并不是穷尽的方式,所以也不会得到full-proof的结果。因此,DBH是一种semiformal 半形式化的验证。

DBH在传统formal的基础上实施,无需额外的工作量;DBH的部署比较依赖tool,不同的tool,使用方式差异大;VC Formal提供的DBH策略相较JasperGold更单一些,只有两种Fully Automatic Chained Search (FACS)和User-Guided Chained Search (UCS);但背后的思路类似,本篇对JasperGold提供的DBH做简略介绍:
Cycle Swarm Strategy

Cycle Swarm 也被称为 B-swarm(使用engine Bx),可以配置在特定cycle内做扫描搜索,支持多个job并行,从不同的cycle分别展开追踪。
configuring parameters

-first_trace_attempt: 配置开始追踪的cycle depth
-property:指定目标属性
-task:指定目标任务
engine mode
Bm(multi-property engine),B(single-property engine), or B4
Bound Swarm Strategy

Bound Swarm是Cycle Swarm的增强版;先使用较低的effor对不太复杂的cycle进行扫描搜索,再依次递增effort,对复杂的cycle进行扫描搜索;可以迭代地对特定cycle追踪。
configuring parameters

-trace_attempt_time_limit:第一次扫描的限定时间
-trace_attempt_time_limit_factor:增加迭代扫描时间的系数
-max_trace_length:基于first_trace_attempt的最大扫描cycle长度
engine mode
Bm,B, or B4
Guidepoint Strategy

Guidepoint通过指定一连串的covers,形成一个path,引导工具对特定属性搜索。
configuring parameters

-path: 指定一串cover序列
engine mode
Hp Ht B L
Loop Swarm Strategy

Loop Swarm只适用于livness property,支持并行jobs;针对livness property,提供多种length配置策略;
configuring parameters


-seed:十六进制数当作随机种子
engine mode
AB,AD,AM,B,B4,D,I,K,M or N
Simulation Swarm Strategy

Simulation Swarm类似普通的simulation,从reset状态开始随机搜索
configuring parameters

-max_trace_length:设定随机搜索的cycle depth,默认为50-1000 cycles
-restarts:设定随机的次数,默认不限制
-seed: 可以指定种子复现
engine mode
U,U2,J or Q3
State Swarm Strategy

State Swarm 也被称为 L-swarm(使用engine L),可以用户定义或者自动生成help cover,L engine会从一个cover跳转到另一个cover;并且这些help cover是分散开的,L engine会尝试不同的路径到达同一个cover。常见的cover类型如FSM的状态,enable相关信号,特定的pattern(counter number,full,empty, valid, hit etc)。
configuring parameters

-start_state_count:配置start state所参考的help cover个数
-random_diversification_factor:配置engine L在cover跳转时的随机分散值
-auto_helper_num:tool自动生成的help cover个数
-auto_helper_type:tool自动生成的help cover类型
engine mode
L
Trace Swarm Strategy

Trace Swarm在已经建立的追踪基础上,继续进行搜索。已经追踪到的状态可以是State Swarm或者Simulation Swarm,也可以是传统formal中的proved cover;Trace Swarm必须在上述策略执行后再执行:
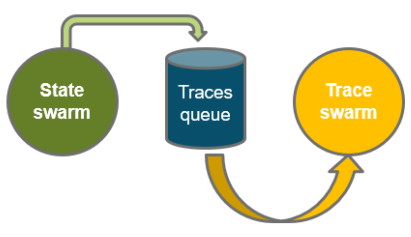
Trace Swarm比较适用于livness property。
configuring parameters

engine mode
B Ht
Trace Search Strategy

Trace Search是在一条path上进行更广的搜索;而Trace Swarm是基于cover到的一个状态扩展搜索;
Trace Search建议的目标深度不要太大,一般10个cycle最佳,避免复杂度,并且可以达到对路径上状态空间更广度的搜索。
configuring parameters

engine mode
B Bm
Formal Strategy with local over-constraining

local over-constraining通过增加over-constraint减少状态空间,提高收敛效率;一般用于特定的,难以收敛的属性。
configuring parameters

-add_constraint:增加约束条件(一般是disable某组接口或者agent,限制包或传输事务的长度,限制总线数据的值,设置特定寄存器的值,等)
engine mode
Ht BM Hts B
上述罗列的9种策略通过命令行配置,需要一定的学习成本,Jaspergold提供Hunt Manager支持GUI界面配置,并附带一些default配置可供直接使用。
对于livness property,并不是所有策略都支持:

详细的配置参数可以参考官方文档!
State Space Tuning
TODO
End to End check
TODO
Deadlock Hunting
TODO



















 5256
5256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











