







1、Vivado工具的多线程
工具最大同时运行的线程数量由操作系统决定,Win系统限制是2,Linux系统限制是8,更改并行线程的约束TCL指令是
set_param general.maxThreads <new limit>
set_param general.maxThreads 8
可同时运行的线程数量是以下几个值的最小值:
处理器最大值、任务的线程限制、线程的通用限制
2、通过设计约束指导实现
约束一共分成三种,物理约束、时序约束和功耗约束
物理约束:包括了引脚位置,对于BRAM、DSP、LUT、触发器的绝对布局或相对布局,预布局约束将物理单元限制在器件的某一区域,器件配置设置
时序约束:定义设计工作的频率
功耗约束:运行环境例如电压设置、功耗和电流预算、运行环境的细节,转换活动率(功耗约束相关内容可参考UG907)
3、布局布线的实现策略
3.1布局布线种类
| 种类 | 目的 |
| 性能(Performance) | 提升设计性能 |
| 面积(Area) | 减少LUT的使用数量 |
| 功耗(Power) | 增加全功耗的优化 |
| 流程(Flow) | 修改流程步骤 |
| 拥塞(Congestion) | 减少拥塞和相关的问题 |
3.2布局布线策略
4、布局布线实现的流程
4.1打开综合结果
实现的第一步是将综合的网表结果读取到内存中并施加设计约束
(1)将设计文件包括Verilog、EDIF、Vivado IP等组合成网表文件
(2)将符合规定标准的网表单元转变为当前设计支持的单元
(3)从XDC文件中读取并施加约束
(4)建立布局指令
4.2 逻辑优化
该步骤进行网表连接性的确认,来提示潜在的设计问题比如多信号驱动同一个输入引脚或没有驱动。该步骤同时会进行BRAM的功耗优化。
逻辑优化会跳过约束中标注的单元、网络等,防止后续约束无法找到对应的对象。
(1)重定向(Retargeting,默认)
重定向一类模块到另一类,将简单的单元吸收到下游逻辑中(如反相器),当下游逻辑无法吸收时,反相器会被放置在驱动器之前,并调整其他逻辑保证功能的一致性。
(2)常数传播(Constant Propagation,默认)
和常数进行运算的逻辑进行简化,例如和0相与的运算简化为0
(3)扫除(Sweep,默认)
去除无负载的单元和未连接的网络,并进行一些其他的优化
(4)多路选择器优化
重新布局MUX7、MUX8、MUX9原语到LUT3中,来提升布线便捷性。可以通过设置MUXF_REMAP属性为true使能对于单独MUXF的优化
(5)进位链优化
将进位链中CARRY4和CARRY8的基本单元优化成LUT,从而以提升可布线性。-carry_remap选项只能优化一阶进位链。可以通过使用CARRY_REMAP属性单独优化任意长度的进位链,,该属性可以设置优化对象的最大进位链长度。
例如一个包含1、2、3、4长度CARRY8单元的设计,可将CARRY_REMAP属性应用于所有的CARRY8,优化之后长度为1和2的进位链都将被优化成LUT资源
set_property CARRY_REMAP 2 [get_cells -hier -filter {ref_name ==CARRY8}]
(6)控制信号融合
减少等价逻辑的驱动器数量变成同一个驱动,类似于降低fanout的反向操作,该操作只应用于控制信号
(7)等价驱动融合
(8)BUFG优化(默认)
逻辑优化适当插入BUFG在始终网络和大扇出网络上,对于7系列只要12个全部的BUFG没有使用完,会进行BUFG优化,对于非时钟网络要求扇出大于25000、驱动该逻辑的时钟周期小于器件/速度限制才会进行BUFG优化
(9)移位寄存器优化(默认)
SRL扇出优化,如果一个SRL(LUT-based shift register)单元驱动大于100的扇出时,将会将最后一级的SRL替换成一个寄存器单元,更有助于下级的复制来缓解时序紧张
SRL可以替换成寄存器,这种优化可以提升处理时钟的频率,但同时会增加延迟
寄存器可以替换成SRL,这种优化一般用于在器件中长距离走线时缩减流水线中的寄存器数量,太多的寄存器可能会导致拥塞或其他布局问题。
(10)DSP寄存器优化
优化DSP Slice的流水线,增加输入输出的寄存器
(需要补充MREG、PREG等概念)
(11)控制集缩减
拥有较少控制集合的设计在布局上拥有更多的选择和灵活性,通过CONTROL_SET_REMAP属性应用在使用了置位、复位、选择控制信号的寄存器上可以缩减单独控制的数量
(12)基于模块的扇出优化
(13)重新布局
重新布局连接多个LUT到一个单独的LUT中从而降低逻辑深度
(14)激进的重布局(Aggressive Remap)
耗费更多的运行时间,进行更彻底的LUT优化
(15)基于面积的重新综合(Resynth Area)
在面积模式下降低LUT的使用数量
(16)Resynth Sequential Area
缩减互联和序列逻辑,进行最彻底的面积重新布局优化
(17)BRAM功耗优化(默认)
将未进行读操作的真双端口RAM的WRITE_MODE设置为NO_CHANGE
自动增加对BRAM输出的时钟门控
(18)属性优化
(19)重新综合重布局
4.2.2优化设计默认的指导策略
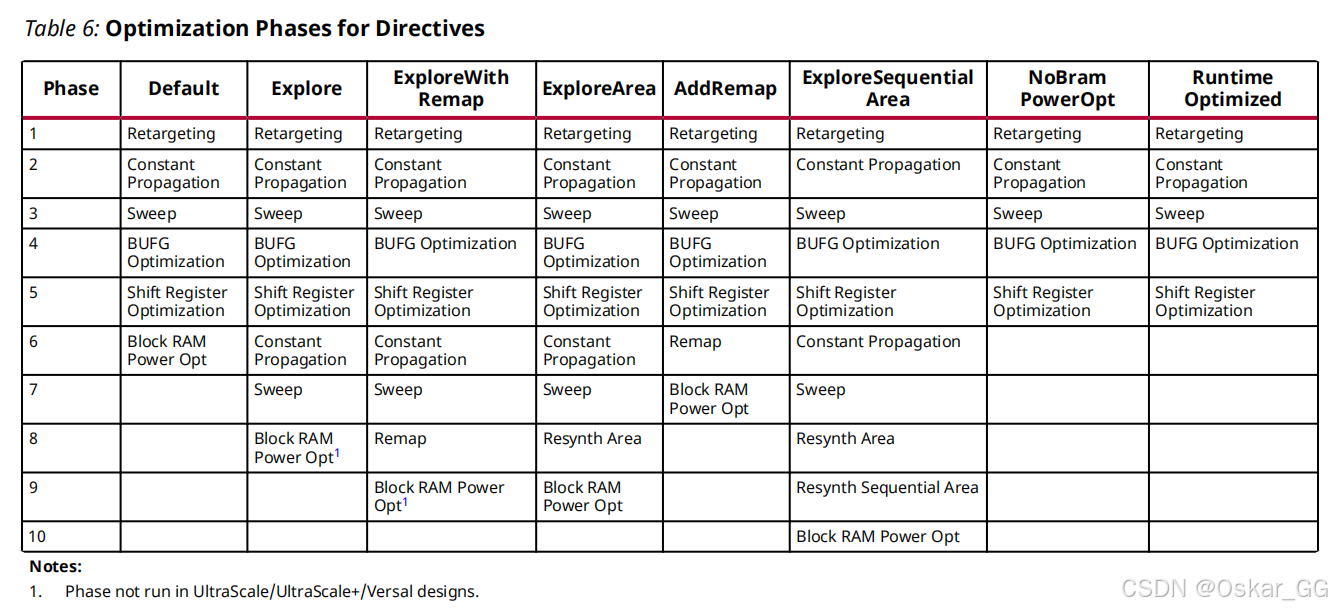
4.3 功耗优化
通过增加智能的门控时钟来降低动态功耗
4.4 布局
(1)针对时序紧张、走线过长、布线拥塞进行同步优化
(2)DRC
(3)时钟和IO布局
布局工具先布局IO接口和其相关逻辑、全局时钟缓冲器、时钟管理单元(MMCM、PLL)、告诉接口收发器
时钟资源的布局遵照UG472、UG572、AM003中的描述,例如7系列的BUFG驱动输入必须在全局时钟引脚且位于和BUFG相同的上半部分或下半部分,Ultra系列的必须在同一个时钟域
(4)全局布局、细节布局和布局后的优化
FLoorplanning phase:预布局阶段,会将设计按照IO和时钟资源布局位置分割成相关逻辑的集群。在这个阶段会将Pblock约束认为硬性约束。对于SSI器件,设计会分割成不同不同的SLRs来减少SLR之间的交互和延时
Physical Synthesis:基于前一个阶段的结果优化网表,布局工具会进行多种物理层优化,从而更便于后续网表的布局
LUT Decomposition and Combining:LUT解耦会拆分LUT的形状以提升时序,LUT组合会组合LUT以提升LUT的使用效率
Property-Based Retiming:用户通过设置属性可以对寄存器或者LUT进行retiming操作,属性是将PSIP_RETIMING_BACKWARD或PSIP_RETIMING_FORWARD设置为true 。
PSIP_RETIMING_BACKWARD:该属性指示工具将寄存器向后移动,即从输出端向输入端移动寄存器。它适用于组合逻辑的输出端有寄存器的情况,通过将寄存器移动到组合逻辑的输入端,可以减少关键路径的延迟
PSIP_RETIMING_FORWARD:该属性指示工具将寄存器向前移动,即从输入端向输出端移动寄存器。它适用于组合逻辑的输入端有寄存器的情况,通过将寄存器移动到组合逻辑的输出端,可以优化时序
Critical Cell Optimization:在时序违例路径上复制关键单元,如果某个单元的负载布局位置太远,会将该单元复制出新的驱动放置在负载簇附近,该优化常用于驱动大规模BRAM、URAM的网络中。
Fanout Optimization:
DSP Register Optimization:
Shift Register to Pipeline Optimization:
Shift Register Optimization:
Block RAM Register Optimization:
URAM Register Optimization:
(5)布局设计
(6)自动流水线设计
可以选择在时序紧张的关键总线和接口上插入流水线寄存器以优化时序
4.5物理层优化
主要针对时序违例的路径进行时序驱动的优化,主要包括post-place和post-route
post-place模式下物理优化会自动合并由于逻辑优化而产生更改的网表,并根据需要放置单元。
post-route模式下,物理优化自动根据需要更新布线
路径后物理优化最有效地用于具有少量失败路径的设计。在WNS<-0.200 ns或超过200个失效端点的设计中该优化的效果不明显
总体来说物理优化在post-place模式下更为激进,因为这种模式下逻辑优化空间更大,相比较而言post-route模式下的优化更为保守以避免扰乱时序临界的布线,物理层优化在运行前会自动判断采用哪种方式更适合当前的布线状态
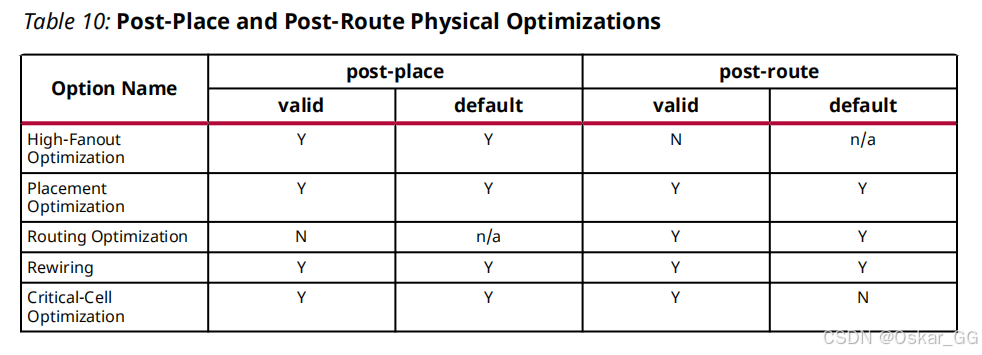
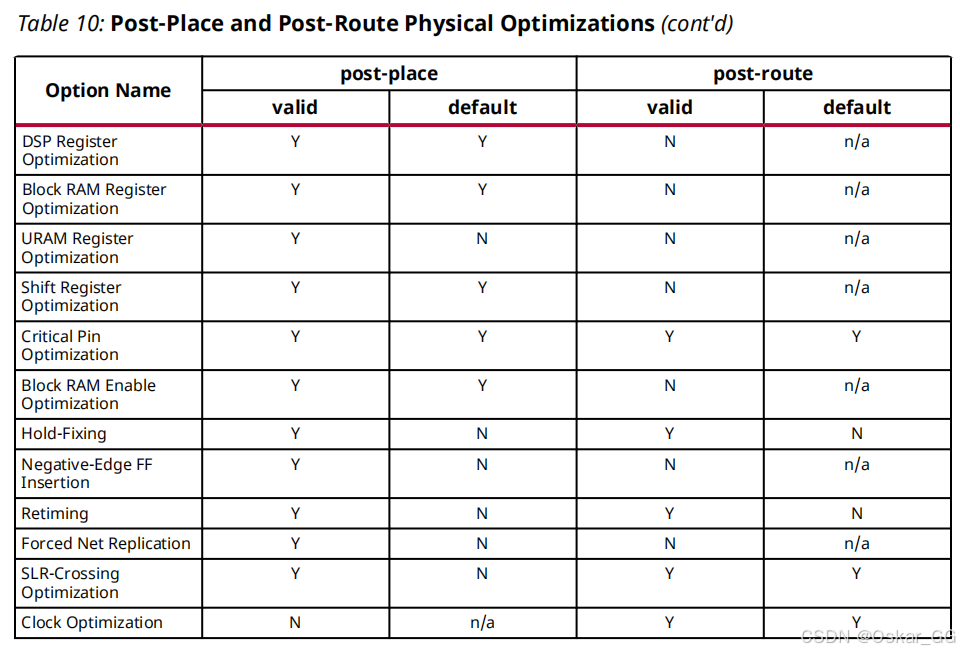
物理层优化分别进行的操作
4.6布线
Vivado布线器基于布局后的设计进行布线操作,并基于布线设计进行优化来缓解保持时间的冲突。当对整个设计布线时,布线流程是时序驱动的,使用了基于时序约束的自动时序评估工具。布布线单独的网络和引脚可以采用两种不同的模式进行:
Interactive Router mode和Auto-Delay mode

















 6883
6883

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









