







在Vivado中,Implementation Strategy(实现策略)提供了多种预设配置,以满足不同的设计目标,如性能、布线拥塞、资源利用率、功耗和运行时间等。
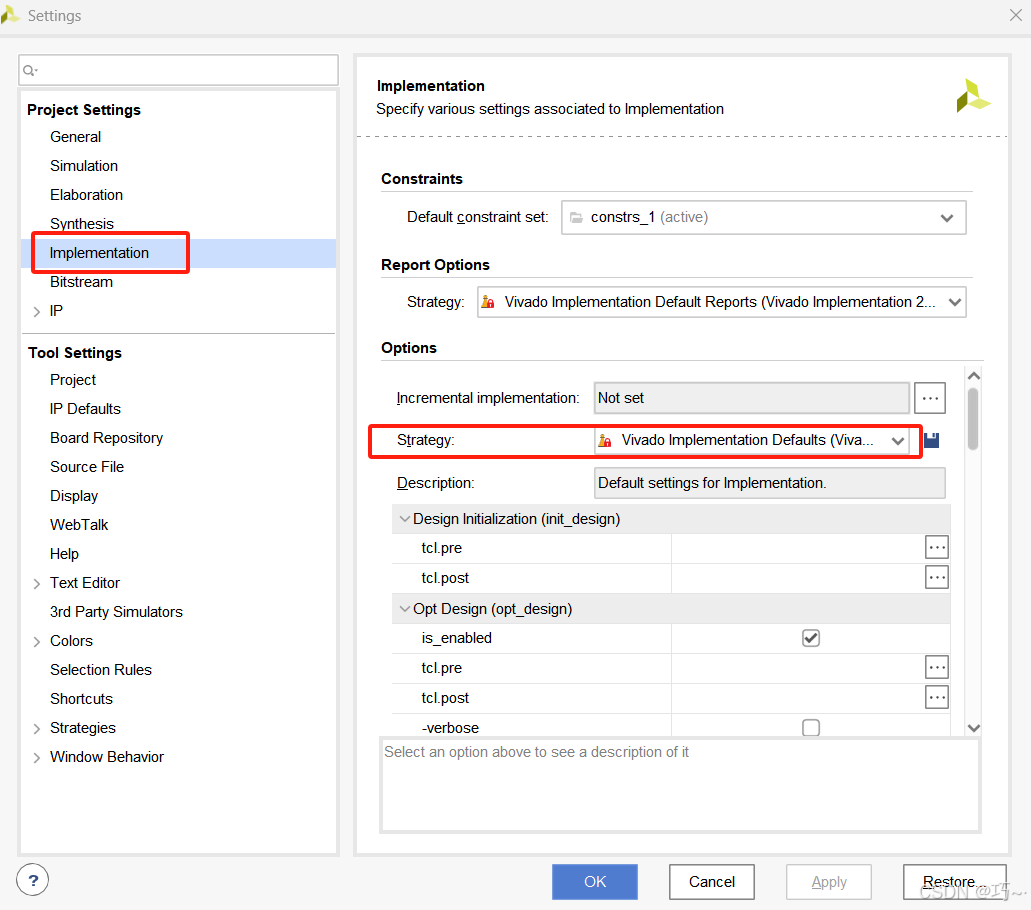
以下是各种策略的详细分类和说明:
1. 针对性能优化的策略:
这些策略主要关注提高设计的时序性能(Timing Performance),包括减少延迟、提高时钟频率等。
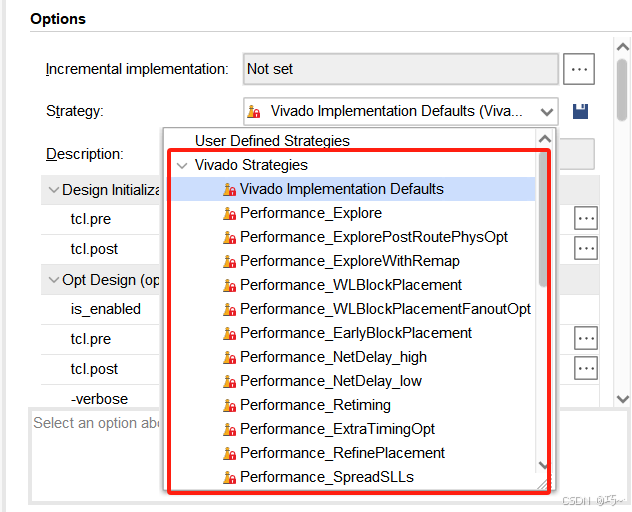
Performance_Explore:
尝试多种优化方法,探索最佳性能。
适合对设计性能要求较高但不确定哪种优化方法最有效的情况。
Performance_ExploreWithRemap:
在性能优化的基础上,尝试重新映射逻辑资源(Remapping),以进一步优化时序。
适合需要深度优化时序的设计。
Performance_ExplorePostRoutePhysOpt:
在布线后进行物理优化(Physical Optimization),进一步优化时序。
适合时序紧张的设计。
Performance_WLBlockPlacement:
优化块(Block)的布局,以减少布线长度和延迟。
适合需要减少长距离布线延迟的设计。
Performance_WLBlockPlacementFanoutOpt:
在块布局优化的基础上,进一步优化高扇出网络(High Fanout Nets)的布线。
适合存在高扇出信号的设计。
Performance_NetDelay_high:
针对高延迟网络进行优化,减少关键路径的延迟。
适合时序关键路径较多的设计。
Performance_NetDelay_low:
针对低延迟网络进行优化,优化整体网络的延迟。
适合对整体时序要求较高的设计。
Performance_Retiming:
通过重新调整寄存器的位置来优化时序。
适合需要平衡组合逻辑延迟的设计。
Performance_ExtraTimingOpt:
在标准优化基础上,增加额外的时序优化步骤。
适合时序非常紧张的设计。
Performance_RefinePlacement:
在布局完成后,进一步优化布局以减少延迟。
适合需要精细布局优化的设计。
Performance_SpreadSLLs:
分散布局中的SLL(Slr-Local Lines)资源,以减少布线拥塞。
适合使用SLL资源较多的设计。
Performance_BalanceSLLs:
平衡SLL资源的使用,优化布线资源分配。
适合需要均衡使用SLL资源的设计。
2. 针对布线拥塞优化的策略:
这些策略主要关注减少布线拥塞(Congestion),以提高设计的可布线性和资源利用率。
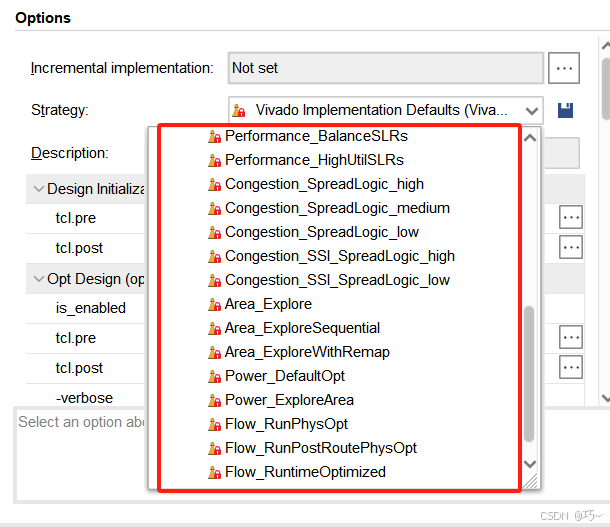
Congestion_SpreadLogic_high:
高度分散逻辑资源,以减少布线拥塞。
适合布线拥塞非常严重的设计。
Congestion_SpreadLogic_medium:
中度分散逻辑资源,平衡布线拥塞和性能。
适合中等布线拥塞的设计。
Congestion_SpreadLogic_low:
低度分散逻辑资源,优先考虑性能优化。
适合布线拥塞较少的设计。
Congestion_SpreadLogic_Explore:
尝试多种逻辑分散方法,探索最佳的布线拥塞解决方案。
适合不确定哪种方法最适合当前设计的情况。
针对SSI芯片的布线拥塞优化策略:
SSI(Stacked Silicon Interconnect)芯片是一种多芯片堆叠技术,通常用于高端FPGA(如Xilinx Virtex UltraScale+)。
Congestion_SSI_SpreadLogic_high:
在SSI芯片中高度分散逻辑资源,以减少跨芯片互连的布线拥塞。
适合SSI芯片中布线拥塞非常严重的设计。
Congestion_SSI_SpreadLogic_low:
在SSI芯片中低度分散逻辑资源,优先考虑性能优化。
适合SSI芯片中布线拥塞较少的设计。
Congestion_SSI_SpreadLogic_Explore:
在SSI芯片中尝试多种逻辑分散方法,探索最佳的布线拥塞解决方案。
适合不确定哪种方法最适合当前SSI芯片设计的情况。
3. 针对资源优化的策略:
这些策略主要关注减少资源使用量(Area Utilization),以提高资源利用率。
Area_Explore:
尝试多种优化方法,探索最佳资源利用率。
适合对资源利用率要求较高的设计。
Area_ExploreSequential:
针对时序逻辑(Sequential Logic)进行资源优化。
适合时序逻辑资源占用较多的设计。
Area_ExploreWithRemap:
在资源优化的基础上,尝试重新映射逻辑资源。
适合需要进一步减少资源使用的设计。
4. 针对功耗优化的策略:
这些策略主要关注降低设计的功耗(Power Consumption)。
Power_DefaultOpt:
使用默认的功耗优化方法。
适合对功耗有一定要求但不需要特别优化的设计。
Power_ExploreArea:
在优化功耗的同时,探索减少资源使用量的方法。
适合对功耗和资源利用率都有要求的设计。
5. 针对运行时间优化的策略:
这些策略主要关注减少实现(Implementation)的运行时间(Runtime)。
Flow_RunPhysOpt:
运行物理优化(Physical Optimization),以加快实现过程。
适合对运行时间要求较高的设计。
Flow_RunPostRoutePhysOpt:
在布线后运行物理优化,以进一步加快实现过程。
适合时序紧张且对运行时间要求较高的设计。
Flow_RuntimeOptimized:
针对运行时间进行优化,尽可能减少实现时间。
适合需要快速迭代的设计。
性能优化策略适合时序要求高的设计。
布线拥塞优化策略适合布线资源紧张的设计,特别是SSI芯片。
资源优化策略适合需要减少资源使用量的设计。
功耗优化策略适合需要降低功耗的设计。
运行时间优化策略适合需要快速实现的设计。

















 1386
1386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









