







 本文介绍了节点分类问题及其在GNN中的应用,详细阐述了有监督学习和无监督学习的GNN网络结构,包括GCN、GAN、VGAE等。同时,探讨了GNN中的过平滑问题及其解决方案PairNorm。
本文介绍了节点分类问题及其在GNN中的应用,详细阐述了有监督学习和无监督学习的GNN网络结构,包括GCN、GAN、VGAE等。同时,探讨了GNN中的过平滑问题及其解决方案PairNorm。
GNN学习笔记(四) 用于节点分类的GNN介绍
GNN学习笔记(四) 用于节点分类的GNN介绍
前言
本篇学习笔记对应教材GNN基础/前沿/应用的第四章内容。本章首先给出了节点分类的定义,然后从有监督学习和无监督学习两大分类分别介绍了用于节点分类的GNN的典型网络的基本结构。最后,介绍了影响GNN网络性能的过平滑问题,并给出了一种解决方案。
一、背景和问题定义
1.节点分类问题的定义
节点分类是将节点分类到几个已经定义好的类别中。所以用于节点分类的GNN网络学习的是节点的表达(node representation),在后续章节中会介绍形成图表达的GNN。
2.问题的符号定义
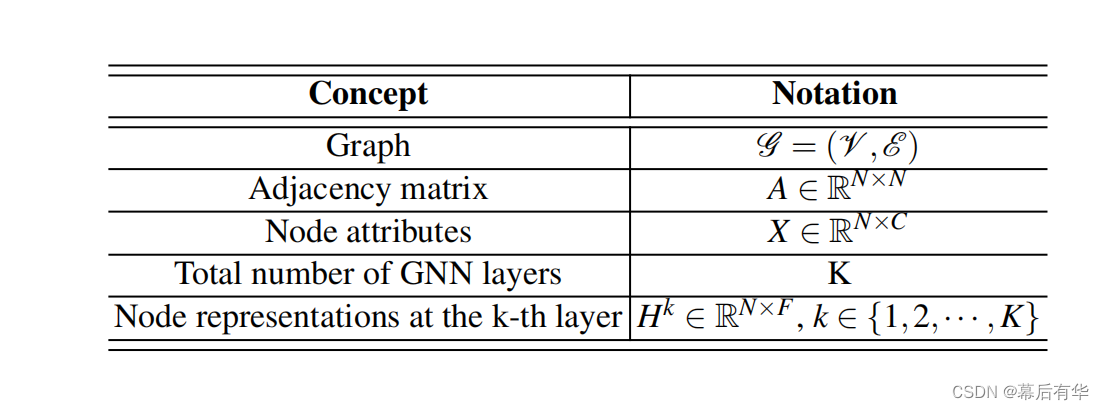
如上图,假设图G中共有N个节点,则记邻接矩阵为A,是一个N×N维的矩阵;节点参数矩阵记为X,其中C表示一个节点有C个参数;GNN网络的层数为K;第K层的节点表达记为Hk,其中,F表示每一个节点需要用F维表达。
3.GNN的一种分类方式
在本章中,我们将GNN分为有监督学习方法(supervised approaches)和无监督方法(unsupervised approaches)两类。在第二部分和第三部分中将分别介绍一些典型的有监督学习和无监督学习的GNN网络。
二、有监督学习的GNN
1.GNN的基本结构
记初始的节点表达为 H 0 = X H _0 =X H0=X,在每一层中要完成两项主要工作:
(1)聚合(Aggregate): 聚合每个节点邻居的信息
(2)组合(Combine): 将聚合后的邻居信息与节点百年身的信息组合起来,形成节点的当前表示。
两项工作的数学符号表示如下。
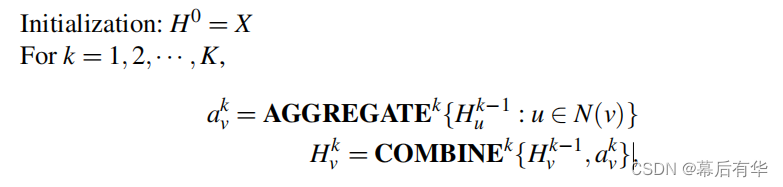
其中 N ( v ) N(v) N(v)是第u个节点的所有邻居的集合。第K层的节点表达 H K H^K HK为最终的节点表达。
当得到最终节点表达 H K H^K HK后可以利用其进行一些下行操作。例如,利用Softmax层来进行节点的分类。
y ^ = S o f t m a x ( W H v T ) \hat{y} = Softmax(WH{_v ^T}) y^=Softmax(WHvT)
其中,W是一个|L|×F维的矩阵,|L是|输出空间中标签的个数。
在有标签的情况下,可以通过最小化损失函数来训练模型:
O = 1 / n l ∑ i = 1 n l l o s s ( y i ^ , y i ) O =1/n_l \sum_{i=1} ^{n_l}{loss(\hat{y{_i}},y_i)} O=1/nli=1∑nlloss(yi^,yi)
loss()为定义的损失函数,可以为CE(),或MSE(), n l n_l nl为有预测标签的节点个数, y i y_i yi是节点的真实分类。
2.图卷积网络(GCN)
由于其简单有效,GCN是目前最流行的图神经网络。在GCN中,每一层的节点表达依照下式更新。
H k + 1 = σ ( D ~ − 1 2 A ~ D ~ − 1 2 H k W k ) H^{k+1}=\sigma(\widetilde{D}^{-\frac{1}{2}}\widetilde{A}\widetilde{D}^{-\frac{1}{2}}H^kW^k) Hk+1=σ(D
−21A
D
−21HkWk)
其中, A ~ = A + I \widetilde{A}=A+\textbf{I} A
=A+I是加入了自连接的邻接矩阵,可以在更新节点表达的同时就结合节点自身特征。 D ~ = Σ j A ~ i j \widetilde{D}=\Sigma{
{_j}\widetilde{A}_{ij}} D
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4503
4503

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









