







目录
TREG(Transformed Regression for Accurate Tracking)
个人感觉 :TREG=DiMP+Attention
Motivation
TREG的提出为了解决anchor-free不能生成精确的bbox。
本文的核心是建立目标模板和搜索图像的两个之间的关系,并用产生视觉特征增强后的结果提升回归的精度。由于采取了局部(local)和密集匹配,目标的上下文的特征能够增强目标的相关信息,能够更好的定位bbox和处理一些目标形变。同时,我们还设计了一个简单的online更新机制提升实时的外观变化和几何形变的鲁棒性。(online、offline的区别见这篇博客)
Introduction
之前box的预测分为两类:
1)间接bbox预测
早期使用的是一个基于分类的多尺度的暴力搜索策略回归粗略的bbox。ATOM、DiMP是使用IoU预测网络来选择、改善最终的box。
2)直接bbox回归
基于RPN的tracker预测 目标定位、在预定义anchor和目标位置的大小差异。SATIN和CGACD使用交叉互相关、导向性相关的attention来预测corcers。SiamFC++直接预测box的偏移量。早期的Siamese是使用anchor-based来预测框的大小。但是,由于anchor-free 设计简单和性能好,越来越多用anchor-free来预测box的大小。因为我们将跟踪问题作为一个one-shot监督来训练,所以anchor-free跟踪得不精确,导致对没见过的变形和变化泛化性不好。
于是提出了TREG:一个类似于transformer结构的、基于anchor-free、的目标导向型预测分支。采用了transfomer中的cross-attention去处理目标模板和搜索图像,生成一个更好的的特征图来预测精确的bbox offset(偏移)。
本文得核心问题是:如何将目标信息整合到回归分支中,以保留其精确的实时边界信息?1)为了生成精确的对象边界,在回归中保持足够的目标信息。2)为了处理外观变化和目标变形,回归分支应该要实时地处理形变。
因为目标模板的元素和搜索区域的元素间的局部和密集匹配,Target-aware的特征能够增强目标相关信息、处理一定程度的形变。
为进一步提高TREG效率 ,我们建立一个online目标模板队列来维护跟踪对象的变化,并设计一个基于更新策略置信度,自适应地选择可靠的目标模板。
最后,我们放置一个前馈网络在target transformer represention 之上,来获得对象边界偏移回归。
Related Work
Target regression for visual tracking
CSR-DCF 构建一个对象空间注意力图(an object spatial attention map)来约束相关的学习,CSR-DCF还计相关响应图的通道可靠性加权值。RASNet在Siamese中介绍空间、逐通道的attention。CGCAD 进一步提出了用于角点检测的引导性相关的attention。然而,逐像素级相关性引导的空间注意力忽略了有一些背景目标(背景就是我们框出来不要的部分,前景就是我们框出来想检测的部分),这可能会导致对背景目标有着高注意力权重。 TREG使用的是目标模板和搜索模板的逐对相关,就不会有这些问题。我们的目标感知转换器保留了足够的目标信息,以增强回归表示和可以很容易地部署在线回归(它结构简单)。
Proposed Method
设计目标:
1、一个完全目标化的集成模块,以生成高质量的视觉特征。目的:保留足够的目标信息来能够获得精确bbox
2、逐像素上下文建模,以增强与目标关联的特征、应对具有物体变形
3、设计了一个设计在线的目标队列来更新跟踪目标的变化

Multi-scale Cls Module:1)separate online classifer 生产了 低分辨得分图、高分辨得分图。融合两得分图来预测一个精确的目标中心点。训练时,目标是以真实目标为中心的高斯函数图。
回归分支是由Target-aware Transformer、一个前馈网络(2个conv、1个可形变的conv)组成,来预测边框的偏移。训练时,回归位置是在目标中心附近(2为半径的单位圆)。
PS:一维分布一般用高斯分布;二维用单位圆;三维用一个“山峰”;
目标感知转换器是旨在将目标外观融入回归特征中。最终,通过transformer运算的检索特征图,融入到原来的特征图中。这样原来的特征图就具有了丰富的目标感知的回归信息。(定位、密集匹配就完了吗?)下图中,只有4 个kernel为1的conv,conv将会被offline训练。

定义target-aware feature transformmtion:
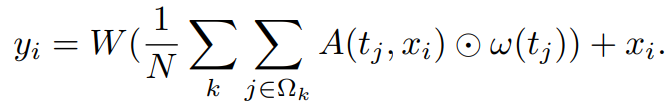
i , j是xi搜索特征图、tj目标特征图的所有位置。k 索引目标队列,Ω k是用于查询的 目标特征图单元格。k 个索引目标队列中的模板和Ω k指定特征用于查询的目标模板中的单元格。函数 ω 计算j位置处目标(作为value)的特征图。其中,
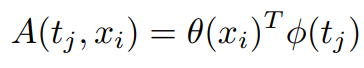
θ 函数将 x i编码为query,φ 函数将 tj编码为key。所以Target-aware intormation aggregation就是加权和。之后用N正则化,N是目标队列的总数,即 t × h × w,t 是模板的数量,h 和 w 是模板尺寸。
此外,我们建立一个online目标模板队列来维护跟踪对象的变化。权衡使用在线目标和静态目标至关重要。3个静态目标参数是来源于 给出模块的数据增强的三个样本(15个数据增强样本)、4个online参数是基于分类置信度的online目标自适应选择的。当目标在online sample bar中被预测有最大的置信度时,该目标模板就会被加入到目标队列中。
offline training
数据:LaSOT,TrackingNet, GOT-10k,COCO
mini-batch:80
ADAM: lr=0.2
online training
对数据进行了增强,对第一帧进行了平移、旋转、模糊生产了15 个初始在线训练样本,用于在线分类。选择了3个样本作为静态目标(用于在线目标队列)。静态的由第一帧变换增广生成,动态的取每n帧中得分最高的 。
实验
在VOT中取得了SOTA,也尝试把Transformer应用于分类,发现并没有DiMP的效果好。
作者没有将代码公开,所以目前还没有对其进行复现。















 1266
1266











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









