







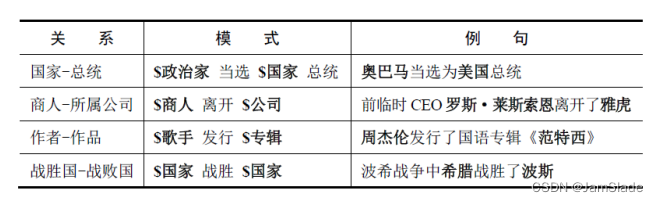
关系抽取概述
知识图谱是一种以图形化的(Graphic)形式通过节点和边表达知识的方式,其基本组成元素是节点和边
节点确定:实体识别
边确定:关系抽取
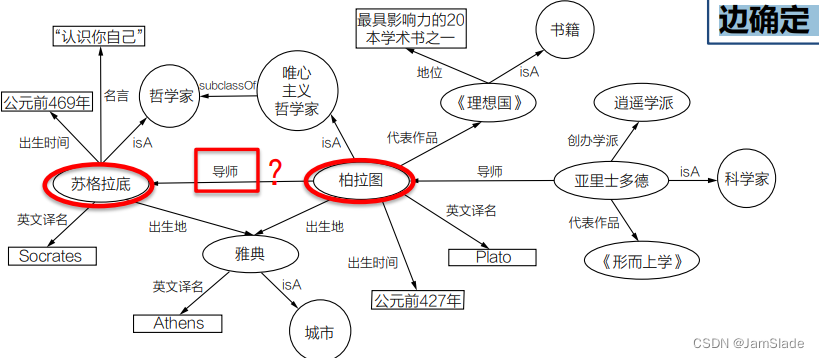
关系抽取(Relation Extraction,RE):旨在从文本中抽取出两个或多个实体之间的语义关系
输入:
“柏拉图与老师苏格拉底、学生亚里士多德并称希腊三贤“
输出
<柏拉图,老师,苏格拉底>
<柏拉图,学生,亚里士多德>
• 关系抽取是信息抽取(information extraction)重要子任务之一
• 关系抽取是构建知识图谱的最重要子任务之一
• 关系抽取的结果可用于下游NLP任务
Ø 如文本理解、问答系统和聊天机器人
• 关系实例抽取
Ø 文本+P→{(S,O)}文本+P\rightarrow\{(S, O)\}文本+P→{(S,O)}
Ø 给定关系P,从语料中抽取更多关系实例
• 关系分类
Ø 文本+(S,O)+P→Pi文本+(S, O)+P \rightarrow P_i文本+(S,O)+P→Pi
Ø 根据实体对的文本描述,将实体对的关系进行归类(通常需要预定义关系类型集合P
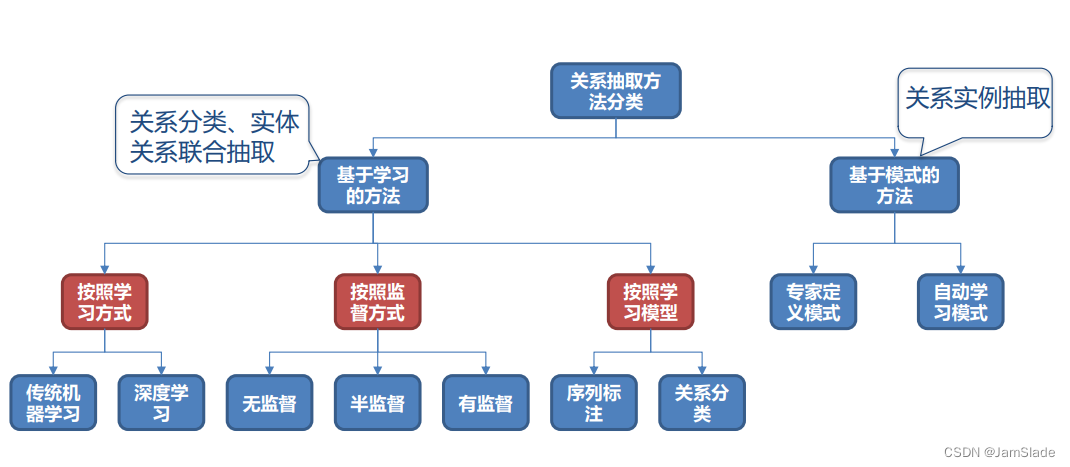
基于模式的关系抽取
基本思想:
Ø 使用模式(模板,pattern)表达关系在文本中提及的方式
Ø 将模式与语料匹配,获取关系实例

• 关键问题
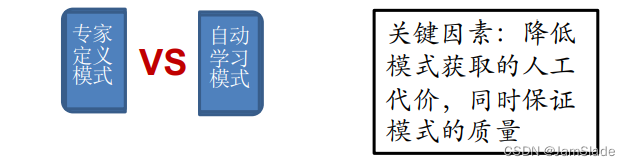
Ø 如何表达模式?

Ø如何获取模式?
• 将自然语言视作字符序列,模式表示为一组正则表达式

特点
• 要为每个关系构造相应的正则表达式
• 对文本与模式的相似性有着较高的要求
• 常用于抽取有着固定描述模式的内容
• 难以适用于广泛而多样的文本

• 选择合适的模式粒度是基于模式抽取的关键
引入语法信息(包括词法和句法等)精化抽取模式
如:
“NP1著有NP2”⟹< NP1,作者, NP2>
• 特点:
Ø 相比于单纯的字符模式,语法模式表达能力更强
Ø 语法模式仅仅依赖人类的语法知识,因此语法模式的获取代价相对较低
Ø 普遍存在于各类语言中,适用于各种不同类型的文本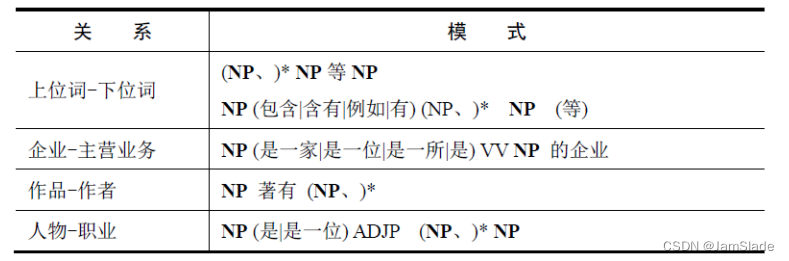
• 将概念引入模式的描述中,且定义基于概念约束的模式

• 特点:
Ø 利用概念定义模式,因此依赖较完善的概念图谱
Ø 降低了所匹配的实例发生语义漂移的可能性
• 优点
Ø 精度相对较高
Ø 可以针对特定领域进行定制
• 缺点
Ø 需要为每个关系定义相应的模式
Ø 人工成本高、代价大
Ø 召回率、精度尚有改进余地

• 如何提高基于模式方法的召回率?
Ø Bootstrapping(自举法)
• 主要思想
Ø 自动发现更多的模式,提升基于模式方法的recall
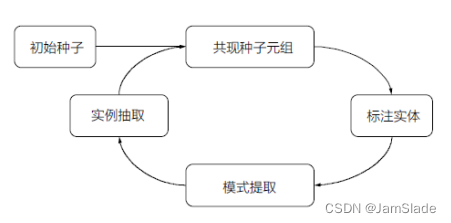
• 基本过程
Ø 模式提取+实例抽取 相互迭代
• 是一种半监督的思路
Ø 用当前已经习得的模型(模式)自动标注新样本,基于新补充的样本逐步提升模型
• 自举法抽取关系的迭代过程
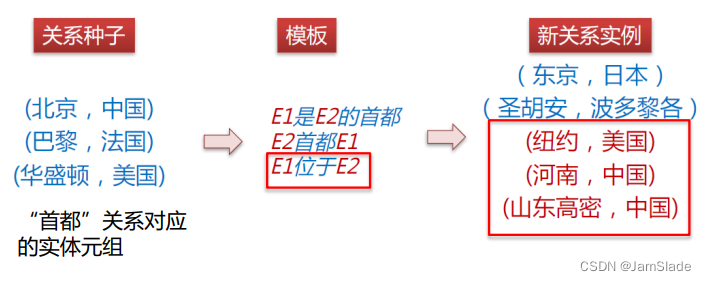
- Ø Step1:给定关系“出生于”、种子实体对<周杰伦,台湾>和<林丹,福建>
- Ø Step2:抽取出句子集合:{“周杰伦,出生于台湾省新”,“周杰伦在台湾…”,“林丹小时候在福建学球”}
- Ø Step3:得到关系“出生于”的描述Pattern{“X出生于Y”,“X在Y”,“X小时候在Y”}
- Ø Step4:基于该模式,抽得句子“林俊杰,出生于新加坡的一个音乐世家”,从而得到实体对<林俊杰,新加坡>
扩充种子实体对
• 代表性系统
Ø DIPRE系统 (Brin, 1998)、Snowball系统 (Agichtein, 2000)、KnowItAll系统 (Etzioni et al. 2005)、TextRunner系统(Banko et al. 2007)
• 迭代过程中得到的新模式不再能表达种子关系
• 迭代会引入噪音实例和噪音模板
• Bootstrapping-语义漂移解决方案
Ø Mutual exclusive Bootstrapping:同时扩展多个互斥类别,一个实体对只能属于一个类别;
Ø Coupled training:建模不同抽取关系之间的约束,寻找最大化满足约束的抽取结果;
Ø Co-Bootstrapping :引入负实例来限制语义漂移;
• 评估候选模式是否能在语料中准确抽取出目标关系实例
• 对于Bootstrapping中自动习得的模式进行筛选,提升准确率
• 抽取质量通常可以从两个角度进行判定:
Ø实例与模式的匹配程度
• 基于模式的匹配通常使用模糊匹配,以提升recall
• 模式与实例的匹配程度,可以表达抽取质量
Ø模式本身的置信度
• 抽取的准确率作为模式的置信度
• 模式与正确实例越匹配,质量越高
• 与模式越匹配的实例,越可能正确
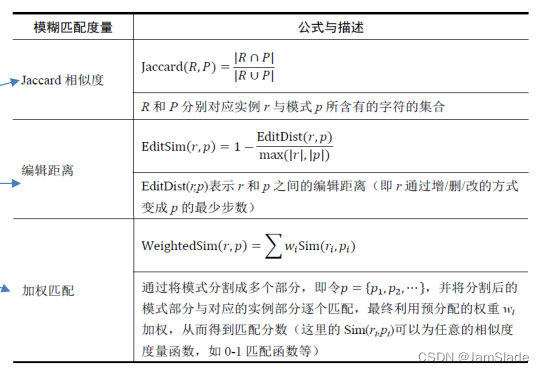
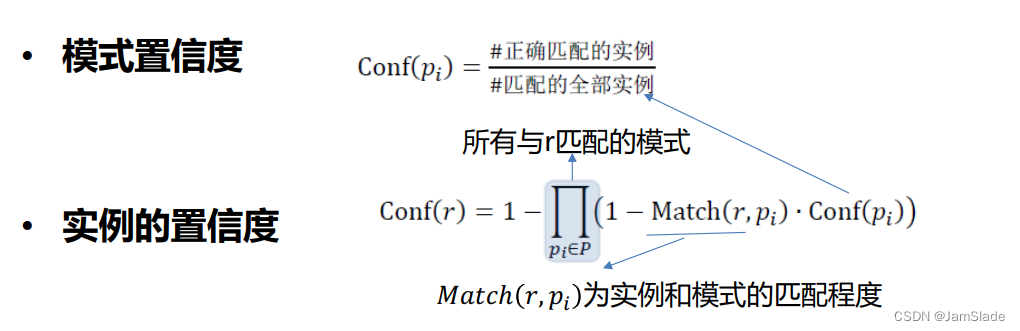
模式置信度越高(质量越好),实例与模式的匹配程度越高,则抽取实例的置信度越高。
基于学习的关系抽取方法
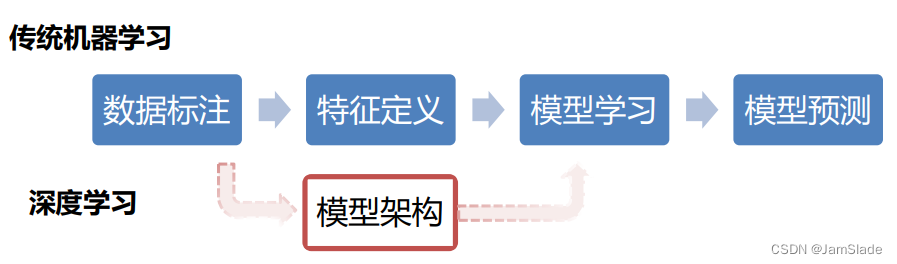
• 核心思想:利用标注语料学习抽取模型
• 降低人工模式定义的代价
• 基本过程
关系分类
• 接受包含实体对的文本作为输入,产生预定义关系类别上的概率分布
• 关系类别通常来自知识库
• 需要谨慎处理未知类别
序列标注
接受文本(字符序列)作为输入,生成相应的标记序列
• 每个标记表示相应字符是否是实体、关系
• 实体、关系、嵌套实体、多元关系均可以标记
特征定义
• 传统机器学习核心问题:特征定义
• 可解释,可控
• 上下文中的各种词法、句法、语义等信息,或者背景知识等
Ø 实体词汇及其上下文特征
Ø 实体类型及其组合特征
Ø 基本短语块特征
Ø 依存树特征
Ø 句法树特征
词法特征
• 实体对之间或周围特定的词汇
Ø 两个实体之间的词袋信息;
Ø 词袋的词性标注结果信息;
Ø 实体对在句子中的顺序标志信息;
Ø 左实体的窗口大小为k的词袋及其词性标注信息;
Ø 右实体的窗口大小为k的词袋及其词性标注信息;
• 句法特征
Ø 依存分析的结果包括词汇集合以及词汇之间的有向语法依赖关系
• 其他特征
Ø 实体类型、概念、背景知识(如wordnet),位置信息等等;
知识图谱应用
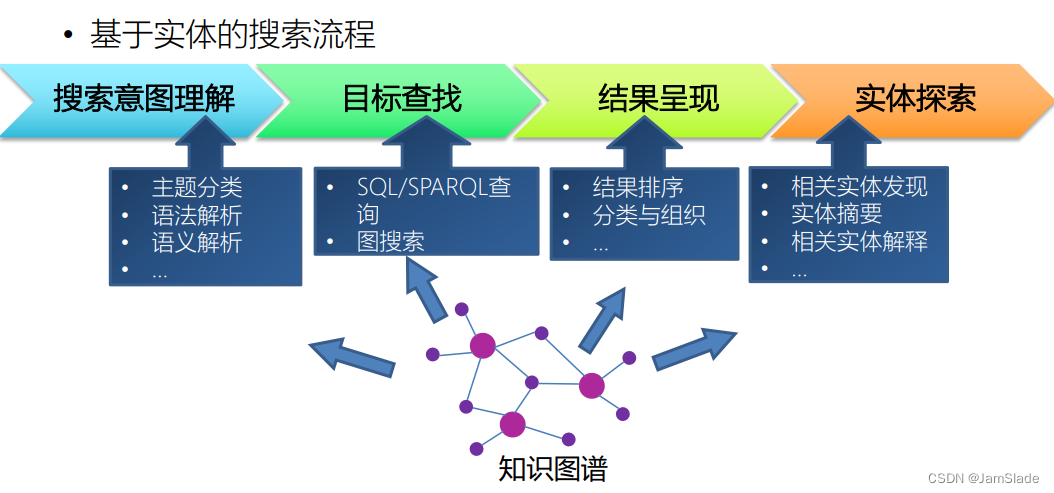
• 基于实体的搜索流程
• 准确捕获用户的搜索意图(目标)是前提
• 如果目标实体不唯一,还需将目标实体排序后再返回给用户
• 如果无法明确目标实体,只能寻找一些相关实体,同样需要实体排序
• 从改善用户搜索体验考虑,搜索结果除了展现目标实体外,最好还能以合适的形式展现相关实体、概念,以及它们之间的关系
知识图谱应用:推荐
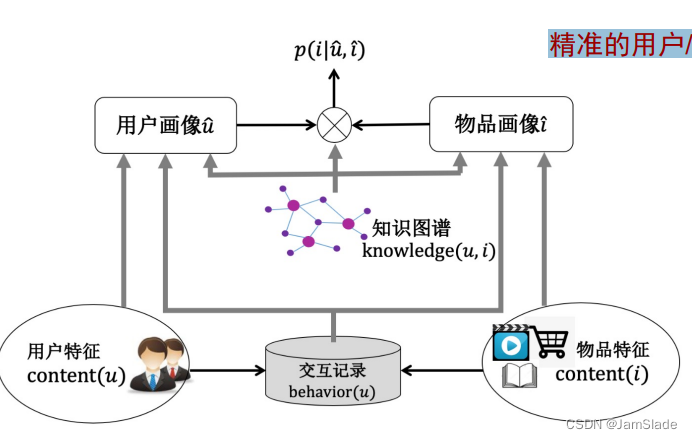
• 推荐算法的基本框架
精准画像才是关键
• 传统推荐算法的挑战
• 冷启动:对新用户或者新物品进行推荐时存在的冷启动问题
• 数据稀疏:用户和物品之间的行为关系数据比较稀疏
• 缺乏多样性:推荐结果单一,只推荐某类物品
• 缺乏可解释性:难以解释为什么给用户推荐该物品
• 推荐+知识图谱
可以与用户行为数据构成的用户-物品网络集成起来,从而扩展了用户与商品之间隐藏的关联关系, 补充更多交互数据 -> 对应数据稀疏
• 蕴含了物品的大量背景信息, 以及物品之间的各种关系 -> 冷启动 多样性
• 知识图谱中的路径为推荐结果提供了一定的可解释 ->可解释性
推荐系统中引入知识图谱的优势
提高精准度(precision)
Ø 知识图谱为物品引入了更多的语义关系
Ø 知识图谱可以深层次地发现用户兴趣
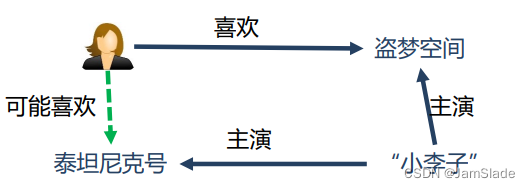
增加多样性(diversity)
Ø 知识图谱提供了不同的关系连接种类
Ø 有利于推荐结果的发散,避免推荐结果越来越局限于单一类型
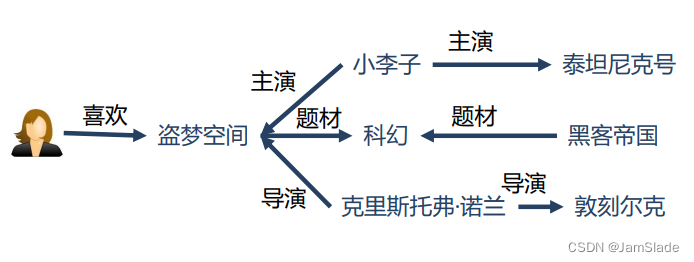
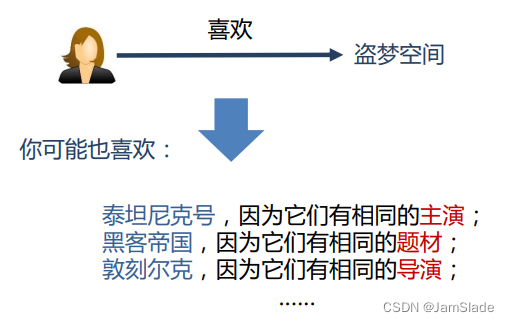
增加可解释性(interpretability)
Ø 知识图谱可以连接用户的兴趣历史和推荐结果
Ø 提高用户对推荐结果的满意度和接受度,增强用户对推荐系统的信任
知识图谱应用:问答
• 问答系统正成为人机知识交互的主要形式之一。
• 问答系统需要丰富的知识作为支撑
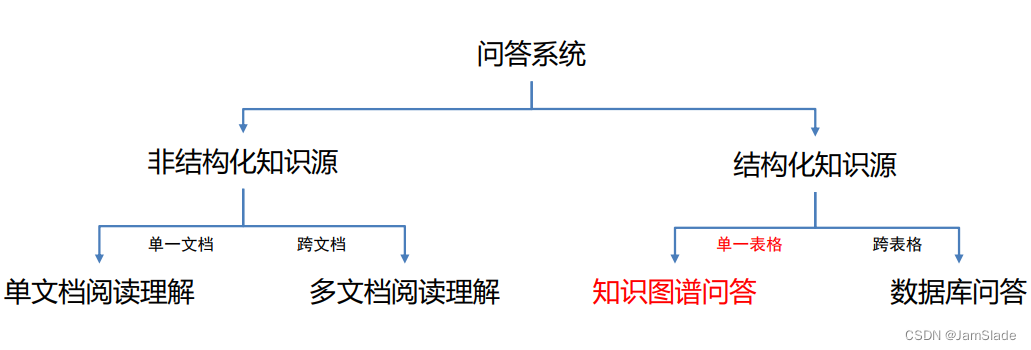
• 问答系统可以基于其知识源进行划分。
• 知识图谱是结构化知识源
事实型问题
Ø When was Barack Obama born?
• 是非型问题
Ø Is Beijing the capital of China?
• 对比型问题
Ø Which city is larger, Shanghai or Beijing?
前三者为事实类问题,为核心
• 原因/结果/方法型问题
Ø How to open the door?
• 观点型问题
Ø What is Chinese opinion about Donald Trump?
• 对话型问题
• 将自然语言问题转化为知识图谱上的结构化查询(如SPARQL或SQL)
Ø 查询语言由数据库决定,不是核心问题
• 核心问题:属性理解
优势
• 为问题的语义理解提供了丰富的背景知识
Ø 纯文本:字符、词法与语义理解
Ø 知识图谱: 关联性数据,提供文本背后的知识信息
• 提供了初步的推理能力
Ø 基于知识图谱的关系推理,问答系统可以回答知识图谱没有直接表达的事实。
• When was Barack Obama’s wife born
• 基于模式的关系抽取
• 字符模式、语法模式、语义模式
• 人工定义模式 VS. 自动学习模式(Bootstrapping)
• 基于模式抽取的质量评估:模式的置信度、实例与模式的匹配程度
• 基于学习的关系抽取:
• 学习过程:传统机器学习方法 VS. 深度学习方法
• 特征定义:词法、句法、语义、其他特征
• 知识图谱应用:
• 基于知识图谱的搜索
• 基于知识图谱的推荐
• 基于知识图谱的问答


















 1448
1448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









