







前言
前面学会了估算大模型训练所需要的算力,那么好事者就开始思考:在算力固定的前提下,如何权衡训练样本(Token)和模型参数(Size)两者的资源分布,毕竟两者相乘的6倍为一次训练所需的总算力,因此Token和Size的分布也就成了跷跷板。其实本章节最重要的信息就是Chincilla Scaling Law,也即为大模型的参数和训练样本的最佳比例大差不差的在1:20,1个参数对应20个训练Token。

研究方向一
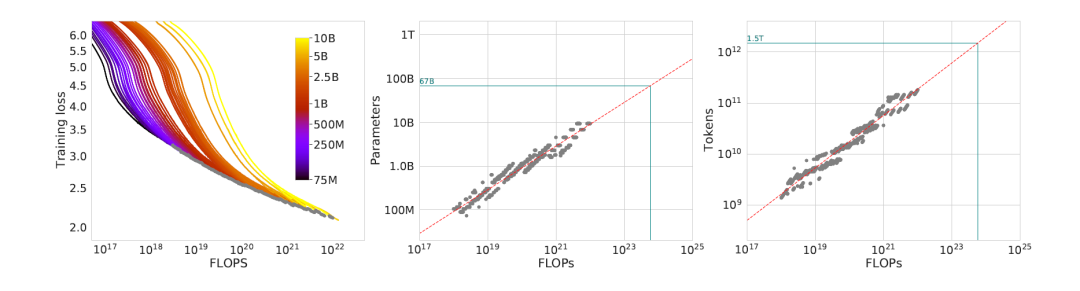
长期以来的数学研究标明,研究复杂问题按照固定部分参数,分别细究各个因子最为有效。研究者首先固定了模型参数,选择了一个家族的模型,这些模型的参数范围在70M到10B。然后给这些模型喂给不同数目的训练样本(Tokens)。
结果从上图右一可以发现:随着喂给的训练样本增加(x轴代表总算力),损失越来越小(效果越好)。从右一的图中将某个总算力C,找到6*N*D=C的所有配对,取出损失最小(效果最优)的那对组合绘制出后面的两幅图。研究结果发现不同算力下,最优的模型参数规模和训练样本数目与总算力C的α和β次方成正比。α和β的取值分别为0.5和0.5。

研究方向二
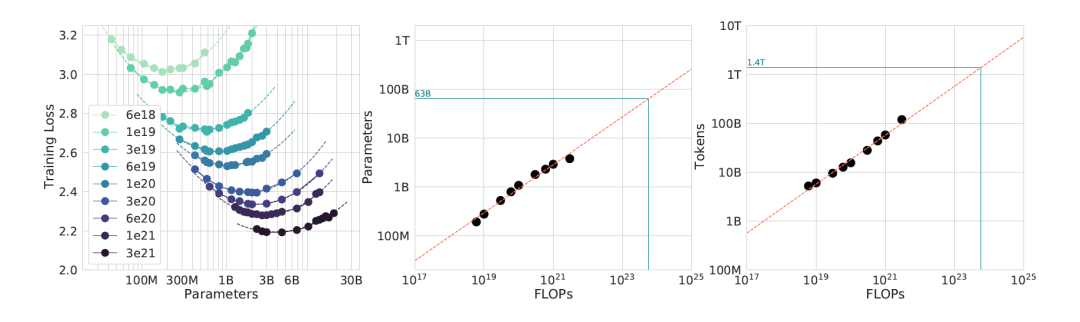
紧接着的固定算力C,因为模型参数规模和训练样本数目成跷跷板,因此模型规模越大,喂给的样本就越小。
图一的任何一条微笑曲线,线上的点越往左则是小模型大样本,越往右则是大模型小样本。任何一条曲线的代表相同算力,图一将各条微笑曲线最靠近下面的配置取出,这些最优配置也可以绘制出后面的两幅图。从图中看出最优的模型参数规模和训练样本也与总算力C的α和β次方成正比。此时α和β的取值分别为0.49和0.51。

研究方向三

在第一和第二的研究成果上面,最终研究人员提出了一个公式。这个公式将模型训练的优异和模型参数规模、训练样本总数联系了起来:
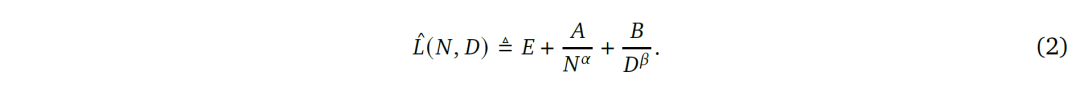
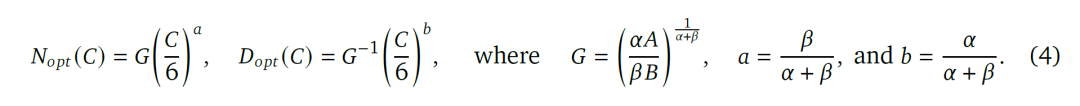
L代表损失,当然数值越小越好,N代表模型参数规模,D代表训练样本总数,其余的为等待求解的参数。
研究人员将1和2的数据采用数学的方法针对上面的公式进行拟合,结果也绘制出一副花花绿绿的汇总图,然后补上了类似组合投资的最佳有效前沿线(图中蓝线)。从最终的结果来看α和β的取值,分别为0.46和0.54。

最佳配置
三个研究告诉我们在总算力C下面,模型参数规模和训练样本数量的最佳选择与总算力C的α和β次方成正比。因此在某个固定的总算力C下,可以找到模型参数和训练样本数量的最优组合。研究者提出了如下最优的模型训练配置:

从图中可以看到,若要训练1Trillion以上的大模型,最好得拥有10^26FLOPS,不然就别想了,否则训练后也拿不到最优的模型。
故事还没有结束,好事者发现Gopher这个模型,若按照训练它的总算力结合研究成果,它其实只需要63B的参数,以及1.4T的样本即可以达到最优的效果。然后Gopher居然有280B的参数,样本数却低于1.4T。
本着看热闹的不嫌事大的精神,好事者决定用Gopher等同的训练总算力,然后按照最佳配置训练新的模型Chinchilla和Gopher比比看,进而证明研究是有效的。

上图列出了Chincilla的模型参数70B,训练样本1.4T(样本内容从训练Gopher样本中增益产生),和之前的Gopher比较,CC属于小模型大样本,Gopher属于大模型小样本。

Gopher和Chinchilla的模型结构与基本参数
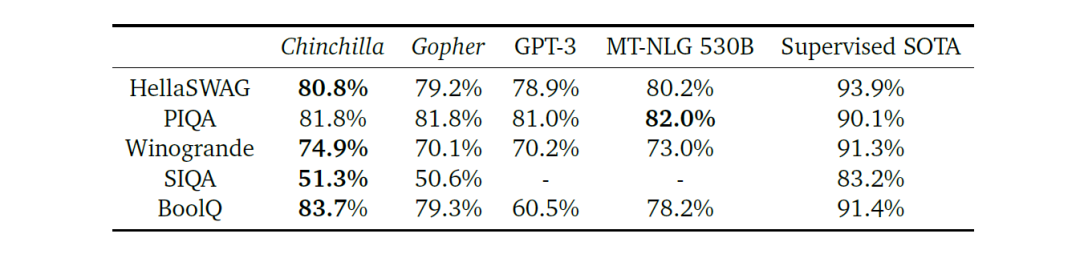
对决开始了,Chincilla除了在仅有的几项表现不佳,其余的丝毫不落下风。Chincilla Law也正式的付出水面。
|
|
|















 3086
3086











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









