







大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调重新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于构建生产级别架构则可以关注AI架构设计专栏。技术宅麻烦死磕LLM背后的基础模型。
FlashAttention属于AI加速器,要读懂它需要先具备Transformer的背景知识以及注意力机制,最后才到FlashAttention。随着大模型优化技术的层出不穷,里面的kernel fusion技术将会越来越频繁的被提及,例如在Mamba中也被用于加速。因此借着FlashAttention的这个机会更加深入的了解下GPU。

回顾FlashAttention
传统注意力机制的Q、K、V的运算都是按照下面的步骤进行。先是计算S和P,进而计算O,存在多次和HBM交互的过程(读写速度1.5T/s),容量40G再进行运算。

而FlashAttention就是想利用SRAM的高速读写(19T/s)来加速,但是SRAM的容量只有20M,如何应对起步价都是4k+的上下文序列。
聪明的读者肯定会想到将Q切分为N块,K和V切分为M块进行局部计算,如上图所示。这样的好处其一在于避免将数据频繁的从HBM加载,其二可以支持超长序列。
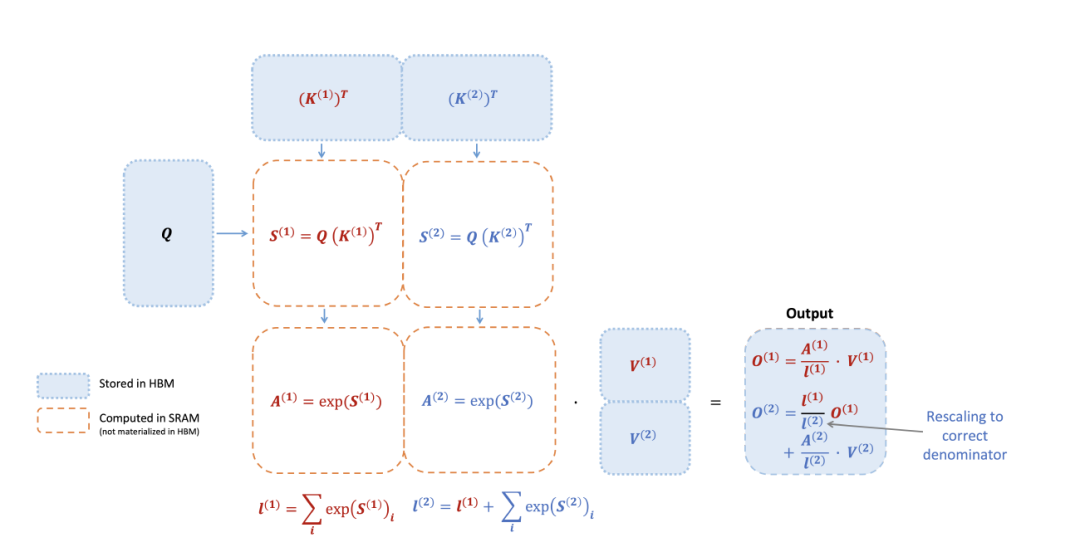
将大矩阵切分计算的思路相信读者都会想到,然而麻烦点在于注意力机制的运算需要将原来矩阵的行数值进行累加操作。要是切块计算,势必需要算法来支撑。
FlashAttention最终设计了一套分而治之的算法,将大的矩阵切块加载到SRAM,计算每个分块的m和l值。利用上一轮m和l结合新的子块迭代计算,最终算出整个矩阵的数值。整个过程不用存储中间变量S和P矩阵,因此节省了效率。
下面为算法的矩阵表示方法:

例如:


改进点1:减少非矩阵运算
FlashAttention2对FlashAttention的改进主要在于减少了非矩阵乘法运算,以A100为例,其FP16/BF16矩阵乘法的最大理论吞吐量为312TFLOPs/s,但FP32非矩阵乘法仅有19.5TFLOPs/s,即每个no-matmul FLOP比mat-mul FLOP昂贵16倍,所以第一个改进点就是调整原来算法中非矩阵运算的地方。
FlashAttention-2的算法图如下:

它在算法上相对于FlashAttention做了如下的调整:在做Attention计算局部数值的时候,Oi暂时不考虑分母,因此在嵌套计算O的时候就不需要做除法缩放,而是在最后一把调整。
|
|
|
| 原来 | 现在 |


因此原来每次更新O需要在上一轮Oi-1的基础上进行diag(l(1)/l(2))的缩放,现在也不需要了,只需要在过程补偿max值:

怎么理解补偿?假如将[8, 3, 2, 1, 10, 6]数组调整为每个数值减去最大值。
直接计算就是[-2, -7, -8, -9, 0, -4]。
①若分组求解,则先将它分为两个数组[8, 3, 2], [1, 10, 6],
②先求出第一组的最大值8,调整得到[8-8=0, 3-8=-5, 2-8=-6]。
③再次求出8和第二组的最大值10,此时除求出第二组,还需要针对第一组进行补偿[0+(8-10),-5+(8-10),-6+(8-10)]得到[-2, -7, -8]

改进点2:循环调整

FlashAttention会将Q按照行进行切块,而对于KV则按照列进列切块,然后进行双重的循环计算。那么问题来了谁在外循环,谁在内循环呢?
不用管下面的啰里啰嗦,本质上是因为O其实是跟着行走的。所以若以Qi为外循环(行循环),其实不断地加载Ki和Vi进来运算,相关部分的O其实可以一把搞定。若以Ki,Vi为外循环(列循环),加载Q1,...,Qr进来运算,则O要被不断地写入写出。以下为具体讲解,数学小白可以跳过。

还记得Warp?这里需要涉及GPU的知识,具体可以回到这里温习。简单的说warp是SM线程调度器(A100里面有108个SM,GPU的基本计算单元),一般一个warp管理32个线程集。
图a中的FlashAttention(列循环)将K和V切位4个列块,然后分给4个warp并行计算管理,且所有warp都可以访问Q。warp将K乘以Q得到部分Si,然后Si经过局部softmax后还需要乘以V的一部分得到Oi。每次计算完Qi还会更新数据至HBM(对上一次版本O先rescale再加上当前值)。这就导致每个warp需要从HBM频繁读写Qi以累加出总结果。这种方式被称为“split-K”方案是非常低效的,因为所有warp都需要从HBM频繁读写中间结果(Oi,mi,li)。
注意(Oi,mi,li)中的i是版本的意思,和矩阵块的下标i表示的涵义不一
图b中FlashAttention2(行循环)将对于Q的遍历移到到了外循环,K和V移到了内循环,并将Q分为4个warp,所有warp都可以访问K和V。原来FlashAttention每次内循环会导致O变化,通过写HBM更新O的数值。现在每次内循环处理的都是O(行),此时O在整个运算过程中都存储在SRAM上,远远高效于HBM。
采用了行循环之后,最大的好处是可以把这一维度的并行度从串行循环改成并行。拆分为GPU运算模型中的Thread Block。

性能
在A100 80GB的GPU上测量不同设置(有无Causal mask、head size64 或 128)下的不同注意力机制的运行时间。 结果表明FlashAttention2比FlashAttention和xformers中的FlashAttention快约2倍。 FlashAttention2在前馈中比Triton中的FlashAttention快约1.3-1.5 倍,在后馈中快约2倍。与PyTorch中的标准实现相比,FlashAttention2的速度最高可提高10倍。

Causal mask通常用于描述在序列模型(如Transformer)中,用来屏蔽当前时间步后面的信息。在自注意力机制(self-attention mechanism)中,模型会根据序列中所有位置的信息来计算当前位置的表示。但在某些任务中,特别是语言建模和文本生成任务中,模型只能依赖当前时间步之前的信息,而不能利用未来的信息。这时就需要遮蔽未来的信息。通常,causal mask 是一个上三角矩阵,其中对角线及对角线以下的元素都是1,而对角线以上的元素都是0。这样做的效果是,在进行自注意力计算时,模型只会看到当前时间步及之前的信息,而不会看到之后的信息,从而保证了模型在预测时不会依赖未来信息。


闲谈后馈
对于这个注意力机制的反向传播链如下,这里假设dO∈R𝑁×𝑑是O基于某种损失函数计算出来的梯度,它需要反向传播更新其他参数。
大白话就是拿到dO的值按照下列的式子,从上往下代入求出每个矩阵需要更新的值。
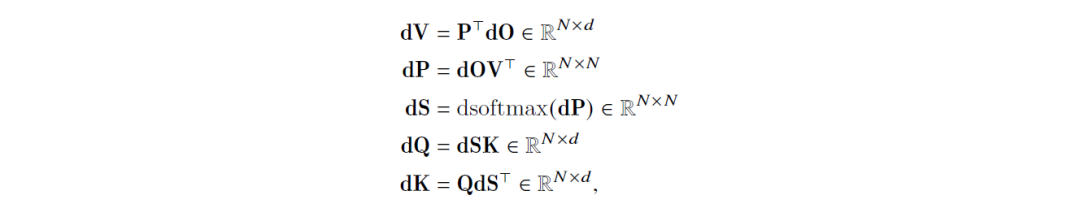
值得一提的是在FlashAttention2中,前馈已经改成行循环,而后馈还是采用列循环如下。















 897
897











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









