









导读:数学基础知识蕴含着处理智能问题的基本思想与方法,也是理解复杂算法的必备要素。今天的人工智能技术归根到底都建立在数学模型之上
小编整理了有关人工智能的资料,有python基础,图像处理opencv\自然语言处理、机器学习
数学基础等资源库,想学习人工智能或者转行到高薪资行业的,大学生也非常实用,无任
何套路免费提供,,加我裙【966367816】下载,或者扫码+vx 也可以领取的内部资源,人工智能题库,大厂面试题 学习大纲 自学课程大纲还有200G人工智能资料大礼包免费送哦~
正态分布(Normal distribution)
正态分布(Normal distribution)又名高斯分布(Gaussian distribution),是一个在数学、物理及工程等领域都非常重要的概率分布,在统计学的许多方面有着重大的影响力。若随机变量服从一个位置参数、尺度参数的概率分布,记为:则其概率密度函数为正态分布的数学期望值或期望值等于位置参数,决定了分布的位置;其方差的开平方或标准差等于尺度参数,决定了分布的幅度。

正态分布(Normal distribution)是一种概率分布。正态分布是具有两个参数μ和σ^2的连续型随机变量的分布,第一参数μ是遵从正态分布的随机变量的均值,第二个参数σ^2是此随机变量的方差,所以正态分布记作N(μ,σ^2 )。遵从正态分布的随机变量的概率规律为取 μ邻近的值的概率大 ,而取离μ越远的值的概率越小;σ越小,分布越集中在μ附近,σ越大,分布越分散。
正态分布的密度函数的特点是:关于μ对称,在μ处达到最大值,在正(负)无穷远处取值为0,在μ±σ处有拐点。它的形状是中间高两边低 ,图像是一条位于x 轴上方的钟形曲线。当μ=0,σ^2 =1时,称为标准正态分布,记为N(0,1)。
μ维随机向量具有类似的概率规律时,称此随机向量遵从多维正态分布。多元正态分布有很好的性质,例如,多元正态分布的边缘分布仍为正态分布,它经任何线性变换得到的随机向量仍为多维正态分布,特别它的线性组合为一元正态分布。

基本术语:
正态分布应用最广泛的连续概率分布,其特征是“钟”形曲线。

附:这种分布的概率密度函数为:
⒈正态分布:若已知的密度函数(频率曲线)为正态函数(曲线)则称已知曲线服从正态分布,记号 ~。其中μ、σ^2 是两个不确定常数,是正态分布的参数,不同的μ、不同的σ^2对应不同的正态分布。
正态曲线呈钟型,两头低,中间高,左右对称,曲线与横轴间的面积总等于1。
2.特征:服从正态分布的变量的频数分布由μ、σ完全决定。
集中性:正态曲线的高峰位于正中央,即均数所在的位置。对称性:正态曲线以均数为中心,左右对称,曲线两端永远不与横轴相交。
均匀变动性:正态曲线由均数所在处开始,分别向左右两侧逐渐均匀下降。
正态分布有两个参数,即均数μ和标准差σ,可记作N(μ,σ²):均数μ决定正态曲线的中心位置;标准差σ决定正态曲线的陡峭或扁平程度。σ越小,曲线越陡峭;σ越大,曲线越扁平。
u变换:为了便于描述和应用,常将正态变量作数据转换。μ是正态分布的位置参数,描述正态分布的集中趋势位置。正态分布以X=μ为对称轴,左右完全对称。正态分布的均数、中位数、众数相同,均等于μ。
σ描述正态分布资料数据分布的离散程度,σ越大,数据分布越分散,σ越小,数据分布越集中。也称为是正态分布的形状参数,σ越大,曲线越扁平,反之,σ越小,曲线越瘦高。
二项式分布
基本定义:若某事件概率为p,现重复试验n次,该事件发生k次的概率为:P=C(k,n)×p^k×(1-p)^(n-k).C(k,n)表示组合数,即从n个事物中拿出k个的方法数.
基本概念:在医学领域中,有一些随机事件是只具有两种互斥结果的离散型随机事件,称为二项分类变量(dichotomousvariable)。
如对病人治疗结果的有效与无效,某种化验结果的阳性与阴性,接触某传染源的感染与未感染等。
二项分布(binomialdistribution)就是对这类只具有两种互斥结果的离散型随机事件的规律性进行描述的一种概率分布。
考虑只有两种可能结果的随机试验,当成功的概率(π)是恒定的,且各次试验相互独立,这种试验在统计学上称为贝努里试验(Bernoullitrial)。
如果进行n次贝努里试验,取得成功次数为X(X=0,1,…,n)的概率可用下面的二项分布概率公式来描述:
(7.1)式中的n为独立的贝努里试验次数,π为成功的概率,(1-π)为失败的概率,X为在n次贝努里试验中出现成功的次数,表示在n次试验中出现X的各种组合情况,在此称为二项系数(binomialcoefficient)。
所以的含义为:含量为n的样本中,恰好有例阳性数的概率。
含量为n的样本中,发生各种阳性数的概率正好为下列二项式展开的各项




泊松分布
公式:当二项分布的n很大而p很小时,泊松分布可作为二项分布的近似,其中λ为np。通常当n≧10,p≦0.1时,就可以用泊松公式近似得计算。

泊松分布(Poisson distribution)是一种统计与概率学里常见到的离散机率分布(discrete probability distribution)。泊松分布是以18-19 世纪的法国数学家西莫恩·德尼·泊松(Siméon-Denis Poisson)命名的,他在1838年时发表。但是这个分布却在更早些时候由贝努里家族的一个人描述过。

应用:泊松分布适合于描述单位时间(或空间)内随机事件发生的次数。如某一服务设施在一定时间内到达的人数,电话交换机接到呼叫的次数,汽车站台的候客人数,机器出现的故障数,自然灾害发生的次数,一块产品上的缺陷数,显微镜下单位分区内的细菌分布数等等。
观察事物平均发生m次的条件下,实际发生x次的概率P(x)可用下式表示:
P(x)=(m^x/x!)*e^(-m)
p ( 0 ) = e ^ (-m)
称为泊松分布。例如采用0.05J/m2紫外线照射大肠杆菌时,每个基因组(~4×106核苷酸对)平均产生3个嘧啶二体。实际上每个基因组二体的分布是服从泊松分布的,将取如下形式:
P(0)=e^(-3)=0.05;
P(1)=(3/1!)e^(-3)=0.15;
P(2)=(3^2/2!)e^(-3)=0.22;
P(3)=0.22;
P(4)=0.17;……
P(0)是未产生二体的菌的存在概率,实际上其值的5%与采用0.05J/m2照射时的大肠杆菌uvrA-株,recA-株(除去既不能修复又不能重组修复的二重突变)的生存率是一致的。由于该菌株每个基因组有一个二体就是致死量,因此P(1),P(2)……就意味着全部死亡的概率。
均匀分布
对于投骰子来说,结果是1到6。得到任何一个结果的概率是相等的,这就是均匀分布的基础。与伯努利分布不同,均匀分布的所有可能结果的n个数也是相等的。
如果变量X是均匀分布的,则密度函数可以表示为:

均匀分布曲线

你可以看到,均匀分布曲线的形状是一个矩形,这也是均匀分布又称为矩形分布的原因。其中,a和b是参数。花店每天销售的花束数量是均匀分布的,最多为40,最少为10。我们来计算一下 日销售量在15到30之间的概率。日销售量在15到30之间的概率为(30-15)*(1/(<40-10))= 0.5同样地,日销售量大于20的概率为= 0.667
卡方分布
若n个相互独立的随机变量ξ1,ξ2,…,ξn ,均服从标准正态分布(也称独立同分布于标准正态分布),则这n个服从标准正态分布的随机变量的平方和∑ξi∧2构成一新的随机变量,其卡方分布分布规律称为χ2(n)分布(chisquare distribution),其中参数 n 称为自由度,自由度不同就是另一个χ2分布,正如正态分布中均值或方差不同就是另一个正态分布一样。χ2分布的密度函数比较复杂这里就不给出了,同学们也不用去记了。卡方分布是由正态分布构造而成的一个新的分布,这也正反映了前面所说的正态分布的重要性。对于任意正整数k, 自由度为 k的卡方分布是一个随机变量X的机率分布。
特点:χ2分布在一象限内,呈正偏态,随着参数 n 的增大,χ2分布趋近于正态分布。
χ2分布的均值为自由度 n,记为 Eχ2=n,这里符号“E”表示对随机变量求均值;χ2分布的方差为2倍的自由度(2n),记为 Dχ2=2n,这里符号“D”表示对随机变量求方差。从χ2分布的均值与方差可以看出,随着自由度n的增大,χ2分布向正无穷方向延伸(因为均值n越来越大),分布曲线也越来越低阔(因为方差2n越来越大)。
χ2分布具有可加性:若有K个服从χ2分布且相互独立的随机变量,则它们之和仍是χ2分布,新的χ2分布的自由度为原来K个χ2分布自由度之和。表示为:
χ2分布是连续分布,但有些离散分布也服从χ2分布,尤其在次数统计上非常广泛。

性质:(1)卡方分布曲线下的面积都是1;
(2)卡方值都是正值;
(3)卡方分布是一个正偏态分布;
(4)不同的自由度决定不同的卡方分布,自由度越小,分布越偏斜。
beta分布
beta分布可以看作一个概率的概率分布,当你不知道一个东西的具体概率是多少时,它可以给出了所有概率出现的可能性大小
概率论中还有一种称为贝塔(β,beta)分布的概率密度分布函数。它的数学形式是
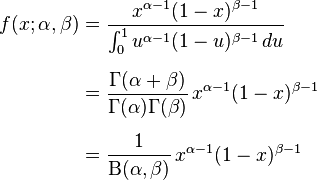
,0<x<1, p>0,q>0 (18.25)
这里的变量x仅能出现于0到1之间,p,q是两个大于0的参数。B(p,q) 的含义是(18.26)
它与Γ函数,有如下关系(18.27)
而我们介绍过的阶乘符号!与Γ的关系是n!= Γ(n+1)
所以贝塔分布也可以写为(18.28)
现在考虑从最复杂原理加适当的约束条件推求这个概率密度分布函数的问题。根据过去的经验,容易看出它可能是下面两个约束条件与最复杂原理的应用结果。
变量x的对数的平均值为固定值(等价于几何平均值为常数):(18.29)
(1-x)的对数的平均值也是固定之值:(18.30)
作为概率密度,当然还有(18.31)
根据上面的三个约束公式和最复杂原理,利用拉格朗日方法,构造的F函数是
求F对未知的概率密度f的偏微商,并且令它等于0(利用了最复杂原理),我们得到
利用分布函数的积分应当等于1的约束和积分知识我们得到
所以分布函数可以写为(18.32)
显然,这个公式的外型已经与贝塔分布一致了。余下的问题是利用关于u,v的约束公式可以求出C2,C3 。使这个公式通过u,v来表示。由于u,v与C2,C3的关系比较复杂,我们没有得到具体的关系式。但是概率密度分布函数的形状与概率论中的贝塔分布一致就已经达到了我们的目的:界于0-1之间的变量的两种几何平均值固定和最复杂原理相结合可能是一些贝塔分布形成的原因。
贝塔分布中的变量x的变化范围仅能在0到1之间,而且(1-x)与x有对称性,这是重要的特点。
举例:
熟悉棒球运动的都知道有一个指标就是棒球击球率(batig average),就是用一个运动员击中的球数除以击球的总数,我们一般认为0.266是正常水平的击球率,而如果击球率高达0.3就被认为是非常优秀的。现在有一个棒球运动员,我们希望能够预测他在这一赛季中的棒球击球率是多少。你可能就会直接计算棒球击球率,用击中的数除以击球数,但是如果这个棒球运动员只打了一次,而且还命中了,那么他就击球率就是100%了,这显然是不合理的,因为根据棒球的历史信息,我们知道这个击球率应该是0.215到0.36之间才对啊。对于这个问题一个最好的方法就是用beta分布,这表示在我们没有看到这个运动员打球之前,我们就有了一个大概的范围。beta分布的定义域是(0.1)这就跟概率的范围是一样的。接下来我们将这些先验信息转换为beta分布的参数,我们知道一个击球率应该是平均0.27左右,而他的范围是0.21到0.35,那么根据这个信息,我们可以取a=81,$=219(击中了81次,未击中219次)
点击下方小编发布的其他文章,学习更多的其他人工智能专业知识
人工智能必备数学基础(一) 人工智能必备数学基础(一)_Java_rich的博客-CSDN博客
人工智能必备数学基础(二)
人工智能必备数学基础(二)/微积分、泰勒公式与拉格朗日乘子法_Java_rich的博客-CSDN博客
人工智能常用的十大算法
人工智能的常用十种算法_Java_rich的博客-CSDN博客
小编整理了有关人工智能的资料,有python基础,图像处理opencv\自然语言处理、机器学习
数学基础等资源库,想学习人工智能或者转行到高薪资行业的,大学生也非常实用,无任
何套路免费提供,,加我裙【966367816】下载,或者扫码+vx 也可以领取的内部资源,人工智能题库,大厂面试题 学习大纲 自学课程大纲还有200G人工智能资料大礼包免费送哦~
欢迎大家扫码撩我呀~


















 1149
1149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









