






2月4日凌晨,Chatbot Arena LLM Leaderboard更新了最新一期的榜单,不久前发布的Qwen2.5-Max直接冲进前十,超越DeepSeek V3, o1-mini和Claude-3.5-Sonnet等模型,以1332分位列全球第七名!同时,Qwen2.5-Max在数学和编程上排名第一,在Hard prompts方面排名第二。
https://lmarena.ai/?leaderboard
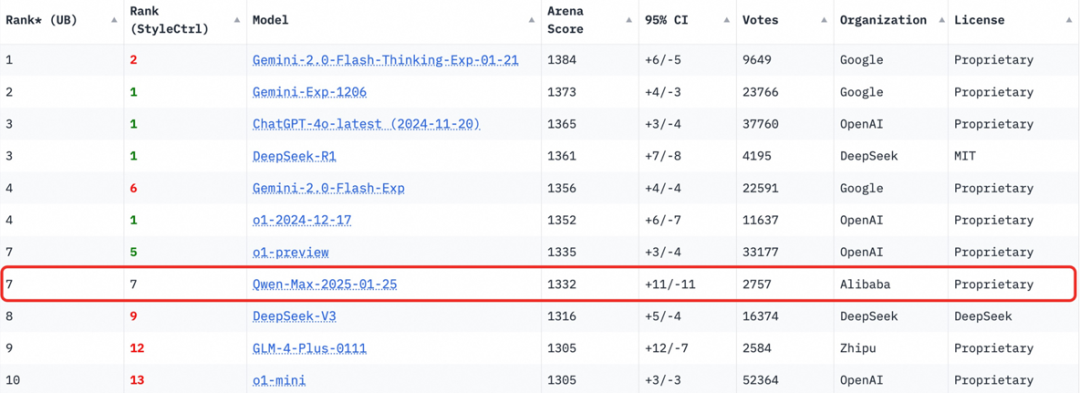

Qwen-Max是阿里云通义团队对MoE模型的最新探索成果,新模型展现出极强劲的综合性能。在Arena-Hard、LiveBench、LiveCodeBench、GPQA-Diamond及MMLU-Pro等主流基准测试中,Qwen2.5-Max比肩Claude-3.5-Sonnet,并几乎全面超越了GPT-4o、DeepSeek-V3及Llama-3.1-405B。
ChatBot Arena官方账号 lmarena.ai 对其评价称,阿里巴巴的Qwen2.5-Max在多个领域表现强劲,特别是在专业技术向的(编程、数学、有难度的提示词等)方面。
据了解,Chatbot Arena是由LMSYS Org推出的大模型性能测试平台,目前集成了190多种模型。该榜单采用匿名方式将大模型两两组队,交给用户进行盲测,用户根据真实对话体验对模型能力进行投票。因此Chatbot Arena LLM Leaderboard成为全球顶级大模型的最重要竞技场。
此前,Qwen2.5-72B-Instruct发布后也曾闯入Chatbot Arena榜单全球前十,是得分较高的中国大模型;Qwen2-VL-72B-Instruct闯入Vision榜单第九,是成绩优异的开源模型。
目前,企业可在阿里云百炼调用Qwen2.5-Max模型的API,开发者也可在Qwen Chat平台中免费体验Qwen2.5-Max。
Qwen2.5-Max发布后,在海外开发者中引发了大量关注。有网友在对比DeepSeek-V3 和 Qwen 2.5后,高度赞扬了Qwen2.5-Max的出色表现。
还有网友打趣地为OpenAI的首席执行官Sam Altman担忧:又一个中国模型来了
不少海外网友表示,中国新模型的迭代速度和质量令人惊艳。

作为国内较早开源自研大模型的科技大厂,阿里云旗下的通义千问已实现全尺寸、全模态的开源,推出了包括语言大模型、多模态大模型等多种类型的开源模型。
在全球范围内,Qwen的衍生模型数量超9万个,已超越Llama成为全球更大的开源模型群。此次Qwen2.5-max的发布,亦备受全球各种语言的开发者的欢迎。
“有了Qwen2.5-max,我们能对ChatGPT说再见了?!”有使用阿拉伯语的网友如是说。
多名海外网友用英文表达了对Qwen2.5-max极致性能的惊叹。
通义团队方面表示,持续提升数据规模和模型参数规模能够有效提升模型的智能水平。通义团队对下一个版本的Qwen2.5-Max充满信心,也将持续探索,除了在预训练的scaling 上继续探索外,还将大力投入强化学习的scaling,希望能实现超越人类的智能,驱动AI探索未知之境。
## AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2025最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2025最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2025最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2025最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2025最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 1113
1113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









