








图片来源:Unsplash 上的 Agence Olloweb
引言
机器学习模型的选择一直是一个挑战。无论是预测股票价格、诊断疾病,还是优化营销活动,问题始终是:哪个模型最适合我的数据? 传统上,我们依赖交叉验证来测试多个模型——XGBoost、LGBM、随机森林等——然后根据验证性能选择最佳模型。但如果数据集的不同部分需要不同的模型呢?或者,如果动态融合多个模型可以提高准确率呢?
这个想法是在我阅读Deepseeker R1(一种先进的大型语言模型,能够动态调整以提高性能)时产生的。受其基于强化学习(RL)的优化方法启发,我开始思考:我们是否可以在监督学习中应用类似的 RL 策略?与其手动选择模型,为什么不让强化学习自动学习出最佳策略?
想象一个强化学习代理就像一个数据科学家——分析数据集的特征,测试不同的模型,并学习哪些模型表现最佳。更进一步,它不仅仅选择一个模型,还可以根据数据模式动态融合多个模型。例如,在金融数据集中,XGBoost 可能擅长处理结构化趋势,而 LGBM 可能更适合捕捉变量间的交互关系。我们的 RL 系统可以智能地在它们之间切换,甚至自适应地组合它们。
本论文提出了一种全新的强化学习驱动的模型选择与融合框架。我们将这个问题建模为一个马尔可夫决策过程(MDP),其中:
• 状态(state) 表示数据集的特征统计信息。
• 动作(action) 代表选择或融合不同的机器学习模型。
• 奖励(reward) 取决于模型的表现。
• 策略(policy) 通过强化学习训练,以找到最佳的模型选择策略。
与传统方法不同,本方法不会对整个数据集应用单一最优模型,而是学习针对不同数据片段选择最佳模型,甚至动态融合模型。这一方法可以自动化、优化并个性化机器学习流程——减少人工干预,同时提升预测性能。
在本文的最后,我们将看到,强化学习如何彻底改变模型选择,让其更自适应、更智能、更高效——就像一个不断学习和优化决策的专业数据科学家。
方法论:用于监督学习的自适应强化学习模型选择
我们将机器学习模型的自适应选择与融合定义为马尔可夫决策过程(MDP),其由五元组 (S, A, P, R, γ) 组成:
• S(状态):表示当前数据集的统计摘要(例如特征的均值和方差)。
• A(动作):对应于选择单个模型 {XGB, LGBM, RF, DNN, Blend}。
• P(s′∣s, a)(状态转移概率):从当前状态 s 转移到下一状态 s′ 的概率。
• R(s, a)(奖励):在状态 s 下执行动作 a 后获得的即时奖励。
• γ ∈ [0,1](折扣因子):权衡即时奖励与未来奖励的影响。
强化学习代理的目标是学习一个最优策略 π*(s),使得累积奖励最大化:
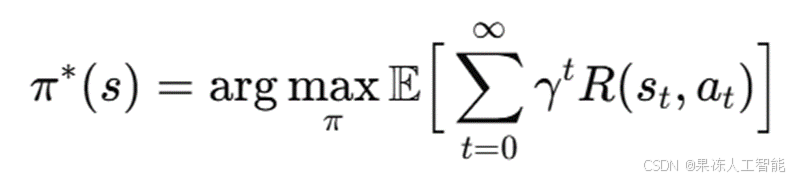
其中,奖励 R(s, a) 计算如下:
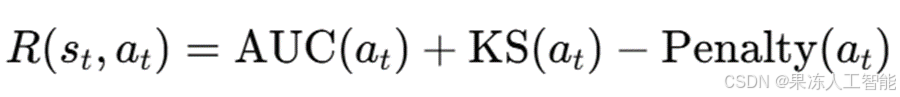
AUC 和 KS 评估模型的预测性能,而复杂度惩罚用于控制模型复杂度(例如,对 DNN 或模型融合策略施加更高的惩罚)。
状态表示与动作空间
在许多情况下,状态 s 由数据集的特征级摘要定义,例如:
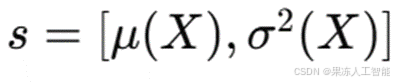
其中,μ(X) 是特征均值,σ(X) 是特征方差。
动作 a_t 可以是选择单个模型(如 XGB),也可以是多个模型的加权融合:
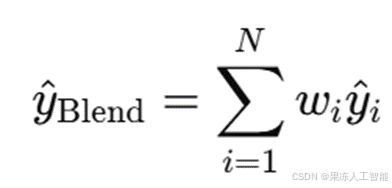
其中,w_i 是融合权重,y^i 是模型 i 的预测概率。
Q 学习与模型评估
强化学习的核心是估计状态-动作值函数 Q(s, a),它表示从状态 s 采取动作 a 并遵循策略 π 后的期望累计奖励。该函数可以表示为:
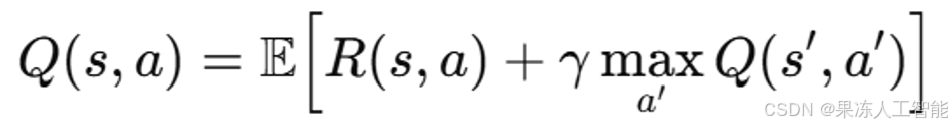
其中,R(s, a) 是模型的即时奖励(基于 AUC + KS - 复杂度惩罚),γ 是折扣因子,决定了未来奖励的权重。强化学习的目标是通过智能选择模型来最大化这个累积奖励,并随着数据的变化不断调整。
多臂老虎机方法:无需复杂计算的快速模型选择
多臂老虎机(Multi-Armed Bandit,MAB)方法将问题视为无状态、无记忆的情况,其中每次行动的奖励是相互独立的。在本文的背景下,每个动作 a 都是一个候选模型(如 XGBoost 或 LightGBM),或者是多个模型的融合。当采取某个动作 a 时,我们可以立即观察到奖励 R(a),该奖励基于所选模型在 AUC 和 KS 等指标上的表现。
Q 值的更新规则如下:

其中:
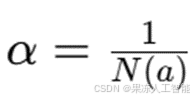
是学习率,N(a) 代表模型 a 被选择的次数的倒数。
ε-贪心(epsilon-greedy)策略 确保了探索较少使用的模型,同时利用当前表现最好的模型:
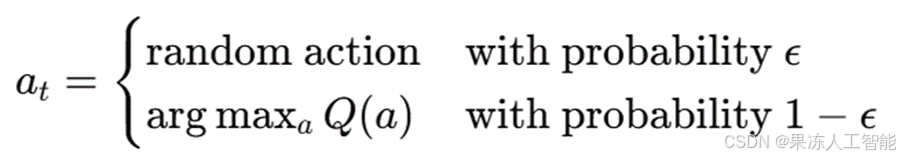
例如,在训练的早期,MAB 可能会探索 DNN 或融合模型。但如果 XGBoost 一直能获得较高的 AUC 且惩罚最小,则 MAB 代理会逐渐倾向于更多地选择 XGBoost。这种方法在模型表现不依赖于数据状态的情况下效果较好。
深度 Q 网络(DQN)方法:当状态转换重要时
不同于 MAB 方法,DQN 方法可以考虑状态的变化和长期的奖励。在本文中,状态 s 由数据集的统计特征(均值、方差等)定义,并且会随时间变化,例如数据分布的漂移。
强化学习代理的任务是在当前状态 s 下选择最优模型,同时预测未来状态 s′ 及其可能的奖励变化。Q 值的估计由深度神经网络 Q(s, a; θ) 近似计算,其中 θ 是网络参数。
训练 DQN 需要最小化时间差分(TD)误差:
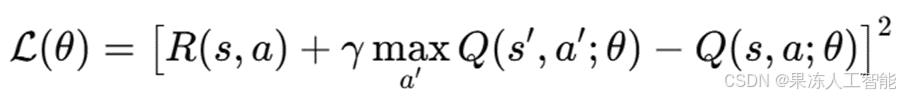
训练 DQN 时采用经验回放(experience replay):
• 存储 过去的状态-动作-奖励-新状态 (s, a, r, s') 经验到缓冲区中。
• 随机抽取 过去的经验进行训练,防止神经网络过拟合到最近的样本。
这种方法的一个典型案例是:
• 假设当前状态 s 代表一个包含大量噪声的金融数据集,并且特征之间有强相关性(多重共线性)。 在这种情况下,简单模型(如随机森林)可能无法有效处理数据,因此 DQN 代理可能学会避免选择随机森林,而更倾向于选择XGBoost + DNN 融合模型,因为它能更好地处理复杂模式。
• 随着数据状态的变化,例如噪声减少,DQN 可以自动调整策略,回归到更简单的模型,如 XGBoost 或 LGBM。
探索与利用:模型选择中的权衡
MAB 和 DQN 都依赖于ε-贪心策略来在探索(exploration)和利用(exploitation)之间取得平衡:
• MAB 方法 直接选择最优模型,适用于静态环境,但可能会忽略数据状态的变化。
• DQN 方法 通过神经网络识别数据的动态变化,适用于时序数据或流数据,但训练计算量更大。
示例说明:在 XGBoost 和融合模型之间进行选择
考虑一个不断变化的金融数据集,任务是预测贷款违约。
• 在数据的初始状态下,特征具有较强的线性可分性,因此 XGBoost 可能是最佳选择。
• 当数据集变得更加嘈杂、特征变得重叠时,融合 XGBoost 和 DNN 可能能获得更高的奖励,因为它可以更好地泛化。
• 强化学习代理不断监控过去的 AUC 和 KS 评估指标,并更新 Q 值,以适应不断变化的环境。
对比:
• 在 MAB 框架下:代理可能由于 XGBoost 在早期表现良好,而倾向于一直选择它,即便在数据变得嘈杂时也不会改变策略。
• 在 DQN 框架下:代理能够随着数据状态的变化调整策略,在数据嘈杂时选择融合模型,在数据变干净时回归到 XGBoost。
结合 MAB 和 DQN 方法
MAB 方法适用于计算效率高、奖励独立且即时的任务,如在线模型选择。
DQN 方法适用于奖励依赖于数据状态、需要长期优化的任务,如时间序列预测或金融建模。
结合两者的方法可以在各种监督学习任务中提供更强的适应能力。
数据与代码实验
我们首先使用提供的数据和代码测试多臂老虎机方法,通过动态探索和基于奖励的更新来评估模型选择的性能。
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
import torch
import torch.nn as nn
import torch.nn.functional as F
# Read the
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 888
888

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









