






前言:
📌 本文是我在研究LLM推理优化过程中做的技术梳理,结合了二十多篇论文和实际工程经验。
🔧 技术实战派|AI软硬件一体解决者
🧠 从芯片设计、电路开发、GPU部署 → Linux系统、推理引擎 → AI模型训练与应用
🚀 现在专注用10年工程经验 + 商业认知,赋能AI产品从概念到落地
📩 学AI?做AI项目?搞AI训练推理设备?欢迎关注私信。
正文:
如果你正在开发AI解决方案,部署基于大型语言模型(LLM)的基础模型,那么你就得认真考虑它们的服务成本了。但我跟你说,钱不是唯一的问题 —— 要是你搞不定模型性能的问题,就算你预算再高,也一样跑不顺LLM。这篇文章就是来讲:怎么把LLM推理,从一个“烧钱怪”变成高吞吐的引擎。
目录
- LLM服务中的难题
- 第一主题:聪明的KV缓存管理
- 第二主题:Query稀疏注意力
- 第三主题:猜测式解码
- 第四主题:权重调度
- 第五主题:系统级优化
- 其他主题
- 技术实操:这些招怎么用
LLM服务中的难题
LLM确实很牛,但它们的特点也决定了:部署起来非常难。LLM的推理过程分成两个阶段:
- 预填充(Prefilling):你一输入提示(上下文、聊天记录、问题等等),模型就会一次性处理所有的tokens。
- 解码(Decoding):初始提示处理完后,模型就会一个一个token地往外生成。新的token依赖前面的。
为了让你更容易理解,预填充就像下象棋前摆好棋盘(比较耗时),而解码就像一步一步走棋(每步很快)。
但很遗憾,LLM部署可不是“吃块蛋糕”那么轻松,有几个大坑必须避:
稀疏性(Sparsity)
在神经网络里,尤其是FFN层,很多神经值其实是0。如果我们能跳过这些0值,只处理非零元素,就能省不少计算时间。
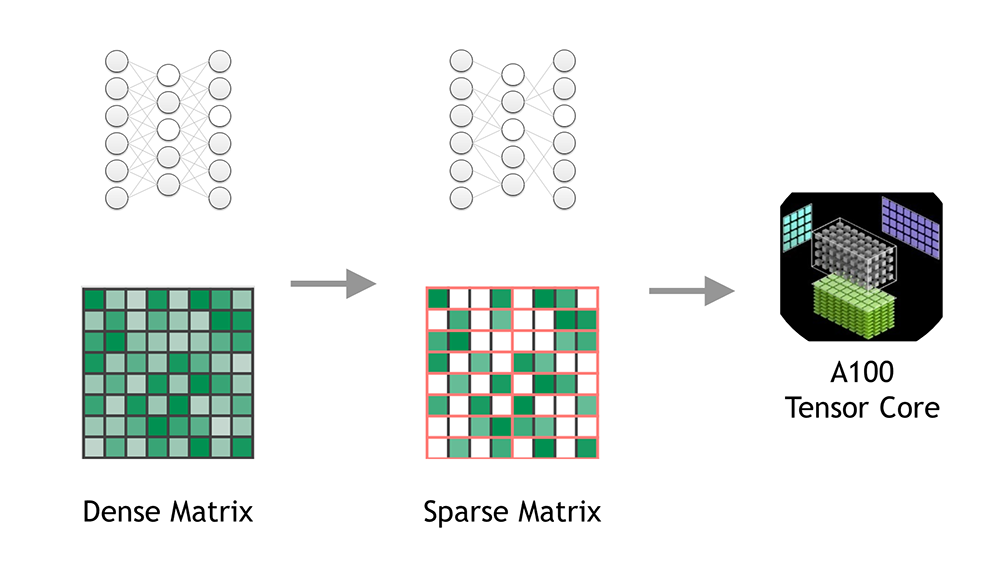 好些LLM神经值是0,导致矩阵乘法里也是零成片
好些LLM神经值是0,导致矩阵乘法里也是零成片
显存带宽瓶颈 & 内存受限(Memory Bandwidth Limits and Memory Bound)
GPU上传/下载数据的时间,常常比计算本身还久。而像ChatGPT这种传说中有一万亿参数的大模型,根本装不进单个GPU。
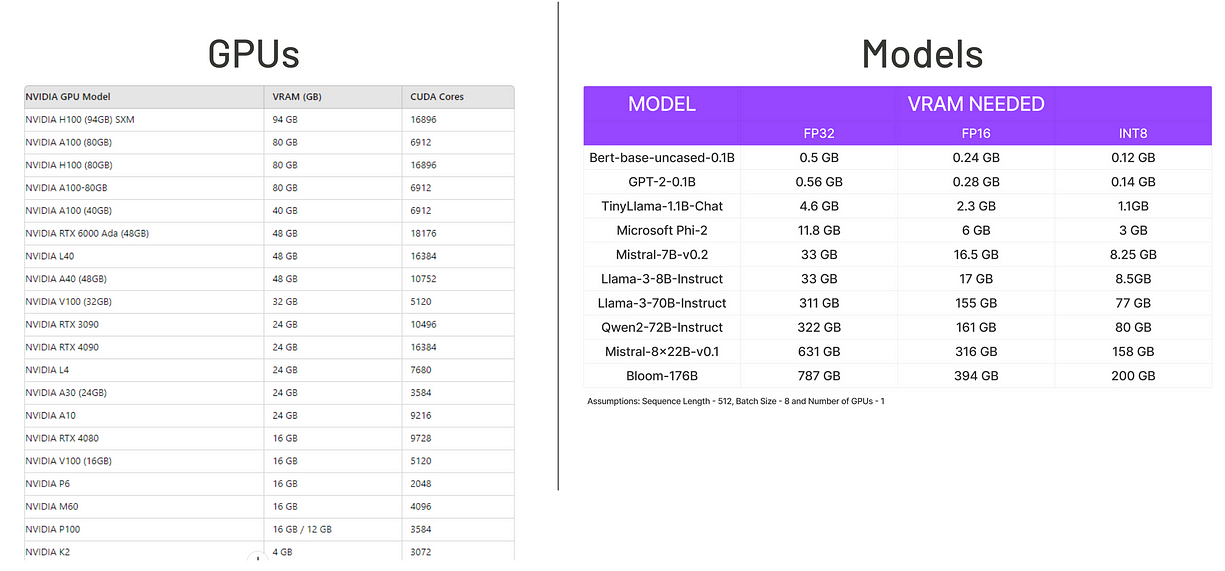 模型规模 vs GPU显存对比。
模型规模 vs GPU显存对比。
调度太差——先来先服务(Poor Scheduling)
LLM通常要同时处理多个请求。结果就是,短请求(比如问天气、时间)要等长请求处理完才轮到。这样平均响应时间全都卡在“等”上了,而不是“算”。
 你再快,也得等别人先来。
你再快,也得等别人先来。
解码是串行的(Sequential Decoding)
你没法并行生成token。每次前向传播只能出一个token(或者一小批)。这就是为啥你问ChatGPT一长段,它是一个词一个词吐出来的 —— 所以“流式输出”其实比“全生成完再给你”还舒服。
一步步解码。图源:ChatGPT
KV缓存增长(KV cache growth)
注意力计算覆盖整个序列,是LLM推理最核心也是最耗资源的操作。每次生成token时,它还要重复前面很多计算。Key-Value缓存就是帮你记住前面步骤里有用的信息。用KV cache,GPT2在T4 GPU上能加速5倍。下面图展示了有缓存和没缓存的区别。
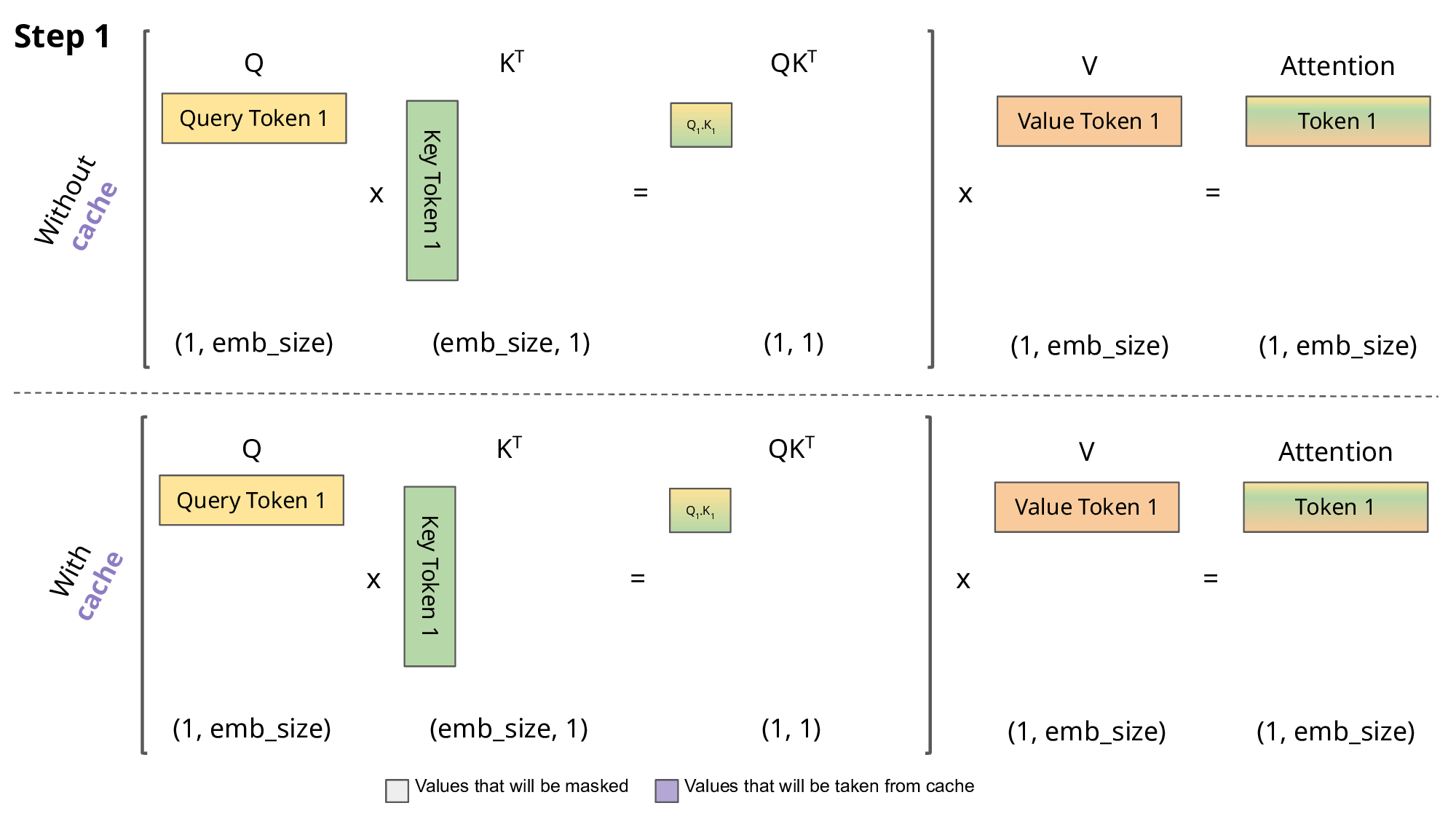
解码[token 1, token 2, token 3, token 4]时KV缓存的操作步骤。
实验表明,KV缓存的使用率在20.4%到38.2%之间。我自己用KV缓存的Qwenvl2.0跑了1万个图片的问题:“Describe the photo. Please answer short, under 20 words!” —— 最后速度提高了20%。
虽然这些机制一开始看上去很复杂,但只要设计得巧,是能变成优势的。下面我就把我从各方收集到的LLM推理优化心得,整理成了几个主题。
第一主题:聪明的KV缓存管理
页面注意力机制(Page attention)
KV缓存特别吃内存。上下文越长,KV缓存占的内存越多。比如说,有个LLM能接2048个token的输入,那它就得给2048个slot预留内存。看下面这张图:

图里是一个7个词的提示:“four, score, and, seven, years, ago, our.” 填满了2048个slot中的前7个。后面模型生成了4个词:“fathers, brought, forth, <eos>” —— 总共才用掉11个slot,剩下的2038个都空着。就这样,内存碎片就出来了。
每一步推理都要生成KV对,在用attention时把它缓存下来。KV缓存通常会被存在连续的内存块里,也就是“页面”。但一轮生成完了、内存释放之后,这些释放的页面很可能就不连续了。而下一轮推理要用的内存,可能又对不上现有的碎块,这就造成了“外部碎片”。
参考操作系统的内存管理思路,Page Attention机制把数据按逻辑块组织,用“页表”监控它们,然后映射到物理内存上。关键点如下:
- 固定大小块:PagedAttention会分配一些定长的小内存块(页)给KV缓存用。
- 块可共享:这些块可以在多个请求之间共享。
- 按需分配:推理过程中,块是边生成边分配的,不用一开始就按最大序列长度来预留。
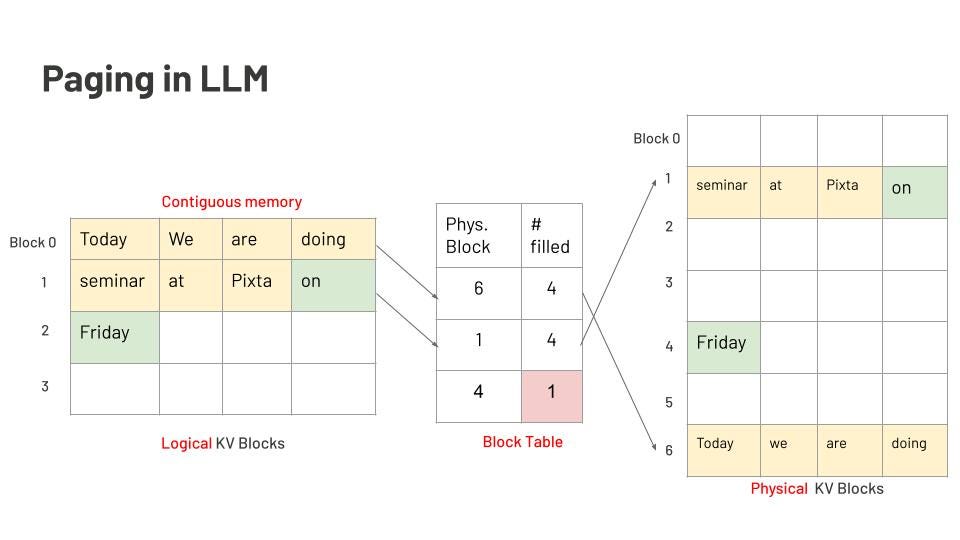
LLM中的分页机制示意图。图作者本人
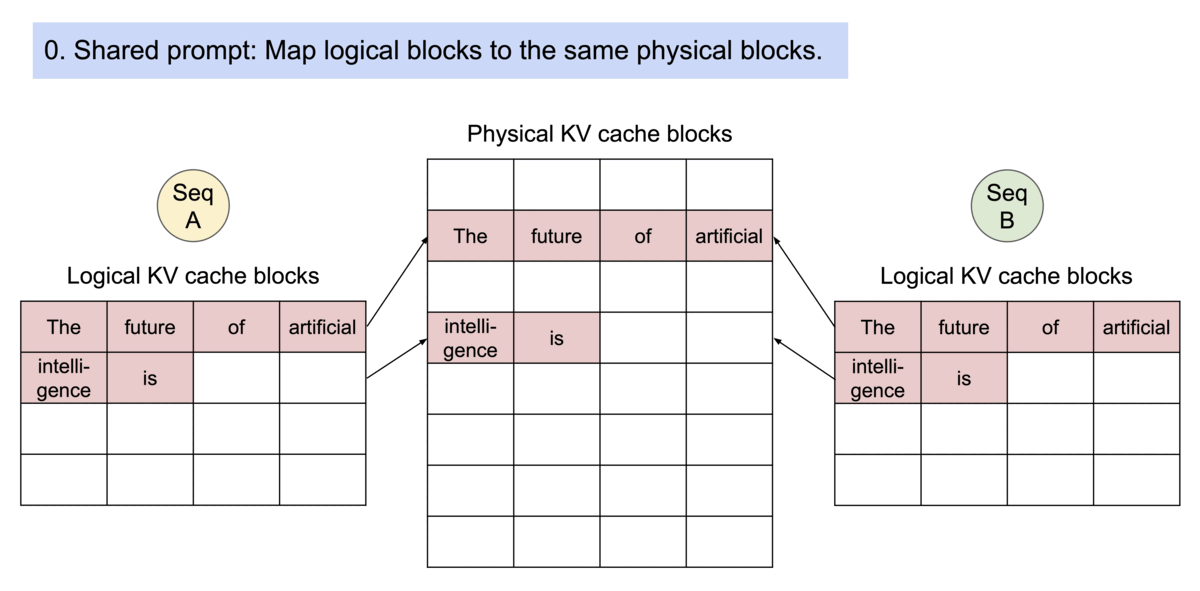
多请求共享KV缓存块的分页机制示意图。
Raddix tree KV缓存
在计算机科学中,radix树(也叫radix trie、紧凑前缀树或压缩trie)是一种空间优化的trie结构,它会把只有一个子节点的节点跟它的父节点合并。
Raddix tree KV缓存是一种能让不同推理请求之间高效复用KV缓存的技术,特别适合多个请求有相同前缀的场景。把KV缓存组织成radix树的结构,可以让我们高效地回调KV数据,并且在多个请求间轻松共享。比如下面这个例子,三个请求共享了“ABC”这个前缀,这部分存在父节点里,最后每个请求的最后一个词则分配到三个叶子节点上。记住:用树结构操作的复杂度是O(nlogn),而不是注意力机制里的O(n²)。
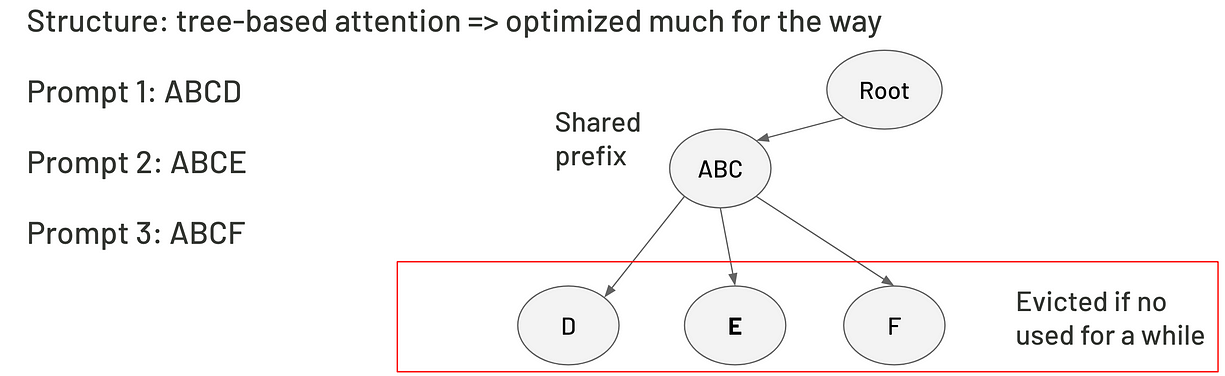
压缩注意力(Compressed attention)
多头注意力是Transformer模型的核心,也是LLM的骨干。每个头会从不同角度看文本:有的关注主语和动词的关系、有的看词语、有的看句子结构。多头机制让模型更聪明,但也意味着每个头要用自己的一套KV对。这样在处理实时文本或者长文本的时候,Key和Value分量会非常庞大,占据大量内存。
Group Query Attention(GQA)允许多个query共享Key和Value对,能减少计算attention时KV对的数量。Multi Query Attention(MQA)是最省的,因为它让多个query共享一组KV。
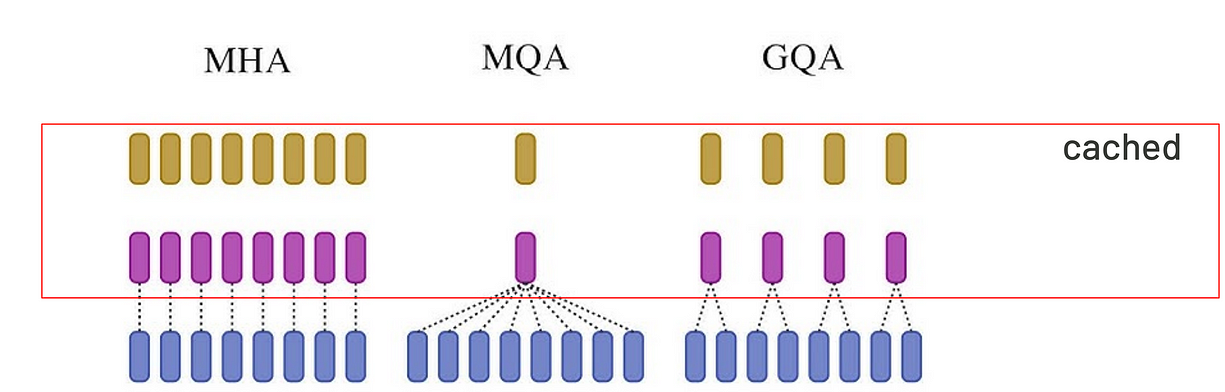
multi-head attention, multi-query attention, group-query attention
中国AI初创公司DeepSeek在今年年初发布聊天机器人后,市值暴涨到一万亿美金。他们的产品不仅快,还开源。有传言说他们是靠分析ChatGPT生成的数据才成功的。但我读完他们的技术报告后,看到的远不止“数据分析”而已。DeepSeek推出了Flash Multi Latent Attention(Flash MLA)技术,这让他们的AI科学家可以更快训练模型。它不是保存完整的K和V,而是用低秩压缩(low-rank compression)把它们投影成维度更小的latent向量,降低缓存体积。之后,在计算attention时再把它“上投影”。有趣的是,这个“上投影”的权重矩阵会和query里的矩阵权重融合(folded),让attention计算更快。
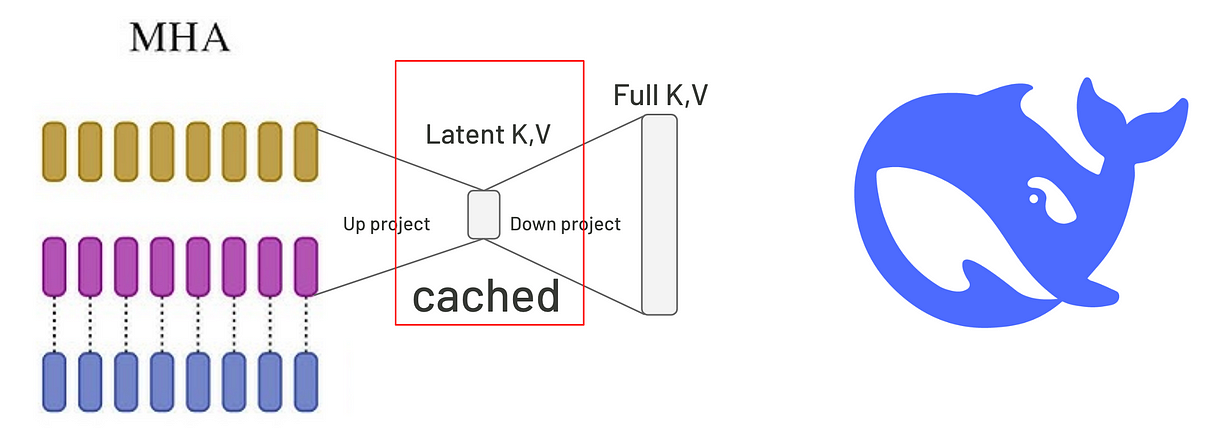
multi-head latent attention
第二主题:Query稀疏注意力(Query-sparsity attention)
QUEST:用于长上下文LLM推理的Query感知稀疏性方法
根据MIT的研究人员发表的论文《QUEST: Query-Aware Sparsity for Efficient Long-Context LLM Inference》,我们知道,在推理过程中,Transformer层中注意力计算往往是高稀疏的。意思是:大模型在推理时,并不是所有神经节点都会激活。基于这个点,之前的剪枝技术就利用过类似的想法,让大模型运行得更有效。下面这张图展示了Transformer模型中各层的稀疏度统计。不幸的是,从第三层开始,大多数层都很稀疏,最严重时像第十层甚至100%稀疏。这个现象本质上就是你在做一堆“乘0”的无效运算。
为啥会这样?其实很简单:不是每个词都对上下文有贡献。
比如我们给出的prompt是:“A is B. C is D. A is”,你大概会猜下一个词是“B”,对吧?没错。也就是说,最关键的token决定了输出,这就叫Query感知稀疏性。
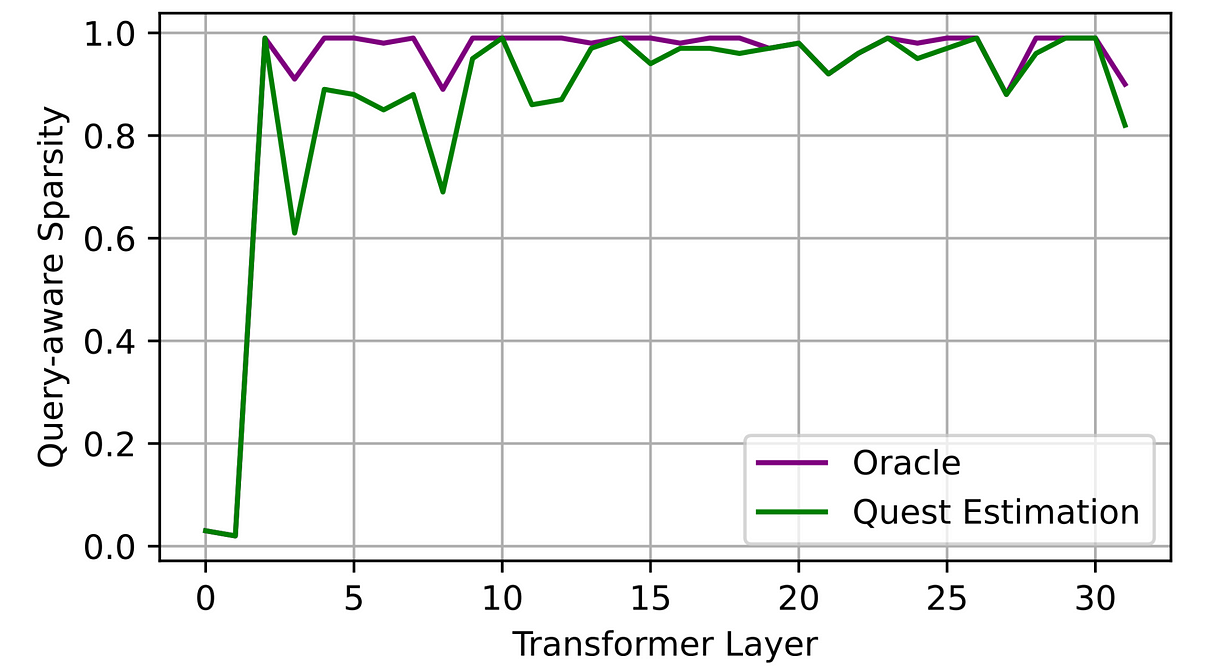
Transformer推理稀疏性估计图。
了解这个特性后,QUEST的策略是:找出attention计算中最关键的数据块。它会定位出最Top K个Block。算法很简单,请看图。
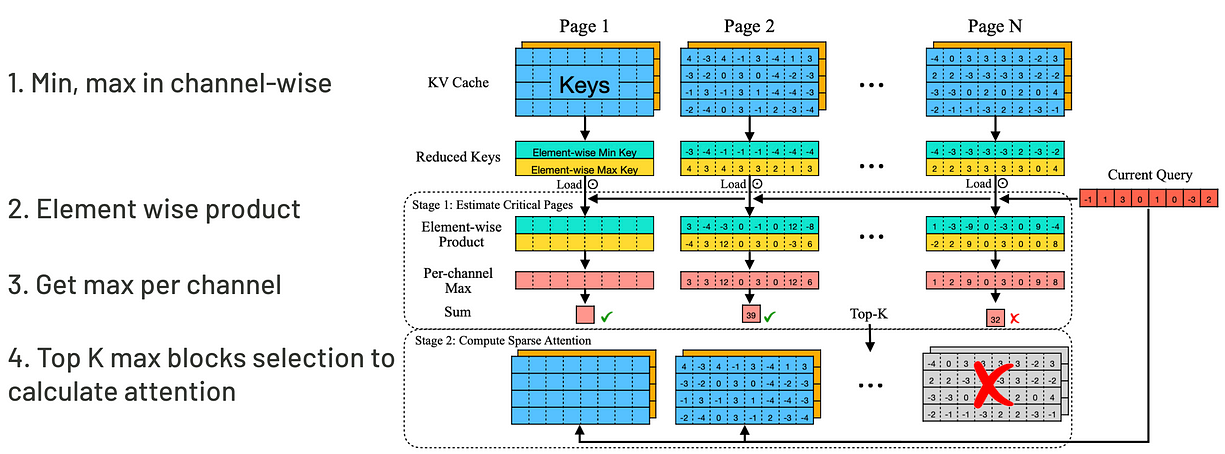
QUEST如何挑选Top K block计算attention
每个数据块,QUEST会先算出该块在通道维度上的最大/最小Key值,然后Query会逐元素与Key做最大最小比对。这个技巧可以大幅减少计算量。甚至根据Query的正负符号,我们可以直接判断用最小值还是最大值参与计算来取得最大结果。搞定了每个块的最大值后,QUEST就挑选Top K个与Query最相关的KV块。通过这套流程,我们的计算量能省很多。
但最后还有一个问题:K怎么选,才能不损伤模型效果?
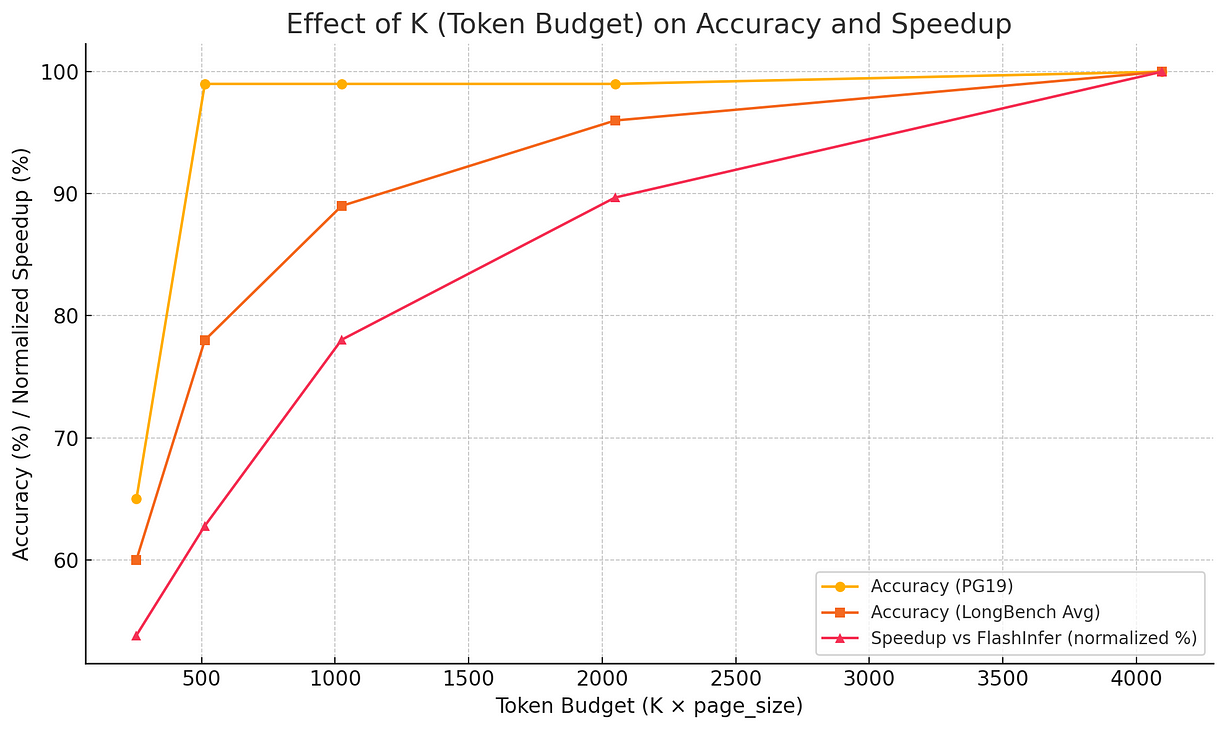
K是个超参数,需要试出来。在论文中,作者建议用K=4096,这样基本能保证模型性能接近100%。
他们的测试结果如下,K = 4096:
- PG19(教科书类数据集)准确率 ≈ 100%
- Passkey检索准确率 ≈ 100%
- LongBench任务准确率 ≈ 与完整缓存结果几乎一致
第三主题:猜测式解码(Speculative decoding)
猜测式解码是加速大模型推理的关键技术之一,Andrej Karpathy曾提到,谷歌最早在2022年提出这个方法。
核心思想很简单:
不要一开始就用那个大而慢但很准的模型(目标模型)来生成词,而是先用一个小而快但不那么准的模型(草稿模型)“猜”出一串后续tokens。然后,再用大模型来验证这些猜测。如果大模型认同小模型的生成结果,就一次性接受这些tokens(节省算力);如果不认同,就从分歧点开始重新生成。下面有个图可以看。
草稿模型可以是Ngrams、1B、甚至3B模型;目标模型可以是几十亿甚至上万亿参数的模型。

图源:网络
用两个模型虽然会多占内存,重复生成也浪费时间。但这方法实在太好用了,连Gemini都实现了它(见下图)。现实中,小模型常常猜得准得很,因为我们常见的词是“yes”“this”“is”这类的,小模型很容易就猜对了。所以相比逐个token解码,现在我们可以把草稿模型一次性猜的一批token,全交由大模型并行验证 —— 极大提升了速度。
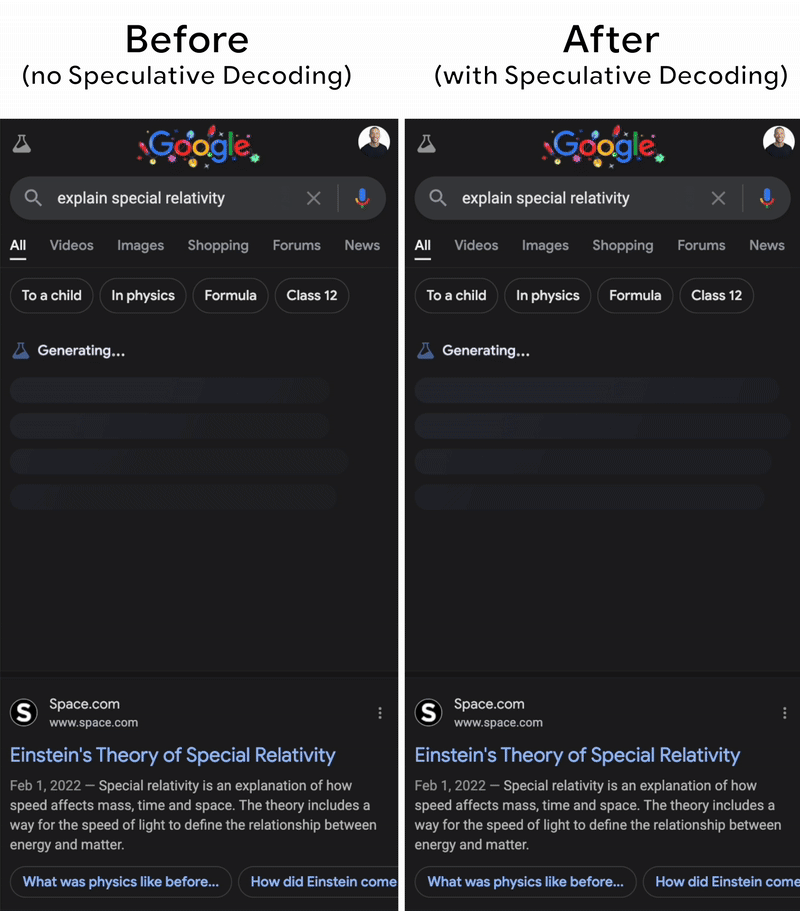
✍️ 这类解码优化我们也实测过,能让中端GPU设备(T4、3090)处理百亿参数模型不卡顿。背后其实是对调度、缓存、异步机制的系统级协同。
💡 有部署需求或者资源受限的落地场景,欢迎私信交流经验。
第四主题:权重调度(Weight Scheduling)
所谓调度,就是把模型的权重在一台物理机器上的资源之间合理分配,比如GPU、CPU、硬盘。这个策略不仅能让推理并行加速,还能让一些大模型(像100B参数的)在资源不高的电脑上运行,比如一台装了T4 GPU的PC。
实现这个目标,关键有两个点:
- 聪明地在GPU、CPU和硬盘之间加载/卸载模型权重。
- 妥善处理计算单元之间的I/O数据传输。
Flexgen
Flexgen 是由斯坦福大学、UC Berkeley 和 CMU 的一组作者提出的,非常有意思的一篇论文,提出了解决两个关键瓶颈的思路。
下面这个图展示了典型的推理流程。每一块需要处理的数据被定义为加载到模型层上的一批(batch)数据。图中的列是 batch 维度,行是层(layer)维度。
我们把满足以下约束条件、能够遍历(也就是完成计算)所有格子的路径叫做“有效路径”:
- 必须从左到右执行
- 所有数据必须在同一个设备上
- 激活依赖右边的“兄弟节点”(也就是相邻的格子)完成后才能继续
- KV缓存要一直保留到最右边的数据处理完成
- 任何时刻,一个设备上存储的tensor总大小不能超过它的内存容量
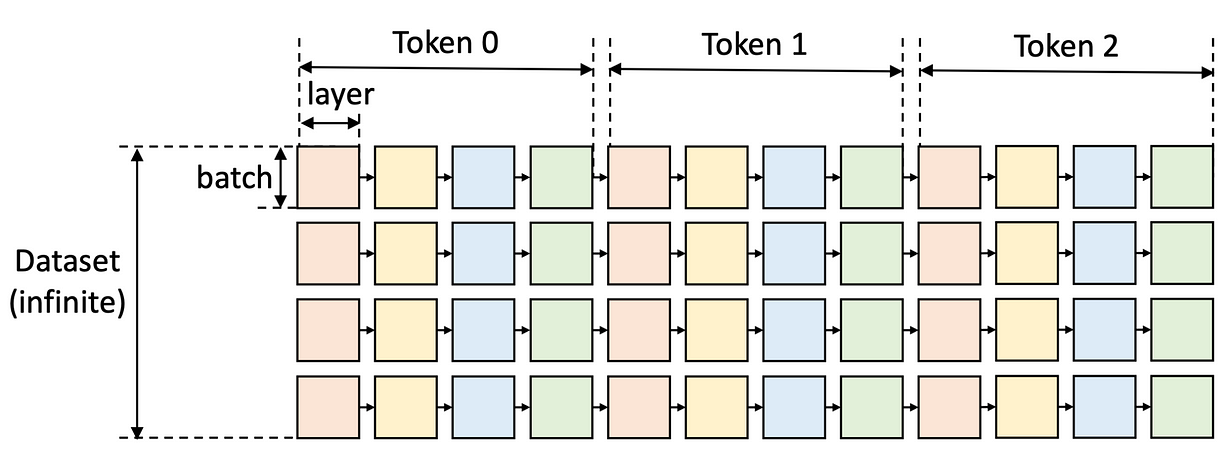
如果我们有 n 个token,那么每个token的数据会按顺序加载和计算。每层的权重会在需要时加载,用完就卸载。不断加载/卸载的过程非常耗时间,因为GPU的计算速度像闪电,内存传输的速度却像蜗牛。
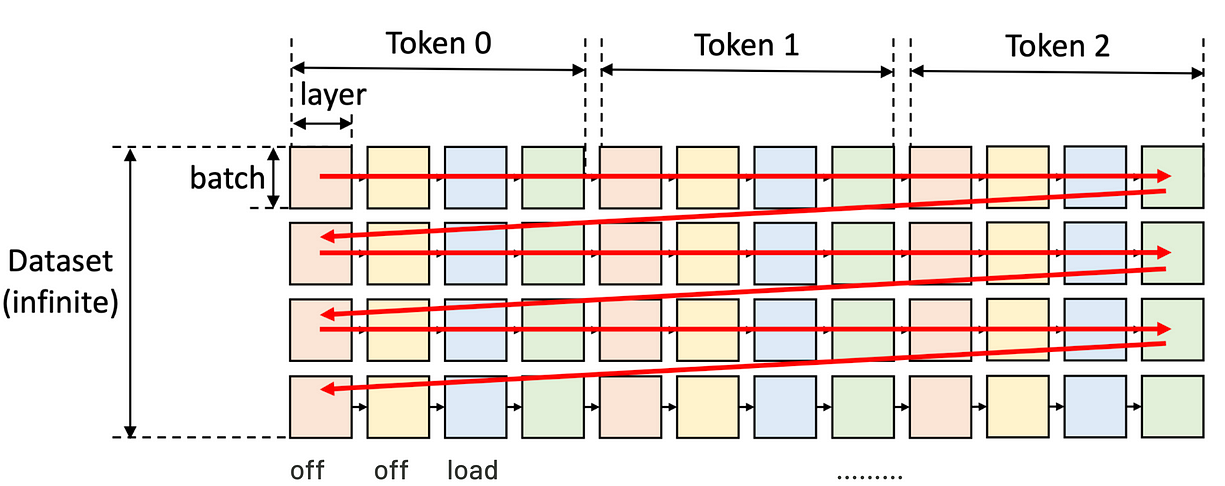
图示:每个格子表示GPU在某层计算一个batch。同颜色表示使用同一层权重。
Flexgen 的优化点在于:不再按行或者列一块块计算,而是改为“Z字形块调度”。它不需要重复I/O就能保存层的权重,同时也保存了下一个列的激活。在执行过程中,Flexgen 会同时进行三个操作:加载下一层的权重、存储前一批的激活/KV缓存、计算当前这批数据。这种并行策略非常好地解决了内存传输瓶颈。
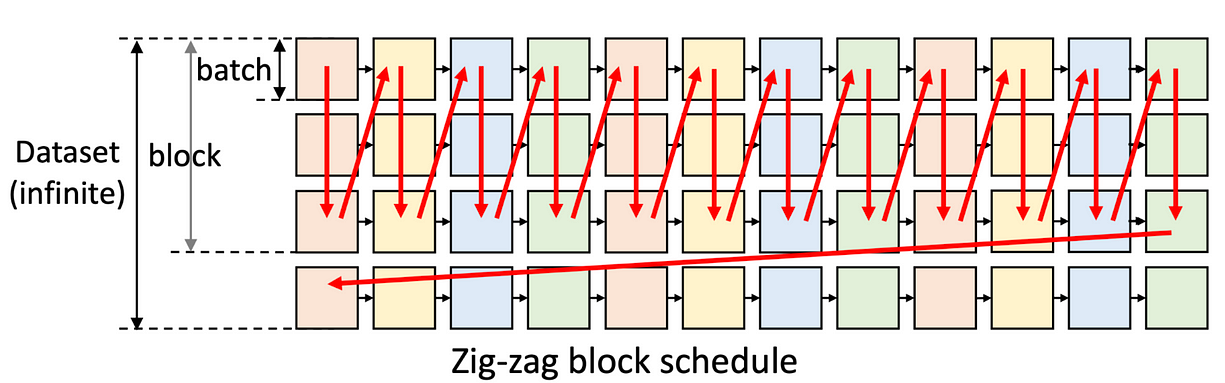
下一个关键点是:Flexgen 怎么把模型的权重合理分配到所有硬件上。
Flexgen 使用线性规划策略搜索(Linear Programming Policy Search)来找到最优加载配置,使整体推理时间最短。
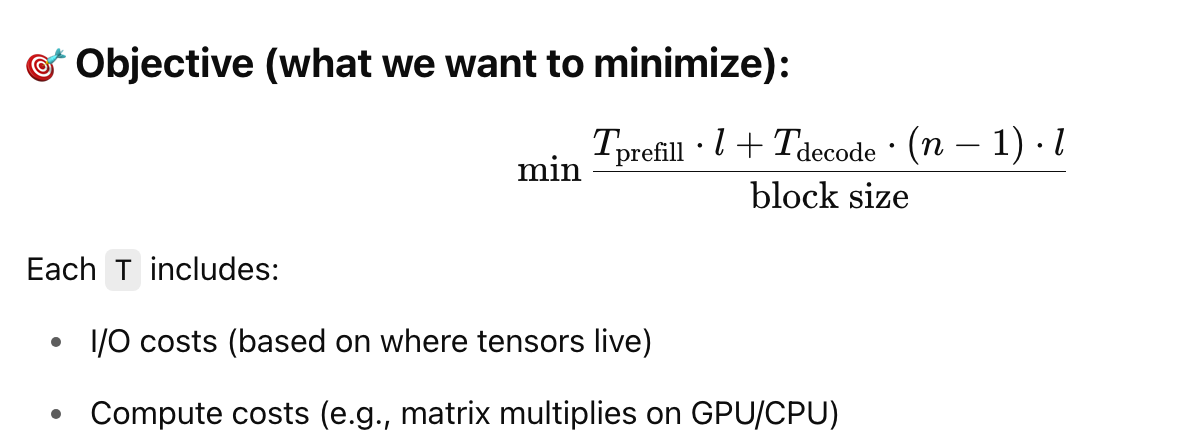
定义如下:
- n:每条序列要生成的token数量
- l:Transformer的层数
- block size:每一块数据的处理量(batch size × 批次数)
下面是 Flexgen 把 OPT-30B 模型部署到 T4 机器的配置示意:
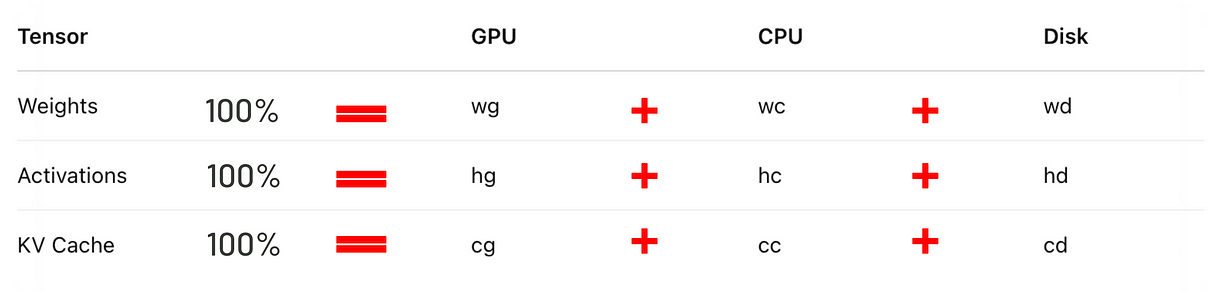

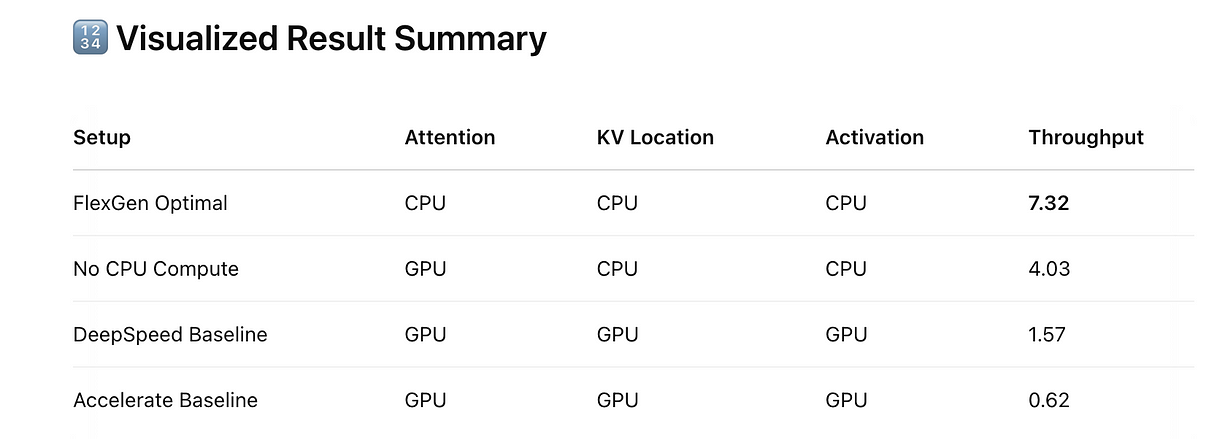
论文中拿 Flexgen 跟 DeepSpeed 和 HuggingFace 的 Accelerate 框架做了对比。Flexgen 的速度达到 7.32 tokens/s,而 DeepSpeed 是 1.57 tokens/s,Accelerate 只有 0.62 tokens/s。
🧠 像FastServe的多队列机制,我们也实测集成进一套私有推理平台,专为边缘设备高并发优化。这个方向特别适合资源有限、但要求稳定输出的小模型应用。
🚀 做这类工程实战时,我们坚持“软硬联动”思路,有类似需求的朋友欢迎来聊聊。
第五主题:系统级优化(System-Level Optimisation)
当前的LLM服务系统(比如 vLLM、Orca)大多采用“先来先服务(FCFS)”机制+“执行到底(run-to-completion)”策略,这会导致前端阻塞(Head-of-Line blocking) —— 简单说:长请求把短请求卡死了。实际业务中,这种等待可能占据总延迟的90%。下面是 FastServe 论文里的观测数据:
备注:这里说的“短请求”和“长请求”指的是生成第一个token的时间,而不是prompt的长度。
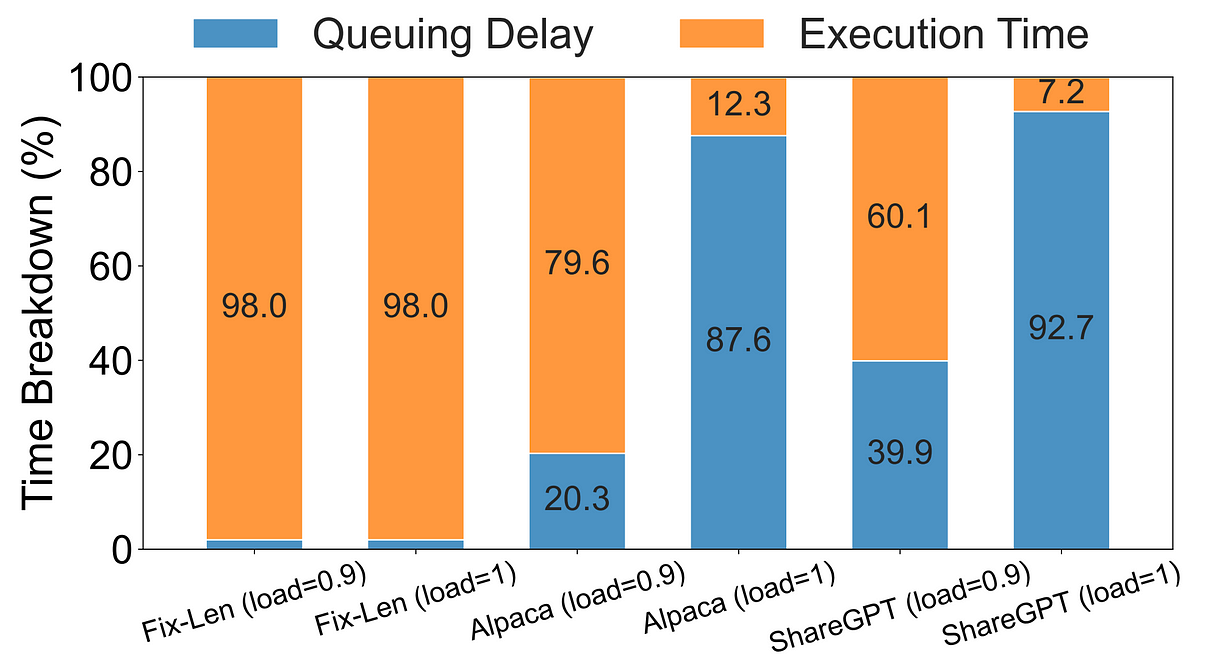
执行时间 vs 排队时间对比图
解决方案是:让长请求可以被中断,已经完成的部分进缓存,没完成的部分留着以后再算。然后,系统切换去处理短请求。短请求完了,再回头处理那个长的。这就需要实现多队列(multi-queue)机制,而且不同请求优先级不一样。
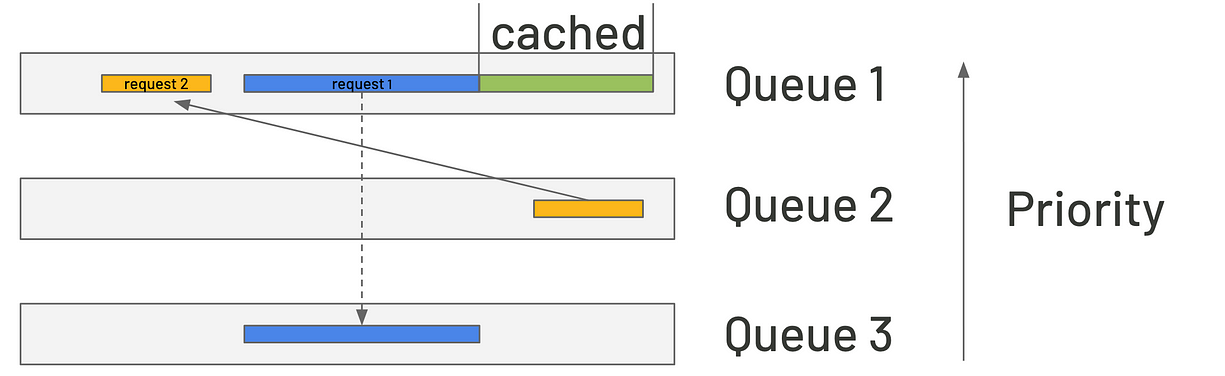
不过,这招也有问题:如果高优先级队列里堆了一堆长请求,在切去处理短请求前,每个长请求都可能被中断多次。这不仅延长了处理时间,也会让缓存压力变大。
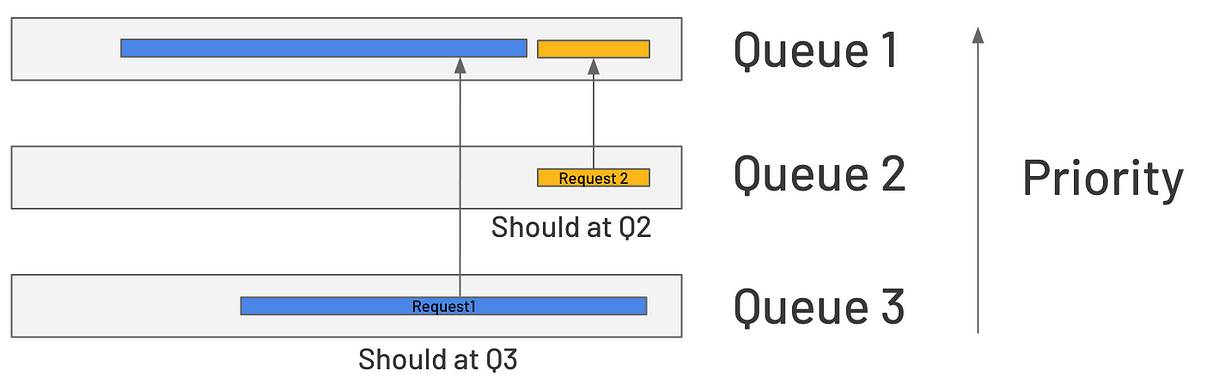
FastServe 的解决办法是引入 Skip-Join MLFQ(多级反馈队列)。系统接到请求时,先估算出生成第一个token所需的时间,再把请求路由到合适的优先级队列,这样就不会干扰短请求。而且,KV缓存机制可以在GPU还没处理上一个请求时就提前准备好下一个请求的数据,进一步减少延迟。
其他主题:
还有很多其他优化LLM推理的思路,但因为它们已经被很多工程师日常用烂了,我在这就不细讲了,只列出主题和参考论文如下:
量化(Quantization)
降低权重和激活的精度(比如从FP16到INT4或FP8),减小模型体积,提高推理速度,同时保持质量损失最小。
- AWQ
用激活驱动的重要性评分做量化,可实现INT3级别的低比特推理,无需再训练。 - LLM.int8()
训练后引入INT8矩阵乘法,并加入校准,支持Transformer推理而不降低准确率。 - SmoothQuant
调整每层的激活和权重范围,提升训练后量化效果。 - ZeroQuant / V2 / FP
基于校准和低秩补偿实现INT4/FP4等低比特量化。 - LLM-FP4
展示FP4格式可以在不牺牲质量的前提下,大幅提升推理速度。 - WINT8
为MoE模型提供的INT8量化,在生产环境中使用。 - SpQR
把量化和稀疏性结合起来,实现几乎无损的LLM压缩,适合边缘部署。 - FP8-LM
用FP8格式训练Transformer,训练和推理都能降低内存与计算成本。 - FP8 Formats
定义了NVIDIA的FP8格式及其在深度学习中的推理/训练应用。
Early Exit 推理
- LITE
中间层学会提前做出预测。如果信心够高,token就可以提前“下车”,最多节省38%的FLOPS。
注意力优化(Attention Optimization)
- FlashAttention 1, 2, 3
使用memory tiling技术的高速精确注意力机制,比标准实现更快更省内存。 - ROFormer
引入旋转位置编码(rotary position embedding),改善长程泛化能力。 - StreamLLM
让注意力机制可以在流式输入中动态适应新内容。
非自回归 LLMs(Non-autoregressive LLMs)
- Diffusion-LM
第一个把扩散模型应用于文本生成的工作,实现可控文本生成。
工具篇:这些技巧怎么用?
vLLM 是一个开源库,能让LLM推理跑得更快、更高效。
它由 UC Berkeley 的研究者开发,专注于高吞吐、低延迟的LLM服务系统。vLLM 起初是围绕 PageAttention 的想法起步的,但现在已经实现了上面几乎所有提到的技术。vLLM 社区也是我见过最活跃的LLM推理优化圈子之一。
这是示例代码,我使用了 vLLM,调用 QwenVL 2.5 7B instruct 来描述一张照片。
| from transformers import AutoProcessor | |
| from vllm import LLM, SamplingParams | |
| from qwen_vl_utils import process_vision_info | |
| import torch | |
| MODEL_PATH = "Qwen/Qwen2.5-VL-7B-Instruct" | |
| llm = LLM( | |
| model=MODEL_PATH, | |
| limit_mm_per_prompt={"image": 10, "video": 10}, | |
| device_map = 'cuda', | |
| ) | |
| sampling_params = SamplingParams( | |
| temperature=0.1, | |
| top_p=0.001, | |
| repetition_penalty=1.05, | |
| max_tokens=16, | |
| stop_token_ids=[], | |
| ) | |
| min_pixels = 128*28*28 | |
| max_pixels = 1280*28*28 | |
| image_messages = [ | |
| {"role": "system", "content": "You are a helpful assistant."}, | |
| { | |
| "role": "user", | |
| "content": [ | |
| { | |
| "type": "image", | |
| "image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg", | |
| "min_pixels": min_pixels, | |
| "max_pixels": max_pixels, | |
| }, | |
| {"type": "text", "text": "Describe this image."}, | |
| ], | |
| }, | |
| ] | |
| messages = image_messages | |
| processor = AutoProcessor.from_pretrained(MODEL_PATH) | |
| prompt = processor.apply_chat_template( | |
| messages, | |
| tokenize=False, | |
| add_generation_prompt=True, | |
| ) | |
| image_inputs, _, _ = process_vision_info(messages, return_video_kwargs=True) | |
| mm_data = {} | |
| if image_inputs is not None: | |
| mm_data["image"] = image_inputs | |
| llm_inputs = { | |
| "prompt": prompt, | |
| "multi_modal_data": mm_data, | |
| } | |
| outputs = llm.generate([llm_inputs], sampling_params=sampling_params) | |
| generated_text = outputs[0].outputs[0].text |
好啦,非常感谢你读完我的文章!这其实是我在 Fatima Fellowship 期间的一部分研究工作,我目前正跟科罗拉多矿业学院的博士候选人 Dr. Ismet Dagl 合作,一起在做 LLM、LVM 以及各类基础模型在边缘设备上的性能与内存优化。
写在最后:
🤖 这也是我们重点实践方向之一,在LLM/LVM模型的边缘部署中,vLLM + KV优化 +混合调度方案成了实用组合拳。
🔧 技术实战派|AI软硬件一体解决者
📩 想看部署细节、代码或实测数据,欢迎评论留言,我看到会一一回复。

















 19万+
19万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









