







前言 在本文中,作者提出了一种端到端的动作预测注意模型,称为Future Transformer(FUTR),该模型利用所有输入帧和输出标记上的全局注意来预测未来动作的分钟长序列。与以往的自回归模型不同,该方法在并行解码中学习预测未来动作的整个序列,从而为长期预测提供更准确和快速的推理。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。

论文:Future Transformer for Long-term Action Anticipation
论文:http://arxiv.org/pdf/2205.14022
代码:未发布
背景
视频中的长期动作预测最近成为高级智能系统的一项基本任务。它旨在通过对视频中过去行为的有限观察来预测未来的一系列行为。虽然有越来越多的关于动作预测的研究,但最近的大部分工作都集中在预测几秒钟内的一个动作。相比之下,长期行动预期旨在预测未来几分钟内的多重行动序列。这项任务具有挑战性,因为它需要了解过去和未来行动之间的长期依赖关系。
最近的长期预测方法将观察到的视频帧编码为压缩向量,并通过递归神经网络(RNN)对其进行解码,以自回归方式预测未来动作序列。尽管在标准基准上的表现令人印象深刻,但它们存在以下局限性:
1.编码器过度压缩输入帧特征,从而无法保留观察帧之间的细粒度时间关系。
2.RNN解码器在建模输入序列的长期依赖性以及考虑过去和未来动作之间的全局关系方面受到限制。
3.自回归解码的序列预测可能会累积来自先前结果的错误,并且还会增加推理时间。
为了解决这些局限性,作者引入了一种端到端的注意力神经网络(FUTR),用于长期的动作预测。该方法有效地捕捉了整个动作序列的长期关系。不仅观察到了过去的行动,而且还发现了未来的潜在行动。如图1所示的编码器-解码器结构(FUTR);编码器学习捕捉过去观测帧之间的细粒度长距离时间关系,而解码器学习捕捉未来即将发生的动作之间的全局关系以及编码器的观测特征。
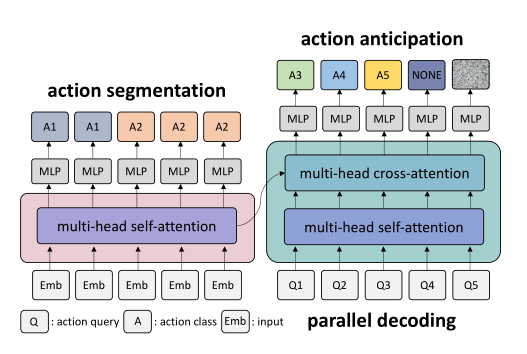
图1 FUTR
贡献
1.介绍了一种端到端的注意力神经网络,称为FUTR,它有效地利用细粒度特征和全局交互来进行长期的动作预测。
2.提出在并行解码中预测一系列动作,从而实现准确快速的推断。
3.开发了一个集成模型,该模型通过在编码器中分割动作和在解码器中预测动作来学习不同的特征表示。
4.提出的方法为长期行动预期、早餐和50份沙拉的标准基准设定了新的技术水平。
相关工作
1、行动预期
动作预测旨在通过对视频的有限观察来预测未来的动作。随着大规模数据集的出现,人们提出了许多方法来解决下一个行动预测,在几秒钟内预测未来的单个行动。最近有人提出长期行动预测,从远程视频中预测遥远未来的一系列行动。
Farha等人首先介绍了长期行动预期任务,并提出了两种模型,RNN和CNN来处理该任务。Farha和Gall引入了GRU网络,以自回归的方式对未来活动的不确定性进行建模。他们在测试时预测未来行动的多个可能序列。Ke等人介绍了一种模型,该模型可以预测特定未来时间戳中的动作,而无需预测中间动作。他们表明,中间作用的迭代预测会导致误差累积。以前的方法通常将观察到的帧的动作标签作为输入,使用动作分割模型提取动作标签。相比之下,最近的研究使用视觉特征作为输入。Farha等人提出了一个长期动作预测的端到端模型,将动作分割模型用于训练中的视觉特征。他们还引入了一个GRU模型,该模型在过去和未来的行动之间具有周期一致性。Sener等人提出了一种多尺度时间聚合模型,该模型将过去的视觉特征聚合到压缩向量中,然后使用LSTM网络迭代预测未来的行为。最近的工作通常利用RNN对过去的帧进行压缩表示。相比之下,作者提出了一个端到端注意模型,该模型使用过去帧的细粒度视觉特征来预测所有未来的并行动作。
2. 自我注意机制
自我注意(Self attention)最初被引入神经机器翻译,以缓解RNN中学习长期依赖关系的问题,并已被广泛应用于各种计算机视觉任务中。自我注意可以有效地学习图像域中图像像素或斑块之间的全局交互作用。有几种方法利用视频领域中的注意机制来模拟短期视频和长期视频中的时间动态。与动作预测相关,Girdhar和Grauman最近推出了预测视频转换器(VT),它使用自我关注解码器预测下一个动作。与VT不同,VT需要对长期预测进行自回归预测,作者的编码器-解码器模型有效地预测了未来几分钟的并行动作序列。
3. 并行解码
transformer设计用于按顺序预测输出,即自回归解码。由于推理成本随着输出序列的长度而增加,自然语言处理中的最新方法将自回归解码替换为并行解码。具有并行解码的transformer模型也被用于计算机视觉任务,如目标检测、相机校准和密集视频字幕。我们将其用于长期行动预测,同时预测未来的一系列行动。在长期的动作预测中,并行解码不仅可以实现更快的推理,还可以捕获未来动作之间的双向关系。
问题说明
长期行动预测的问题是从视频的给定可观察部分预测未来视频帧的动作序列。图2说明了问题设置。对于具有T帧的视频,观察到第一个αT帧,并预期下一个βT帧的动作序列;α 是视频的观察率,而β是预测比率。
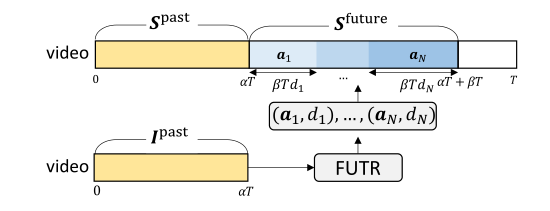
图2 长期行动预测的问题
方法
Future Transformer (FUTR)
在本文中,作者提出了一个完全基于注意力的网络,称为FUTR,用于长期的行动预期。总体架构包括变压器编码器和解码器,如图3所示。
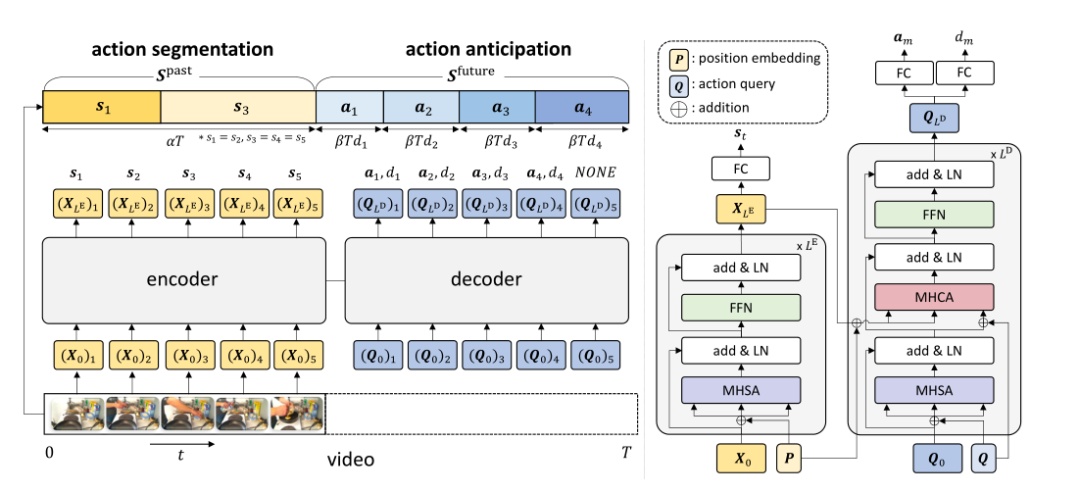
图3 FUTR的总体架构
1. 编码器
编码器将视觉特征作为输入,分割过去帧的动作,通过自我注意学习不同的特征表示。
作者使用从输入帧中提取的视觉特征,对时间跨度为τ的帧进行采样,采样的帧特征被馈送到线性层,然后将激活函数ReLU到E,创建输入标记:
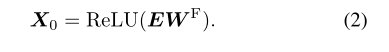
每个编码器层由一个多头自关注(MHSA)、层规范化(LN)和带有剩余连接的前馈网络(FFN)组成。定义了一种多头注意(MHA),该注意基于缩放的点积注意:
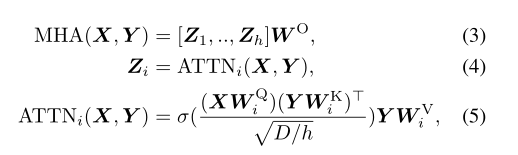
最后一个编码器层的最终输出用于生成动作分段, 通过应用全连接(FC)层,后接softmax:
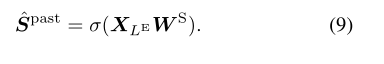
2. 解码器
解码器将可学习的标记作为输入,称为动作查询,并平行预测未来动作标签和相应的持续时间,通过自我注意和交叉注意学习过去和未来动作之间的长期关系。
查询操作嵌入M个可学习标记。查询的时间顺序固定为与未来操作的时间顺序相等,即第i个查询对应于第i个未来操作。
每个解码器层由一个MHSA、一个多头交叉注意(MHCA)、LN和FFN组成。输出查询Ql+1从解码器层获得:
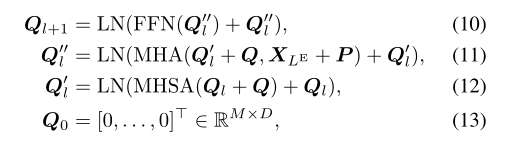
最后的解码器层的最终输出用于生成未来动作,通过应用FC层,后跟softmax和持续时间向量:
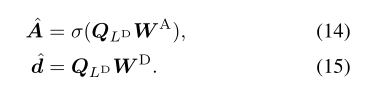
3. 目标动作分段损失
作者应用动作分段损失来学习编码器中过去动作的特征表示,作为辅助损失。动作分段损失Lseg定义:
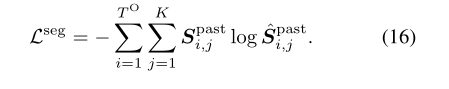
行动预期损失定义:
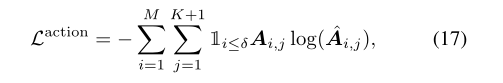
持续时间回归损失定义:
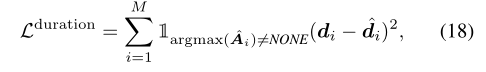
最终损失:
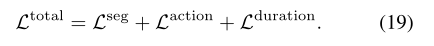
实验
表1 与最新技术的比较
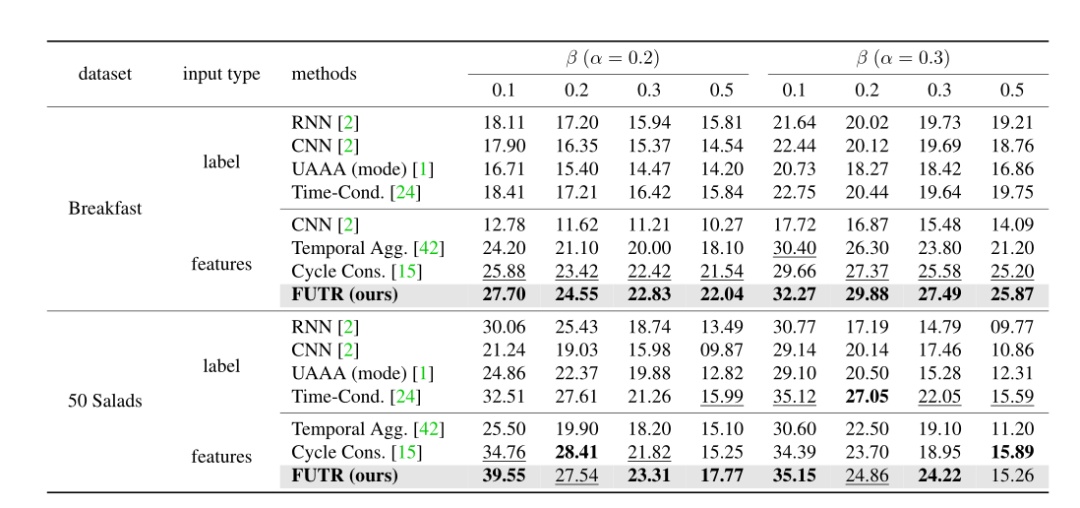
表2 并行解码与自回归解码
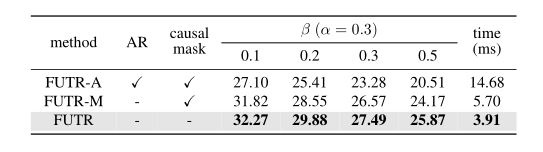
表3 全局自我关注与局部自我关注

表5 损失消融
图4 早餐上的交叉注意力地图可视化

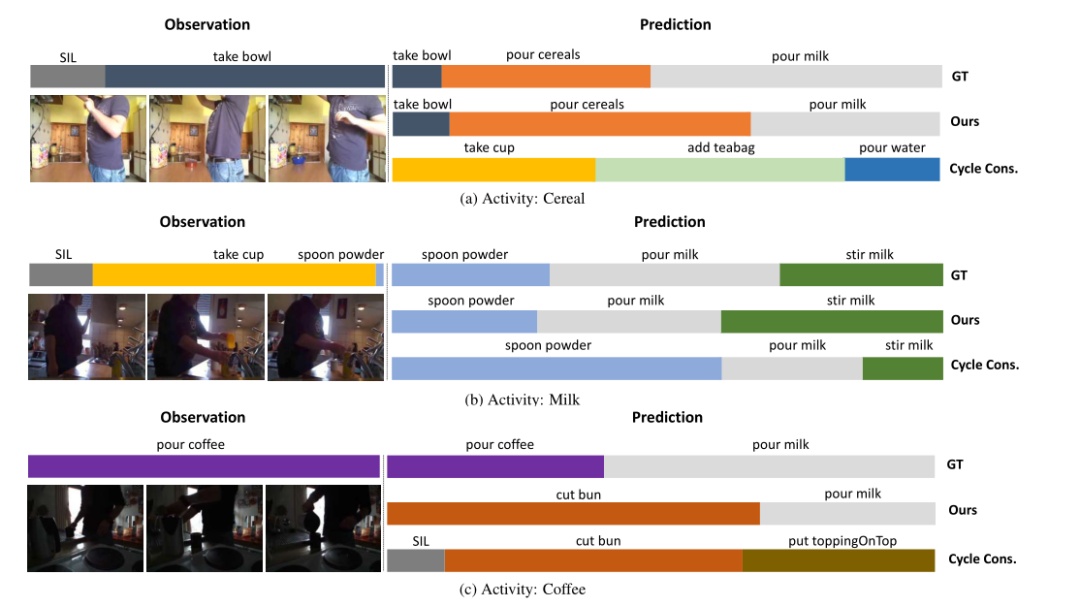
图5 早餐的定性结果
结论
作者引入了端到端注意神经网络FUTR,它利用过去和未来行动的全局关系进行长期行动预测。该方法利用细粒度视觉特征作为输入,并预测并行解码中的未来动作,从而实现准确快速的推理。通过在两个基准上的大量实验,证明了作者的方法的优势,达到了最新的水平。
CV技术指南创建了一个计算机视觉技术交流群和免费版的知识星球,目前星球内人数已经700+,主题数量达到200+。
知识星球内将会每天发布一些作业,用于引导大家去学一些东西,大家可根据作业来持续打卡学习。
CV技术群内每天都会发最近几天出来的顶会论文,大家可以选择感兴趣的论文去阅读,持续follow最新技术,若是看完后写个解读给我们投稿,还可以收到稿费。 另外,技术群内和本人朋友圈内也将发布各个期刊、会议的征稿通知,若有需要的请扫描加好友,并及时关注。
加群加星球方式:关注公众号CV技术指南,获取编辑微信,邀请加入。
公众号其它文章
CVPR2022 | iFS-RCNN:一种增量小样本实例分割器
CVPR2022 | A ConvNet for the 2020s & 如何设计神经网络总结
CVPR2022 | PanopticDepth:深度感知全景分割的统一框架
CVPR2022 | 未知目标检测模块STUD:学习视频中的未知目标
从零搭建Pytorch模型教程(五)编写训练过程--一些基本的配置
从零搭建Pytorch模型教程(四)编写训练过程--参数解析















 776
776











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









