







前言 本文中提出了一种用于行人重识别的注意感知特征学习方法。该方法由一个部分注意分支(PAB)和一个整体注意分支(HAB)组成,并与基础再识别特征提取器进行了联合优化。由于这两个分支建立在主干网络上,因此没有为ReID特征提取引入额外的结构。因此,本方法能够保持与原始网络相同的推理时间。
本教程禁止转载。同时,本教程来自知识星球【CV技术指南】更多技术教程,可加入星球学习。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
Information
- Title:Deep attention aware feature learning for person re-identification
- From:pattern recognition2022
- Paper Link:https://arxiv.org/pdf/2003.00517.pdf
- Tsinghua university
- code:https://github.com/CYFFF/DAAF_re-id
motivation
注意力可以隐式地嵌入到用于提取人的外观表征的特征图中。由于行人重识别的图像已经是裁剪后的行人,全局信息主要是整个身体,局部信息可以是具有微观特征的关键点部位,因此使用全局注意力和局部注意力分别解耦身体和关键点。
Abstract
提出在不改变原始结构的情况下,将注意学习作为ReID网络的附加目标,从而保持相同的推理时间和模型大小。考虑两种注意力,使学习的特征图分别了解人和相关的身体部位。在全局范围内,一个整体注意分支(HAB)将骨干人员获得的特征图集中在人身上,以减轻背景的影响。在局部,部分注意分支(PAB)将提取的特征解耦为几组,分别负责不同的身体部位(即关键点),从而提高了姿态变化和部分遮挡的鲁棒性。
Introduction
注意力学习因其具有去除背景杂波或提高不同身体部位的局部判别性的潜力而具有吸引力。目前,大多数使用注意力的策略必须合并一个单独的流作为注意力函数来重新加权特征图,从而增加计算复杂度和模型大小。我们考虑一种更实用的方法来整合而不改变基本ReID网络的注意力。我们的关键假设是,这种注意力可以隐式地嵌入到用于提取人的外观表征的特征图中。如果特征图包含这些信息,那么它们随后可以用来预测一些与注意力相关的信息。
具体提出了一种ReID任务的注意感知特征学习方法。由于CNN强大的非线性,其具有适当的约束本身可以获得关注。因此,如果我们能在训练阶段添加适当的约束,就可以像以前的工作那样,不添加额外的结构而获得注意力感知特征。为此,我们提出了一个全局注意力分支(HAB)在学习到的特征图中引入全局注意信息,以及一个局部注意分支(PAB)来生成局部注意感知特征图。如图1,通过预测一个人的掩模,HAB被设计来限制主干网络关注的是人的身体,而不是背景。PAB通过明确地使用不同的特征组来预测不同的关键点,进一步迫使不同的特征通道聚焦于不同的身体部位。PAB将通道注意力解释为使特定通道关注不同空间部分的一种方式,并隐式地实现特征通道的解耦。

Method
网络架构
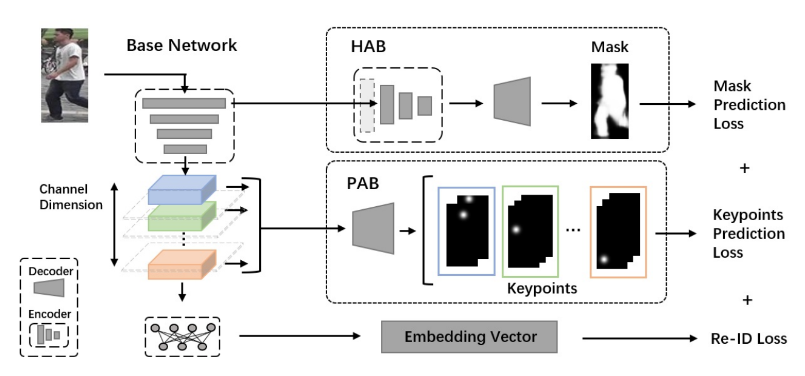
我们的注意力感知特征学习方法可以应用于现有的为行人ReID设计的CNN(本文中称为基础网络),在训练过程中简单地从主干网络中添加两个分支,而使用训练过的网络进行推理时,删除了两个添加的分支,只使用基本网络。因此,所提出的注意感知特征学习方法可以作为一个通用的框架来调整ReID网络,分别再训练两个额外的损失,同时保持测试网络结构不变的原始ReID网络。一方面,设计了一个名为整体注意分支(HAB)的分支,引导学习特征了解杂乱背景下的整体人体,使骨干网络更多地关注人而不是背景。这是通过这个分支将关于人体掩模的监督信息反向传播到主干网络来实现的。另一方面,提出了局部注意分支(PAB),使从主干学习到的特征可以解耦成不同的组,每个组都能够根据其位置预定义地预测几个人体关键点。通过这种方式,学习的特征隐式部分对齐,提高了对遮挡和姿态变化的鲁棒性。因此,我们学习特征嵌入的目标是
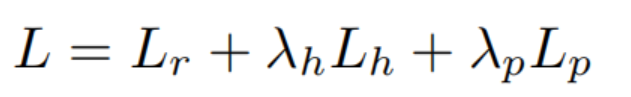
其中Lr代表ReID损失(基础网络的损失),Lh是HAB上计算的损失,Lp是PAB上计算的损失。λh和λp是两个权衡参数。
HAB
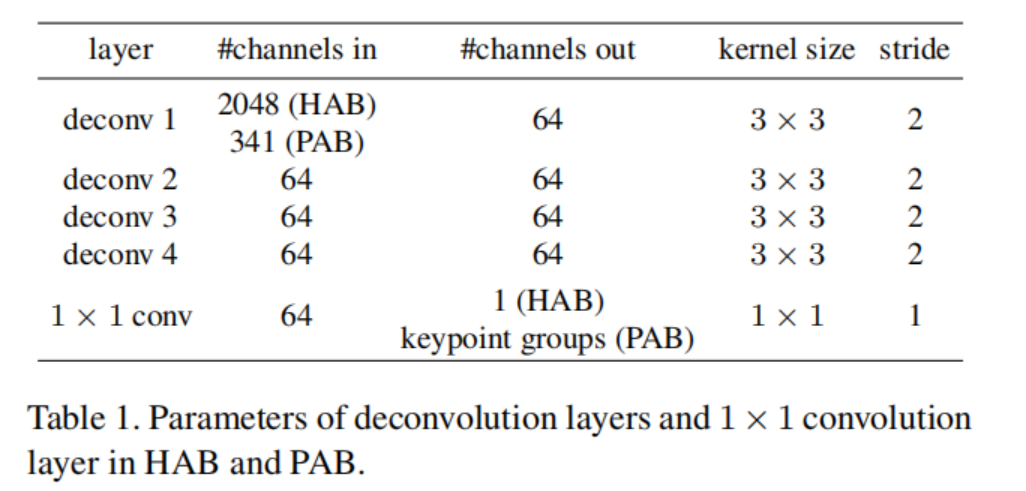
为了使学习到的特征能够更多地关注身体部位而不是背景,我们使用这些特征来预测人体掩模。这样做的基本假设是,生成人体掩模的能力与杂乱背景下对身体部位的感知特征的高度相关。因此,如果掩模可以很好地预测,该任务使用的特征则被认为是在背景杂波中的身体部分。受此假设的启发,我们引入了整体注意分支,使用第一个卷积块生成的特征映射(即低级特征)作为输入,通过一些编码和解码层转发,输出预测的人体掩模。HAB的结构如图2的右上方所示,其中编码器与主干网络的其余部分结构相同,解码器由4个反卷积层[和1个1×1卷积层组成。这个分支的编码部分的设计背后的根本原因有两个方面。首先,cnn提取的特征逐渐代表了低级到高水平的特征。低级特征被认为是各种任务的常见特征,而高级特征大多是特定于任务的特征。因此,我们需要从低级特征中构建掩模预测分支,因为人的掩模预测是一个与人的ReID不同的任务。其次,保持编码器与主干网络具有相同的结构可以期望有一个良好的人掩模预测性能,并进一步对共享的低级特征施加约束,使其对不同的任务足够通用。
PAB
虽然整体注意特征学习可以从背景杂乱中更关注人体,但局部注意可以进一步帮助行人ReID。我们将局部分成不同的组,每个组都被训练成负责预测一组特定的关键点。由于我们对每一组特征映射使用相同的解码器进行关键点预测,因此在每一组都可以完美预测相关关键点的理想情况下,认为这些组可以解耦相关关键点。虽然这在实际情况下无法实现,但学习过程是为了生成具有该特性的特征,因此我们的局部注意特征学习也可以看作是一种解耦的特征学习。这种解耦特征学习的优点是它提高了对遮挡和姿态方差的鲁棒性。在发生遮挡时,消失的身体部位只能影响相应的特征通道,而其他特征通道仍然可以很好地工作,因此部分遮挡对所有特征通道的影响可以限制在一个小的内容上。
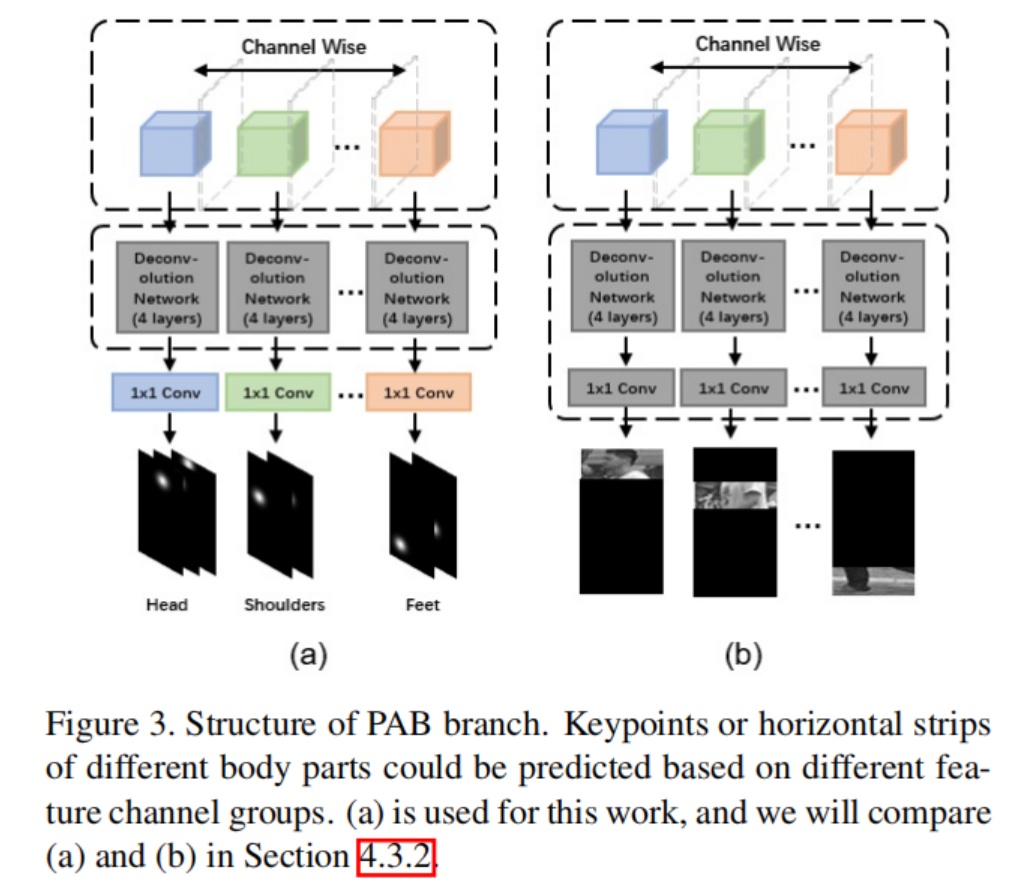
在这一基本思想下,部分注意特征学习模块以主干网络输出的特征图作为输入,手动将其分成若干组,预测不同的关键点组。学习过程和网络结构如图2和图3(a).假设a为输入图像,F为主干网络的映射函数,x = F (a)为a的输出特征映射。如果我们将x分成M个组,那么x = {x1,x2,···,xM} = {F1(a),F2(a),···,FM (a)},其中xp = Fp (a)表示第p个组的特征图。将xp作为输入,按照四个反卷积层将输入解码为输入特征图,然后与1×1卷积进行卷积,生成关键点预测结果(即热图)。与其他关键点检测方法一样,K个关键点K个热图分别预测,每个热图对应一个特定的关键点。因此,除了共享权值反卷积层外,不同组的1×1卷积层也需要是独立的,因为它们的作用是将提取的特征映射到不同数量的热图上。直观地说,不同的特征图组可以用来预测不同的身体部位,而不是关键点。
实验细节
基线:TriNet
backbone:ResNet50
λh=λp=0.003
initial Lr:0.001
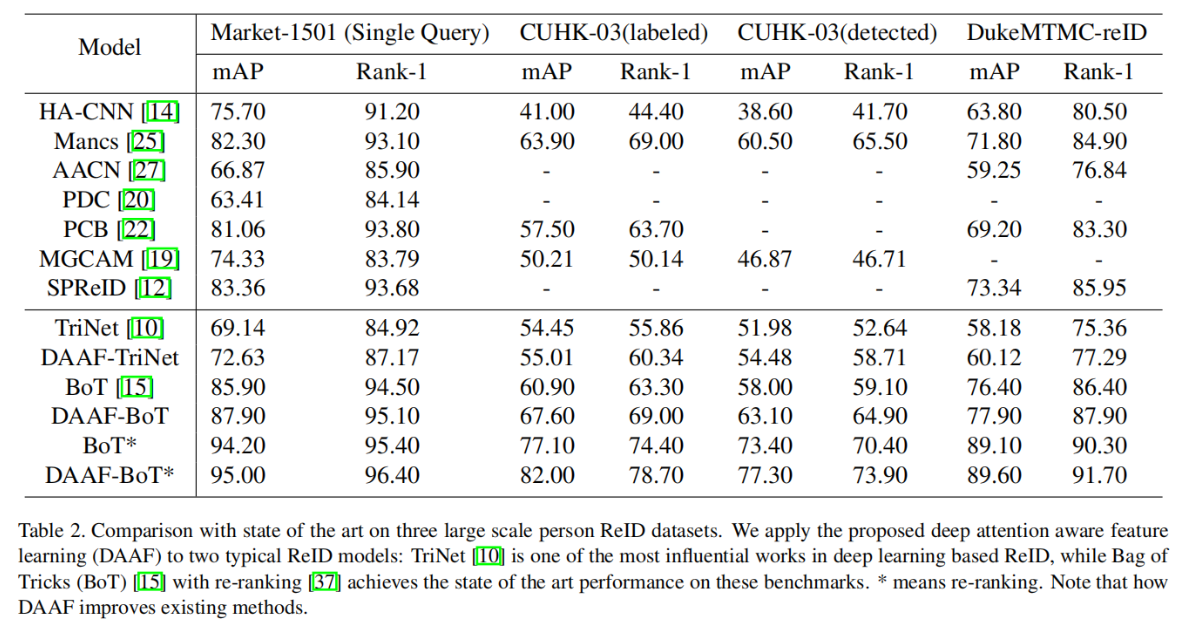
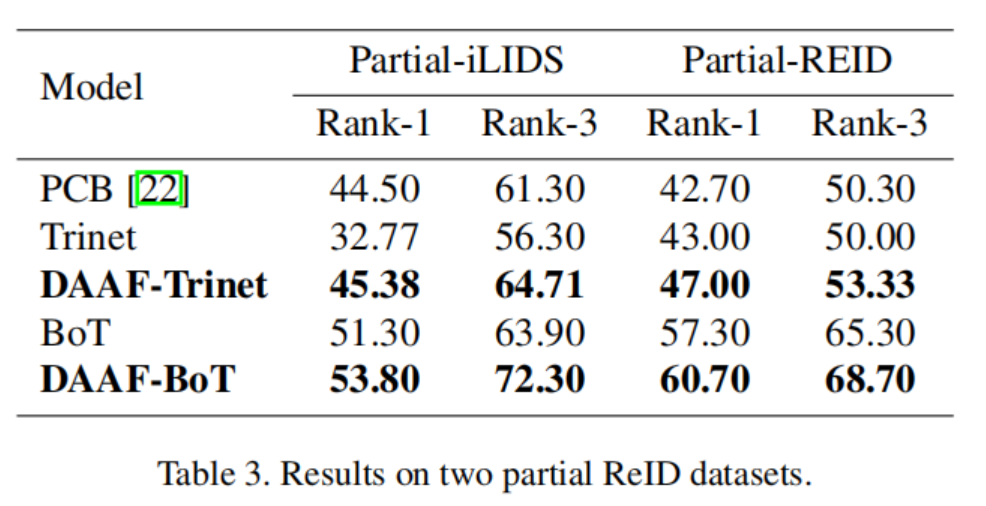
实验结果
不同数据集的比较
可视化

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1B4pSdiO-1685698109406)(image/HAB9.jpg)]
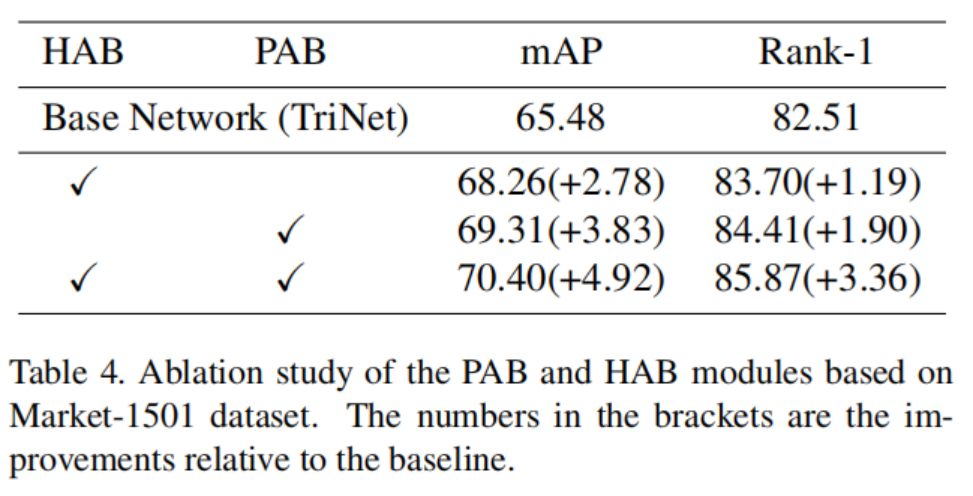
消融实验
结论
本文中提出了一种用于行人重识别的注意感知特征学习方法。该方法由一个部分注意分支(PAB)和一个整体注意分支(HAB)组成,并与基础再识别特征提取器进行了联合优化。由于这两个分支建立在主干网络上,因此没有为ReID特征提取引入额外的结构。因此,我们的方法能够保持与原始网络相同的推理时间。
值得注意的是,本工作应用到了一个潜在的观点,即CNN本身具有强大的特征提取功能,神经网络的损失已经使模型往正确的方向学习,这也是使用“掩模”的相关工作的基础。早期的重识别工作通过图像分割,可以将行人的图像相等地分成横条纹,使每条条纹粗粗地代表人体的一部分,但是由于分割的条纹不可避免地包含背景,因此会受到背景的影响。而本文使用全局注意力与局部注意力,分别处理全局(身体)和局部(关键点),这对行人重识别是很关键的。事实上,在当前的重识别领域,注意力已经成为了一个重要元素,大量工作已经或多或少借鉴了注意力的思想去优化重识别方法。
但进行全局、局部的注意力学习是不够的,由于原始数据不对齐带来的挑战还没有被探索。由于拍摄角度、行人姿态不一致,实际上行人重识别的图像数据绝大多数是非对齐的,在接下来的工作中,我们将解读一种处理这种错位的图像表示的方法。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
模型部署交流群:732145323。用于计算机视觉方面的模型部署、高性能计算、优化加速、技术学习等方面的交流。
其它文章
ICLR 2023 | RevCol:可逆的多 column 网络,大模型架构设计新范式
CVPR 2023 | 即插即用的注意力模块 HAT: 激活更多有用的像素助力low-level任务显著涨点!
ICML 2023 | 轻量级视觉Transformer (ViT) 的预训练实践手册
即插即用系列 | 高效多尺度注意力模块EMA成为YOLOv5改进的小帮手
即插即用系列 | Meta 新作 MMViT: 基于交叉注意力机制的多尺度和多视角编码神经网络架构
全新YOLO模型YOLOCS来啦 | 面面俱到地改进YOLOv5的Backbone/Neck/Head
libtorch教程(一)开发环境搭建:VS+libtorch和Qt+libtorch















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









