









-
摘要:
-
奖励模型(RMs)是成功的 RLHF 的关键,它可以将预先训练好的模型与人类的偏好相匹配。目前对这些奖励模型进行评估的研究却相对较少。评估奖励模型可借以了解用于对齐语言模型的不透明技术以及其中蕴含的价值。迄今为止,关于奖励模型的能力、训练方法或开源描述很少。在本文中,我们介绍了用于评估的基准数据集和代码库 RewardBench,以增强对奖励模型的科学理解。RewardBench 数据集收集了聊天、推理和安全方面的提示-获胜-失败三项数据,用于衡量奖励模型在具有挑战性、结构化和分布外查询中的表现。我们为具有微妙但可验证的原因(如错误、不正确的事实)的 RM 创建了特定的比较数据集,以说明为什么一个答案比另一个答案更受青睐。在 RewardBench 排行榜上,我们评估了使用多种方法训练的奖励模型,例如分类器的直接 MLE 训练和直接偏好优化 (DPO) 的隐式奖励建模,以及各种数据集。为了更好地理解 RLHF 过程,我们介绍了各种奖励模型在拒绝倾向、推理局限性和指导缺陷方面的许多发现。
-
1 介绍
从人类反馈中强化学习(RLHF)是流行语言模型(LM)成功的必要但不透明的工具,例如 OpenAI 的 ChatGPT(Schulman et al.,2022)和 Anthpic 的 Claude(White et al.,2022a)。RLHF 的流行源于它在规避将人类偏好整合到语言模型中的最大困难之一方面的功效:指定明确的奖励(Christian ano et al.,2017)。奖励模型(RM)是这一过程的核心。它们是通过复制原始语言模型并在标记的偏好数据上对其进行训练来创建的,生成一个模型,该模型可以预测一段文本是否可能比另一段文本更受欢迎。然后,强化学习优化器使用此奖励模型信号来更新
原始模型的参数,提高各种任务的性能(欧阳等人,2022 年;Touvron 等人,2023 年)。
虽然后 RLHF 模型(称为策略)甚至预训练模型都被广泛记录和评估,但 RLHF 过程的基本属性(如 RM)受到的关注要少得多。最近关于训练奖励模型的工作(朱等人,2023a;江等人,2023c)已经开始填补这一空白,但利用了以前 RLHF 训练过程中的验证集,如人类的有用和无害数据(白等人,2022a)或 OpenAI 的学习总结(Stiennon 等人,2020),众所周知,由于注释者之间的分歧,这些过程的准确率上限在 60% 到 70% 之间(王等人,2024)。此外,新发布的偏好数据旨在扩展偏好训练数据集的多样性,如 UltraFeedback(崔等人,2023)、UltraInteract(袁等人,2024a)和花蜜(朱等人,2023a),没有测试集,因此需要一种新的 RM 评估风格。
我们开始通过引入 REWARDBENCH 来纠正评估方法的缺乏,REWARDBENCH 是第一个用于基准奖励模型的工具包。RLHF 是一个广泛适用的过程,用于增强 LMs 的特定能力,例如安全(戴等人,2023 年)或推理(莱特曼等人,2023 年;哈弗里拉等人,2024a 年)以及综合能力,例如指令跟随(欧阳等人,2022 年)或 “可操纵性”(Askell 等人,2021 年;白等人,2022a 年)。RMs 的彻底评估也将涵盖这些类别。在这项工作中,我们整理数据以创建跨各种奖励模型属性的结构化比较。每个样本都被格式化为提示,其中包含人工验证的选择和拒绝完成。我们设计子集,以便在难度和覆盖范围上有所不同。一些子集由小 RM 求解,达到 100% 的准确率,但其他子集更难区分,并且仍然具有 75% 左右的最先进性能,许多模型围绕随机基线。
我们的目标是通过 REWARDBENCH 的排行榜来绘制公开可用奖励模型的当前格局。我们已经评估了 80 多个模型,例如经过分类器训练的模型,包括 UltraRM(崔等人,2023 年)、Starling(朱等人,2023a 年)、PairRM(江等人,2023c 年)、SteamSHP(伊萨亚拉赫等人,2022 年)、奖励 rAnked FineTuning(RAFT)(董等人,2023 年)的模型,以及其他模型。我们还评估了使用直接策略优化(DPO)(Rafailov 等人,2023 年)训练的流行聊天模型,例如 Zephir-β(汤斯顿等人,2023 年)、Qwen-Chat(白等人,2023 年)、StableLM(Bellagente 等人,2024 年)和 Téulu 2(Ivison 等人,2023 年),以奠定最近关于 RLHF 方法的辩论的基础,并展示它们不足的特定数据集。
使用这些模型,我们比较了缩放、测试推理能力、突出三个拒绝行为桶,并分享了有关 RM 内部工作的更多细节。随附的代码库为许多模型变体提供了一个通用的推理堆栈,我们发布了许多文本分数对来分析它们的性能。通过 REWARDBENCH,我们:
1. 发布一个通用框架,用于评估奖励模型的许多不同架构,以及可视化、训练和其他分析工具。我们还发布了评估中使用的所有数据,由所有输入的文本分数对组成,以便对奖励模型的属性进行进一步的数据分析。1
2. 说明 DPO 和基于分类器的奖励模型在各种数据集中的差异。DPO 模型虽然由于方法的简单性而更丰富,但无法推广到流行的偏好数据测试集,并且在性能上呈现更高的方差。
3. 绘制当前最先进的奖励模型的图景。我们展示了流行 RM 的缩放定律、拒绝(或不拒绝)倾向、推理能力等。
4. 展示评估这些模型的现有偏好数据测试集的局限性,展示 RM 在微妙但具有挑战性的指令对上的常见缺陷(例如,故意修改的拒绝响应,表面上看起来质量很高,但回答错误提示)。
2 相关作品
来自人类反馈的强化学习使用强化学习使语言模型与人类反馈或偏好保持一致(克里斯蒂亚诺等人,2017 年;齐格勒等人,2019 年)已经导致了改进的聊天模型,如 ChatGPT(舒尔曼等人,2022 年)和 Llama2(Touvron 等人,
2023)。以这种方式将人类反馈纳入模型已被用于改进摘要(Stiennon et al.,2020; Wu et al.,2021)、问答(Nakano et al.,2021)、图像模型(Lee et al.,2023)和一般指令遵循(OuYang et al.,2022)。
RLHF 通常关注偏好的方面,这些方面可以是更通用的概念,如有益或无害(白等人,2022a),也可以是更细粒度的概念(吴等人,2023)等。一般来说,RLHF 涉及根据从众包工作者(Wang 等人,2024)(或从 LM 选择的响应(白等人,2022b))收集的偏好数据训练奖励模型。给定奖励模型,可以使用 PPO 等 RL 算法学习策略(Schulman 等人,2017),这已被证明对语言策略有效(Ramamurthy 等人,2022)。另一种选择是使用 DPO(Rafailov 等人,2023)直接优化选择和拒绝对的策略。一些奖励建模扩展包括过程奖励模型(罗等人,2023;莱特曼等人,2023)和逐步奖励模型(哈弗里拉等人,2024b),它们主要用于推理任务。
奖励模型和 RLHF 评估偏好调整模型可以使用下游评估来评估,例如使用羊驼农场(Dubois et al.,2024),其中 LMs 用于通过将模型生成的输出与参考模型的输出进行比较来模拟人类偏好。报告的指标是模型对参考模型的胜率。类似地,MT-Bench(郑等人,2023)评估聊天机器人在多轮对话中的聊天机器人,这些对话由 LMs 作为人类判断的代理进行判断,聊天机器人竞技场(郑等人,2023)众包两种不同模型输出之间的偏好。这些类型的设置仅间接评估奖励模型。其他作品,直接分析奖励模型,如 Singhal 等人(2023),他们通过查看 RMs 的训练动态发现了输出长度和奖励之间的强相关性。另一个分析着眼于奖励不一致,通过创建对比指令的基准(沈等人,2023)。克莱默等人(2023)研究分布转移下的奖励模型性能。
1 数据在这里:https://huggingface.co/datasets/allenai/reward-bench-results。
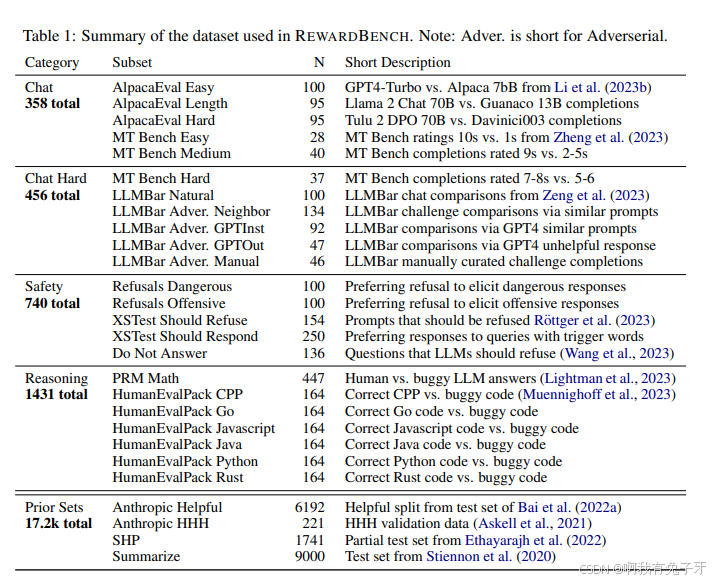
图 1:REWARDBENCH 评估套件的评分方法。每个提示都伴随着一个选择和拒绝的完成,由奖励模型独立评分。
3 背景
奖励建模训练奖励模型并因此进行 RLHF 的第一步是从一组人类标记者那里收集偏好数据。向个人展示类似于问题或任务的提示 x,并要求他们在一组完成之间进行选择,,以回答请求。最常见的情况是仅显示两个完成,并测量偏好,例如输赢平局或李克特量表,指示完成之间的偏好程度(白等人,2022a),尽管存在其他标记方法,例如在一批 4 + 答案中排名(欧阳等人,2022 年)。生成的数据被转换为一组 prompt-chosenrejected 三人组,其中选择的完成优先于被拒绝的完成进行训练。训练奖励模型涉及训练分类器来预测人类偏好概率,,在两个答案之间,如 Bradley-Terry 模型(Bradley and Terry,1952)所建模的那样:然后,通过优化最大似然损失来估计 RM 的参数,如下所示:C(6。对于语言模型,RM 通常通过附加线性层来预测一个 logit 或移除最终的解码层并用线性层替换它们来实现。在推理时,经过训练的奖励模型返回一个标量,这样(直观上是完成 (∣)() 将是首选响应的概率,但通过成对损失间接训练)。因此,当直接偏好优化直接偏好优化解决 RLHF 问题而无需学习单独的奖励模型时,完成和之间取得了胜利。它通过仅使用策略模型重新参数化基于偏好的奖励函数来实现这一点(Rafailov et al.,2023)DPO 中使用的隐式奖励是策略模型概率(即被训练的模型)、、正则化常数 β、基本模型概率和分区函数给定两个完成提示,我们将奖励和进行比较,其中分数是通过的对数比率计算的
4 REWARDBENCH 基准
在本节中,我们详细介绍了评估数据集的设计理念和构建。该数据集旨在为奖励模型提供广泛的基本评估,涵盖聊天、指令跟随、编码、安全性和其他微调语言模型的重要指标。REWARDBENCH 数据集包含现有评估提示完成对的组合,以及为该项目策划的组合。
图 1:REWARDBENCH 评估套件的评分方法。每个提示都伴随着一个选择和拒绝的完成,由奖励模型独立评分。
4 REWARDBENCH 基准
在本节中,我们详细介绍了评估数据集的设计理念和构建。该数据集旨在为奖励模型提供广泛的基本评估,涵盖聊天、指令跟随、编码、安全性和其他微调语言模型的重要指标。REWARDBENCH 数据集包含现有评估提示完成对的组合,以及为该项目策划的组合。
一个好的奖励函数,也就是一个广泛的好的 RM,是一个稳定地将信用分配给好的或坏的内容类别的函数。给定一个经过验证的答案,由于事实或明确的定性原因(例如拼写错误),一个好的奖励模型将 100% 的时间选择正确的答案。为了评估这一点,每个数据点都由一个提示和两个完成组成,选择和拒绝。对于每个提示,计算奖励模型的分数。如果经过验证的选择完成的提示的分数高于经过验证的拒绝完成的提示的分数,则提示被归类为胜利,如图 1 所示。最后,我们将每个子集的准确性报告为胜利的百分比。对于 REWARDBENCH(例如聊天或安全)的所有部分分数,除了先前集,平均分数在必要的子集中对每个提示进行加权。
4.1 REWARDBENCH 数据集
基准测试从不同的子集分为五个部分 —— 前四个组成了本节中描述的 REWARDBENCH 数据集。我们将数据集分解为这些子部分,以创建最终的 REWARDBENCH 分数,以便合理权衡 RM 性能的不同方面。RewardBench 数据集在 ODC-BY 许可证下发布,代码在 Apache下发布。数据集的摘要显示在选项卡中。1(详见附录 F)在高层次上,子集包括以下内容:
1. 聊天:测试奖励模型在开放式生成中区分彻底和正确的聊天响应的基本能力。提示和被选择、被拒绝的对选自 AlpackaEval(Li et al.,2023b)和 MT Bench(郑 et al.,2023),两个流行的开放式聊天评估工具。
2. 努力聊天:测试奖励模型理解技巧问题和微妙不同指令响应的能力。提示和选择、拒绝对是从 MT Bench 示例中选择的,这些示例具有相似的评级和对抗性数据,专门用于愚弄 LLMBar 评估集中的 LLM as-a - 判断工具(Zeng et al.,2023)(为 RM 重新格式化)。
3. 安全性:测试模型拒绝危险内容和避免对类似触发词的不正确拒绝的倾向。提示和选择,拒绝对从数据集 XSTest(Réottger et al.,2023)、Do-No - 答案(Wang et al.,2023)的自定义版本中选择,以及来自 AI2 正在开发的拒绝数据集的示例,其中选择的响应是拒绝,被拒绝的是危险或冒犯性质的有害文本。
4. 推理:评估模型代码和推理能力。代码提示是通过使用选择的正确代码重新格式化 HumEvalPack 示例来创建的,并作为有错误的代码被拒绝(Muennighoff et al.,2023)。推理提示将参考答案与来自 PRM800k 数据集的不正确模型生成配对(Lightman et al.,2023)。
5. 先前设置 4:为了与最近在训练奖励模型上的工作保持一致,我们对现有偏好数据集的测试集进行了平均性能。我们使用了人类有用的分裂(白等人,2022a)(唯一的多圈数据)、大长凳的人类 HHH 子集(Askell 等人,2021 年)、斯坦福人类偏好(SHP)数据集的测试集的精选子集(ethayarajh 等人,2022 年)和 OpenAI 的学习总结数据集(Stiennon 等人,2020 年)。
4.2 REWARDBENCH 评分
REWARDBENCH 是通过准确度来评分的。对于每个 prompt-chosen-rejected 的三重奏,我们推断 RM 为提示选择和提示拒绝对分配的分数,然后当选择的分数高于拒绝时分配一个真正的分类标签,如图 1 所示。关于分类器和 DPO 模型的计算分数的详细信息在第 3 节。给定二个任务,随机模型实现 50% 的结果。为了创建一个有代表性的单一评估分数,我们混合对结果进行平均。对于第 4.1 节中详述的部分,除了推理,我们在子集上执行每个提示的加权平均分类以获得标准化的部分分数。例如,在聊天中,我们根据
2ODC-BY:https://opendatacommons.org/licenses/by/1-0/3 Apache 2.0:https://www.apache.org/licenses/LICENSE-2.04对于最终的 RewardBench 分数,由于多种因素,我们将先验集类别的权重定为其他类别的 0.5:噪声、缺乏明确定义的任务等。数据集可在此处找到:https://huggingface. co/datasets/allenai/preference-test-sets
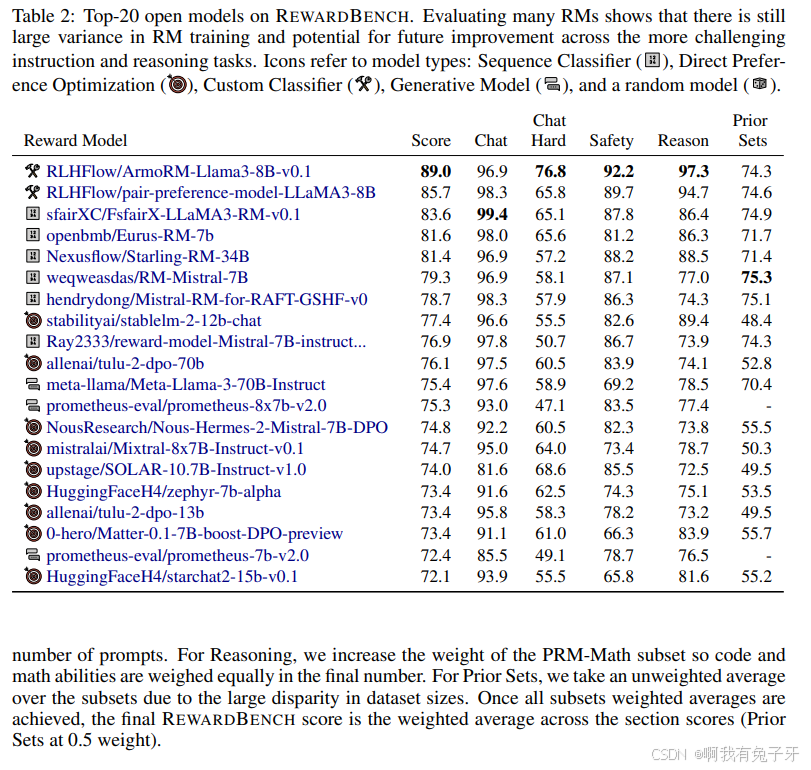
表 2:REWARDBENCH 上的前 20 个开放模型。评估许多 RM 表明,RM 训练仍然存在很大差异,并且在更具挑战性的指令和推理任务中还有未来改进的潜力。图标指的是模型类型:序列分类器()、直接偏好优化()、自定义分类器()、生成模型()和随机模型()。
提示的数量。对于推理,我们增加 PRM-Math 子集的权重,以便代码和数学能力在最终数字中得到同等权重。对于先验集,由于数据集大小的巨大差异,我们对子集取未加权平均值。一旦实现所有子集的加权平均值,最终的 REWARDBENCH 分数就是各部分分数的加权平均值(先验集权重为 0.5)。
5 评估结果
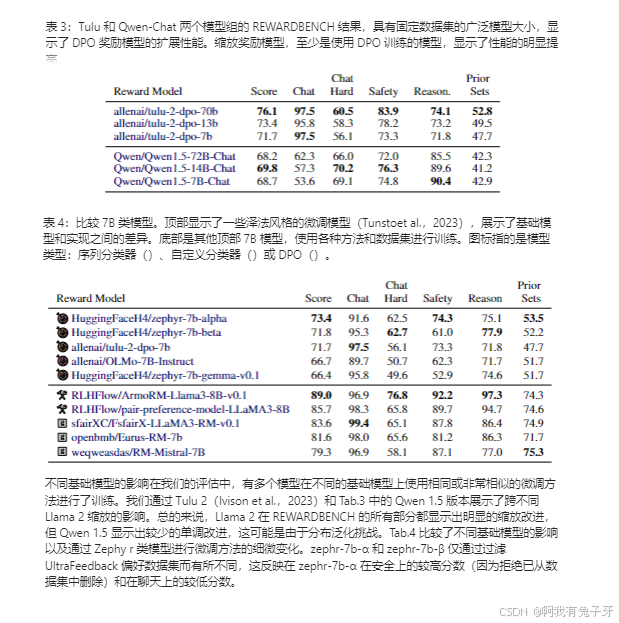
REWARDBENCH 包括对许多公共奖励模型的评估,包括从 4 亿(PairRM)到 700 亿(Téulu 2)的参数计数,作为分类器训练或使用 DPO(当参考模型可用时)。在本节中,我们详细介绍了 REWARDBENCH 的核心发现,附录 E 中提供了更多结果。特别是,我们研究了最先进的奖励模型(表 2)、7B 类似规模模型的结果(表 4),以及表 3 中扩展 DPO 奖励模型对绩效的影响的演示。我们进一步研究了当前奖励模型(第 5.2 节)和先前测试集(第 5.3 节)的限制。
5.1 比较最先进的奖励模式
选项卡 2 显示了不同模型大小和类型的前 20 个模型的结果。大型模型和在骆驼 3 上训练的模型是唯一能够在聊天困难和推理部分获得高性能的模型,模型 ArmoRM-Llama3-8B-v0.1(89)是最先进的。在不同的基础模型中,比例是一个至关重要的属性,在易 34B 上训练的斯特林 - RM-34B(81.4)和骆驼 2 上训练的图鲁 - 2-DPO-70B(76.1)是顶级模型。LLMas-a-Juder 的最佳开放权重模型是 Meta-Llama-3-70B-Instruct(75.4)和普罗米修斯 - 8x7b-v2.0(75.3)(Kim 等人,2024 年),尽管它们仍然远低于基于分类器的 RM。最后一类由小型、最容易获得的模型组成,其中主要模型是 StableLM - 泽法 - 3b(70.6)和 oasst-rm-2.1-pythia-1.4b - 纪元 - 2.5(69.5),但仍有很大的进步空间。
奖励函数的不同形状每个提示分数展示了在 REWARDBENCH 评估数据集上分配给每个奖励模型的奖励的不同大小和分布。附录 E.1 中显示的结果,如图 7 所示,显示了一些训练为分类器的 RM 的这些分布。在 REWARDBENCH 数据集中,很少有 RM 的分数是高斯的,更少的 RM 以 0 奖励为中心,没有一个我们测试的是以高斯为中心的。未来的工作应该确定下游 RL 训练的首选 RM 输出分布。
5.2 当前奖励模式的限制
当前的奖励模型可以可靠地解决 REWARDBENCH 的一些子集,接近 100% 的准确率,但是许多子集经历了性能上限低或性能方差高的组合。上限低的子集,主要在聊天困难和推理部分
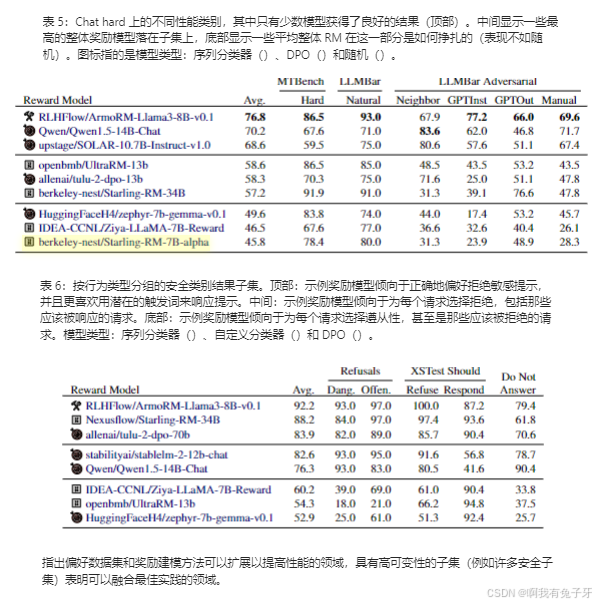
评估聊天困难类别选项卡 5 比较了聊天困难类别中不同的奖励模型(完整结果显示在选项卡 11 中)。LLMBar(Zeng et al.,2023)中的对抗性子集对于理解 RM 至关重要,因为它们显示了两个答案以相似风格编写的示例(例如相同的 GPT-4 模型版本),但主题略有不同。询问有关相关但不同对象的事实问题或稍微改变提示的上下文之间的区别,很难在大多数奖励模型中得到体现。聊天困难部分(以及在某种程度上的推理)在很大程度上与最终性能相关,但一些 DPO 模型在这方面表现出色,而不是总体表现 —— 甚至 Qwen Chat 和其他总体平均性能较低的模型。得分高的模型在最近的基本模型和偏好数据集上进行训练,展示了 RM 训练的最新进展。
跨推理类别评估 REWARDBENCH 的推理部分具有最广泛、最平滑的性能变化 —— 例如,模型填充了许多级别,从 35% 的准确率(远低于随机)一直到 97% 的准确率。推理数据主要依赖于代码示例,其中选择和拒绝的样本之间只有一两个标记不同,展示了最佳 RM 的精确分类能力。完整的推理结果包含在选项卡中。13.
跨安全指标评估选项卡 6(完整结果见附录选项卡 12)比较了不同安全类别的不同奖励模型,表明在拒绝太多或不拒绝之间取得平衡的挑战。模型,如 UltraRM-13b 和 zephr-7b-gemma-v0.1 显示了一个专注于帮助性的模型如何在安全部分的应拒绝子集上得分低,但在 XSTest 应响应上得分高。其他模型,即总体排行榜顶部的模型,显然在训练过程中包含安全信息,并在可能导致错误拒绝的技巧问题上保持出色的表现(XSTest 应响应)。最后,镜像行为,那些在应该拒绝的提示上得分高,在不应该出现的提示上得分低的模型,表明一个可能错误拒绝查询的模型(例如 Qwen 聊天模型)。这三种行为模式表明 REWARDBENCH 可以用作候选模型安全行为的快速检查,尤其是在使用 DPO 进行训练时(因为它不需要像分类器那样进行进一步的 RL 训练)。
5.3 先前测试集的限制
许多使用 RLHF 训练的流行模型使用新的偏好数据集,如 UltraFeedback(崔等人,2023 年)或 Nectar(朱等人,2023a 年),它们没有公开可用的验证集。有鉴于此,在训练奖励模型时,常见的做法是将模型协议与 RLHF 早期工作中的各种现有测试集进行比较。一些在 REWARDBENCH 的先验集部分得分很高的模型,如 UltraRM-13b 和 PairRM-hf,在人类 HH、斯坦福人类偏好(SHP)和 OpenAI 的学习总结的训练分裂上进行了训练,但其他顶级分类器模型,如 Starling 模型则没有。将这一点与 DPO 模型在这些测试集上的非常低的平均得分相结合,表明需要进行大量研究来了解这些先前数据集的全部局限性。完整结果详见表 14。
6 结论
我们展示了 REWARDBENCH,并展示了当前奖励模型的各种性能特征,以提高对 RLHF 的理解。虽然我们涵盖了对 LM 对齐很重要的各种主题,但需要采取关键的下一步来将 REWARDBENCH 中的性能与 RLHF 有用性相关联。使用 N 最佳抽样对 RM 进行排名和使用 PPO 进行下游训练的初步实验正在进行中。我们已经迈出了第一步,了解哪些值嵌入了跨许多基本模型和偏好数据集的 RLHF 训练中。我们发布的工具包可以很容易地扩展,包括自定义数据,以专门审计 RLHF 过程的某个属性。来自私人 LM 提供商的许多 RM 出现在公共排行榜上,但没有出现在论文中,因为它们不可重现。REWARDBENCH 是众多工具之一,它将帮助我们了解谁和什么值嵌入到我们的语言模型中的科学。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









