






9.Shunted-Transformer
1.研究背景:
ViT模型在各种计算机视觉任务中表现出令人鼓舞的结果,这要归功于它们通过自注意对图像patch或token的长期依赖进行建模的能力。目前的视觉Transformer模型通常为每一层中的每个标记特性指定相似的接受字段。这种约束不可避免地限制了每个自注意层捕捉多尺度特征的能力,从而导致在处理具有不同尺度的多个对象的图像时性能下降。
2.存在问题:
1. 自注意机制带来了昂贵的内存消耗成本。通过提前下采样方法解决会导致特征信息的丢失,通过在一层自注意合并token的方法会导致小物体的细粒度信息与背景混合在一起,使得模型在捕获小对象时效率降低;通过局部自注意不方便获得全局依赖关系。
2. 之前的Transformer模型在很大程度上忽略了自注意层内场景对象的多尺度性质。

3.改进思索:
引入了一种新颖而通用的自注意方案,称为分流自注意(SSA),它明确地允许同一层中的自注意头分别考虑粗粒度和细粒度特征。与之前合并太多token导致无法捕获小对象的方法不同,SSA有效地在同一层的不同注意力头同时对不同规模的对象进行建模,使其具有良好的计算效率的同时保留细粒度细节。
4.解决方案:
1.SSA:SSA降低了计算难度的同时,实现了对大目标和小目标的的处理。SSA的多尺度注意机制是通过将多个注意头分成若干组来实现的,每个组都有一个专门的注意力粒度。对于细粒度的组,SSA学会了聚合少量的令牌并保留更多的本地细节;对于粗粒度头组,SSA学会了聚合大量的令牌,从而在保留捕获大对象的能力的同时降低了计算成本。
1.SSA为每个自注意层引入了分流注意机制,以捕获多粒度的信息,更好地对不同大小的对象,特别是小对象进行建模。
2.通过增加跨token交互,增强了在点向前馈层提取局部信息的能力。
3. 采用了一种新的patch嵌入方法,为第一个注意块获得更好的输入特征映射。

模型分为四个阶段,每个阶段包含几个Shunted Transformer块。在每个阶段,每个块输出相同大小的特征图。我们使用一个带有stride 2(线性嵌入)的卷积层来连接不同的阶段,在进入下一阶段之前,特征图的大小将减半,但维度将增加一倍。

2.多尺度注意力:当r变大时,K, V中合并的token更多,K, V的长度更短,因此计算成本较低,但仍保留了捕获大对象的能力;当r变小时,虽然保留了更多的细节,但也带来了更多的计算成本。将各种r集成到一个自注意层中,使其能够捕获多粒度的特征。
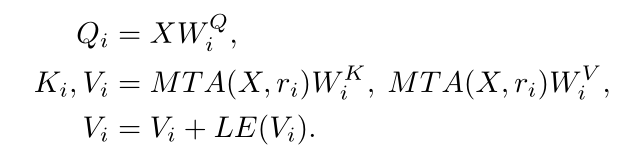
3.特定细节的前馈层:通过在前馈层的两个全连接层之间添加我们的数据特定层来补充前馈层中的局部细节。
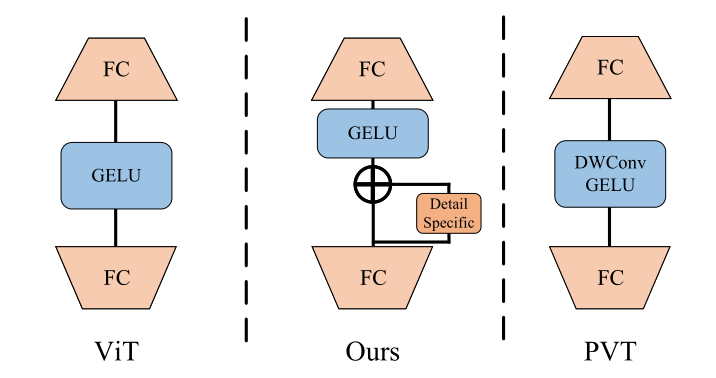
4.Patch Embedding:根据模型大小取不同的重叠卷积层。1.将一个步幅为2、填充为0的7 × 7卷积层作为patch嵌入的第一层;2.根据模型大小额外增加步幅为1的3 ×3卷积层;3.采用步幅为2的不重叠投影层,生成大小为h/4 × w/4的输入序列。
4.成果对比:
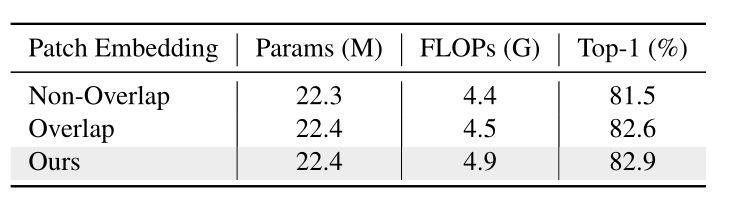
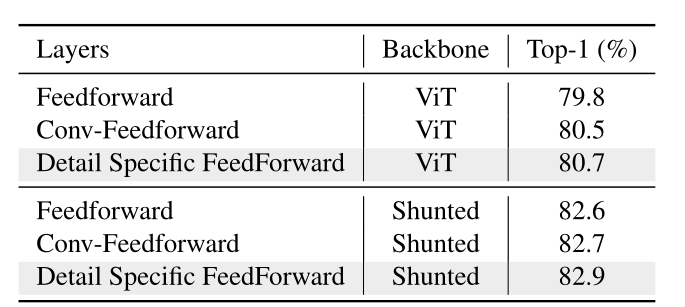


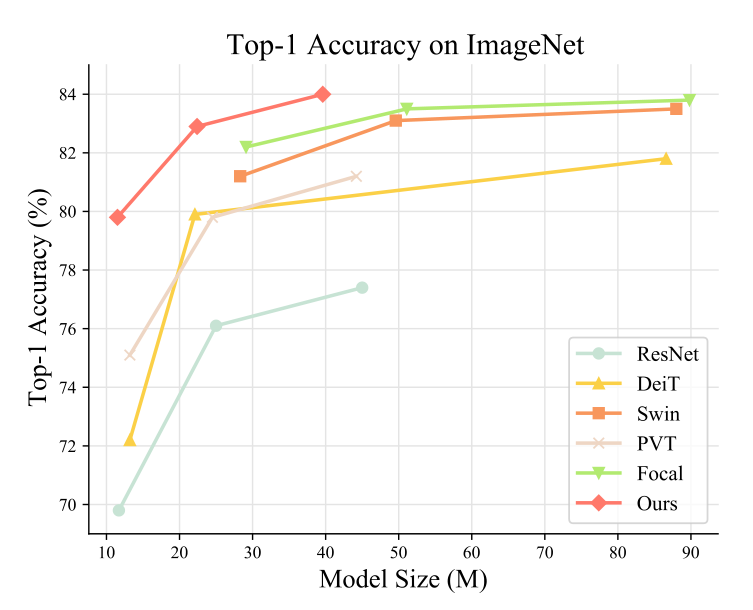
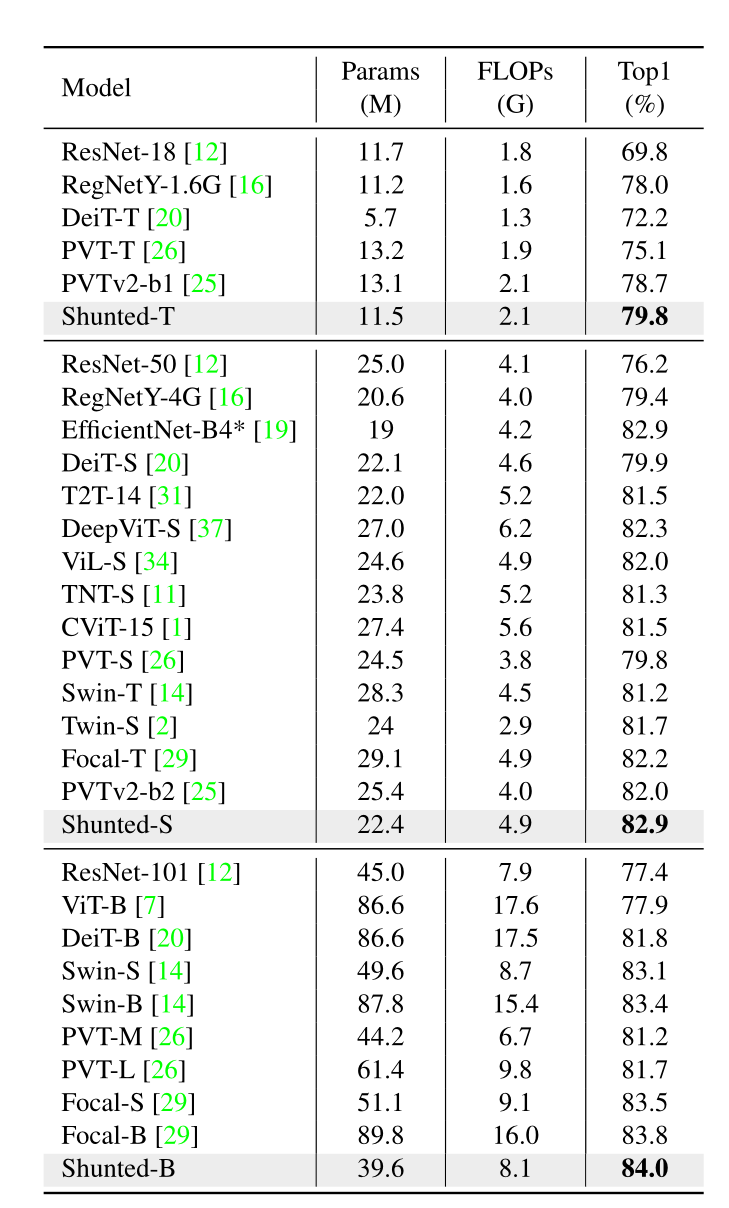

6.特点总结:
1.提出了分流自注意(SSA),通过多尺度token聚合将多尺度特征提取统一在一个自注意层中,其自适应地合并大对象上的token以提高计算效率,并保留小对象的token。
2. 在SSA的基础上构建了能够有效捕获多尺度目标,特别是两个小的远程孤立目标的分流变压器。
3.提出的分流Transformer性能始终优于以往的视觉Transformer。















 271
271











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









