






论文阅读:Target localization based on cross-view matching between UAV and satellite
QATM套壳 原理可直接去看QATM CVPR2019,相当于做了一个应用
匹配由无人飞行器(UAV)拍摄的遥感图像与具有地理定位信息的卫星遥感图像,从而确定由UAV捕获的目标对象的具体地理位置。其主要挑战在于卫星和UAV获取的遥感图像在视觉内容上的显著差异,例如视角的剧烈变化、未知的方向等。许多先前的工作都集中在同源数据的图像匹配上。为了克服这两种数据模式之间的差异带来的困难,并在视觉定位中保持鲁棒性,本文提出了一种基于尺度自适应深度卷积特征的质量感知模板匹配方法,通过深入挖掘它们的共同特征。首先获取模板大小特征图和参考图像特征图。然后使用这两个获得的特征图来测量相似性。最后,生成一个表示匹配概率的热图,以确定参考图像中的最佳匹配。该方法应用于最新的基于UAV的地理定位数据集(University-1652数据集)和我们用UAV收集的真实场景校园数据。实验结果证明了该方法的有效性和优越性。
1. Introduction
在过去十年左右的时间里,遥感技术发展迅速。与此同时,遥感平台也在全面发展,如地面、无人机和卫星平台。无人机和卫星在这方面发挥着至关重要的作用,是获取遥感图像的主要工具。无人机具有机动性和灵活性、隐身、低成本、获取的信息丰富和全面的飞行覆盖等独特特点。基于无人机航拍图像的信息处理、分析和识别技术广泛应用于搜救、工业巡查、地形测绘、精准农业、生态环境监测、野生动物监测保护等方向。近年来,其相关研究也成为图像处理、计算机视觉、模式识别等领域的重要研究方向。卫星遥感图像具有丰富的视觉信息,在目标检测、定位、跟踪、监视等过程中发挥着重要作用。
大多数传统的无人机飞行导航依赖于惯性制导、GPS等提供的信息。缺乏GPS可能会导致定位不可用。GPS的精度和抗信号干扰往往无法满足现代无人机定位导航的需求。随着图像传感硬件和图像处理技术的发展,计算机视觉技术9和人工智能技术10正在逐步引入无人机的定位和导航中。越来越多的无人机配备了结合人工智能技术的图像传感器系统,提供更准确的定位和导航信息。基于图像传感器的视觉定位和导航的潜力巨大。它可以达到相当的准确度,降低无人机平台的成本,并在信号干扰不可用的情况下取代GPS,具有重要的现实意义。
目前应用于无人机视觉定位和导航的方法主要是图像配准。具体可以描述四大类:模板匹配、特征点匹配、基于深度学习的图像匹配和视觉里程表匹配。一般来说,无人机早期的视觉定位和导航工作主要是密集或直接匹配。无人机的观察作为模板在地图中进行匹配。图像匹配算法,例如绝对差和(SAD)、11平方差和(SSD)、12和标准化互相关(NCC)13用于比较两个图像或块的相似性。但它们的主要缺点是计算量大、计算时间长。
本文提出了一种基于规模自适应深度卷积特征的质量感知模板匹配方法(quality-aware template matching method based on scale-adaptive deep convolutional features.)。首先对无人机图像和卫星遥感图像的典型干扰进行图像预处理,消除外部影响,获得尽可能真实的图像信息。VGG-1626网络在University-1652数据集和真实场景数据集上训练。然后使用训练好的VGG-16网络分别提取无人机图像和卫星遥感图像的多维特征,并使用比例自适应方法选择合适的feature map。最后计算两个feature map的相似度。根据匹配的可能性获得最佳匹配结果。在大比例尺高分辨率卫星图像中可以找到无人机拍摄图像对应的区域。
本文的贡献如下:
-
提出了一种基于尺度自适应深度卷积特征提取的质量感知模板匹配方法,用于评估不同视角图像之间的相似度。通过提取规模自适应的深度卷积特征,可以处理各种尺寸的目标模板图像,简化特征提取过程。我们提出的方法在速度方面具有很大优势。
-
训练后的模型提高了对真实场景中目标物体的描述能力以及对视角变化的抵抗能力,该方法的性能不仅在公共数据集(University-1652)上得到了定量和定性的证明,而且在真实场景无人机数据上也具有一定的有效性和优越性。
-
真实场景无人机数据集非常稀缺,而且这种数据集新颖,可以更有效、更真实地反映无人机飞行中的视角状况。
2. Method
2.1 Overview
我们使用无人机捕获的目标物体图像作为模板图像(template image) T ∈ R w × h × 3 T\in R^{w\times h\times3} T∈Rw×h×3,使用卫星遥感图像作为参考图像(reference image) S ∈ R m × n × 3 S\in R^{m\times n\times3} S∈Rm×n×3。目的是在大尺度高分辨率参考图像 S S S中找到与模板图像 T T T对应的区域,如图1所示。我们使用 m m m和 n n n来表示参照图片的宽度和高度, w w w和 h h h代表模板图像的宽度和高度。为了完成这一任务,我们提出了一种基于规模自适应深度卷积特征的质量感知模板匹配方法。第2.2节描述了规模自适应深度卷积特征提取方法。考虑到匹配定位的稳定性,在2.3节中将深度网络特征提取与基于QATM的图像匹配方法相结合。
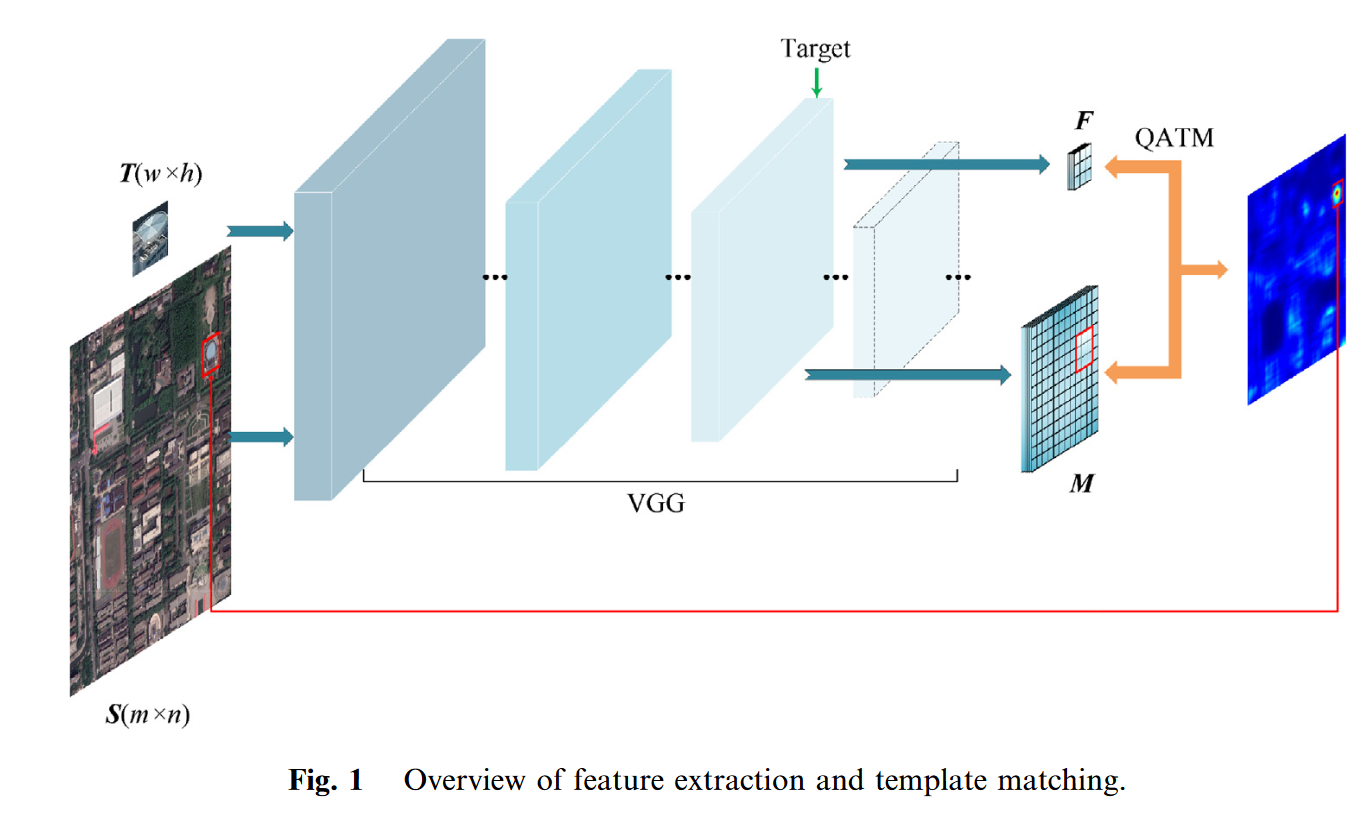
2.2. Deep convolutional feature extraction based on scale adaptation
VGG网络使用重复堆叠的小卷积核而不是大卷积核。这种方法提高了网络的深度和提取特征的能力,同时确保相同的感知领域。我们分别对模板图像和参考图像使用经过训练的VGG-16网络来提取用于图像匹配的多维特征。基于卷积神经网络(CNN)的特征提取方法如图2所示,该方法首先需要将输入图像缩放到固定大小,例如,224像素 224像素。然后通过网络中的每一层执行特征提取。
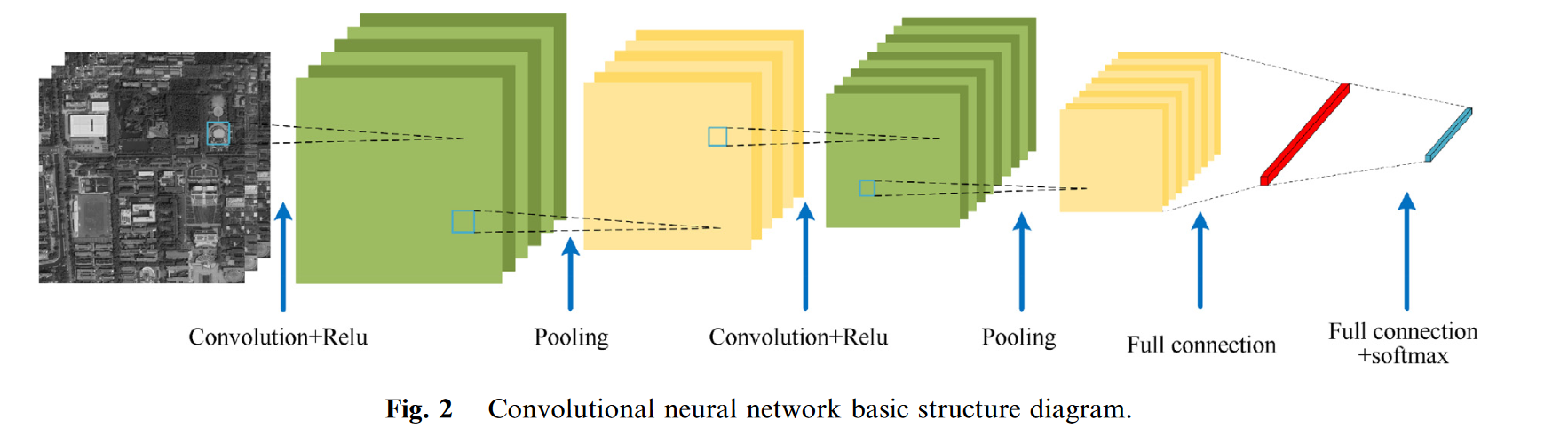
由于遥感图像中的像素数量极其庞大,而且大多数特征提取过程都是卷积运算,因此随着网络深度的增加,遥感图像处理的计算成本和时间成本也不断增加。而且,目标的规模是不连续的,缩放其输入会导致细节损失,影响匹配效果。为了解决这个问题,我们提出了一种基于规模自适应深度卷积特征提取的方法。
CNN中的不同层代表图像的各种深度特征。27我们将模板图像和参考图像直接输入到VGG网络,而无需缩放它们。然后根据模板的大小选择合适的目标层,并从目标层中提取特征图。CNN中的每个层都有一个感受野,它代表通过每个层输出的特征地图上的像素点映射到原始图像上的区域的大小。第
k
k
k层的感受野的宽度计算如下。
l
k
=
l
k
−
1
+
(
r
k
−
1
)
∏
i
=
1
k
−
1
s
i
k
>
1
l_{k}=l_{k-1}+(r_{k}-1)\prod_{i=1}^{k-1}s_{i}\quad k>1
lk=lk−1+(rk−1)i=1∏k−1sik>1
其中
l
k
−
1
l_{k-1}
lk−1表示第(
k
−
1
k-1
k−1)层的感知场,
r
k
r_k
rk表示第
k
k
k层的卷积核大小,
s
i
s_i
si表示第
i
i
i层的步长大小。当我们的模板大小小于一个层的感知场的大小时,那么该层将处理很多毫无意义的区域。在很大程度上会造成计算的浪费。因此,我们选择的目标层的感知场应该小于或等于模板的大小。当满足
l
k
≤
min
(
w
,
h
)
l_k\leq \text{min}(w, h)
lk≤min(w,h)时,我们选择第
k
′
k'
k′个(
k
′
≤
k
k'\leq k
k′≤k)层作为特征选择的目标层 。对于
k
′
k'
k′的选择,我们将在第3.2.1节中具体讨论。然后,我们将模板图像和参考图像输入CNN,并从选择的目标层中提取模板feature map
F
F
F和参考图像feature map
M
M
M。
2.3. Image matching based on quality-aware template matching
由于无人机航拍图像和卫星遥感图像之间的视角变化和方向变化剧烈,导致两者获取的视觉内容差异很大。之前的一些模板匹配算法将不再适用。每种算法的匹配效果将在第3节中展示。
我们首先分别对模板
T
T
T 和图像
S
S
S 进行规模自适应深度卷积特征提取,获得模板特征地图
F
F
F和图像特征地图
M
M
M。受文献33的启发,我们使用
D
(
b
,
a
)
D(\boldsymbol{b,a})
D(b,a) 来表示好或坏匹配的程度,其中
a
a
a 和
b
b
b 分别是模板特征地图
F
F
F 和参考图像特征地图
M
M
M 中的图像块。
f
a
f_a
fa和
f
b
f_b
fb用于表示图像块
a
a
a 和
b
b
b 的特征,而
ρ
\rho
ρ用于表示两个图像块之间的cos相似度。给定图像块
b
b
b,我们使用
P
P
P来描述模板图像块
a
a
a 的匹配概率,如等式中所示。(2)
P
(
a
∣
b
)
=
exp
{
β
⋅
ρ
(
f
a
,
f
b
)
}
∑
a
′
∈
F
exp
{
β
⋅
ρ
(
f
a
′
,
f
b
)
}
P(a|b)=\frac{\exp\{\beta\cdot\rho(f_a,f_b)\}}{\sum_{a^{\prime}\in F}\exp\{\beta\cdot\rho(f_{a^{\prime}},f_b)\}}
P(a∣b)=∑a′∈Fexp{β⋅ρ(fa′,fb)}exp{β⋅ρ(fa,fb)}
其中
β
\beta
β 是正影响因子。
a
′
a '
a′是patch,大小与patch
a
a
a 相同。在寻找图像块
b
b
b 的过程中,通过遍历整个模板图像
F
F
F ,我们可以将这个概率
P
P
P 视为对当前图像块
a
a
a 与模板中其他图像块匹配度的一个相对软性排序。
P
P
P 的值应该在0到1的范围内。
P
P
P 的值越大,表明两者之间的匹配越好,也就越相似。然后,
D
D
D 被定义为
F
F
F 中
b
b
b 匹配的概率与
M
M
M 中
a
a
a 匹配的概率的积,如等式所示。(3)。
D
(
b
,
a
)
=
P
(
a
∣
b
)
⋅
P
(
b
∣
a
)
D(b,a)=P(a|b)\cdot P(b|a)
D(b,a)=P(a∣b)⋅P(b∣a)
D
D
D 的更大值意味着
a
a
a 和
b
b
b 彼此更加相似,反之亦然。一旦获得了
D
D
D 对,就可以找到
S
S
S 中的最佳匹配区域
X
X
X ,这是具有最高总体匹配质量的区域,如方程所示。(4)。
Ω
=
arg
max
M
{
∑
b
∈
M
max
{
D
(
b
,
a
)
∣
a
∈
F
}
}
\Omega=\underset{M}{\arg\max}\left\{\sum_{{\boldsymbol{b}\in\boldsymbol{M}}}\max\left\{D(\boldsymbol{b},\boldsymbol{a})|\boldsymbol{a}\in\boldsymbol{F}\right\}\right\}
Ω=Margmax{b∈M∑max{D(b,a)∣a∈F}}
然后,根据特征地图与原始图像之间的对应关系,将特征域映射到图像空间上。最后,使用可视化方法以热图的形式表示
D
D
D 的值,以便可以直观地反映每个位置的好或差匹配程度。为此,我们可以使用最佳匹配区域作为匹配结果,从而完成目标定位的任务。
2.4. Model training and optimization
为了提高模型网络在真实场景中表示对象的能力并尽可能抵抗透视变化,我们可以使用预训练网络VGG-16来训练对象的多视图数据。我们将获取的真实场景无人机-卫星图像对与University-1652数据集混合和分类,以构建用于模型训练和优化的数据集。其中,每个位置的目标物体都有来自不同视角(无人机多角度视角和卫星视角)的大量训练数据。
目标的无人机多视图像和卫星视图像缩放为 224 × 224 224 \times 224 224×224像素作为模型的输入。总共训练了160个epochs。我们在训练过程中使用了一些数据增强策略,包括随机旋转、随机裁剪、缩放和颜色失真。损失函数是一个交叉熵损失函数,并且使用动量值为0.9的随机梯度下降(BCD)优化器对网络进行优化。初始学习率为0.001,学习率每60个历元更新为当前学习率的0.1。辍学率设定为0.5。整个模型训练过程是在NVIDIA图形处理器平台TITAN RTX上执行的。在实验阶段,我们使用经过训练的网络模型,使用基于规模自适应深度卷积特征提取的质量感知模板匹配方法来评估图像之间的相似性。
3. Experiment and analysis
3.1. Experiment setup
在我们的实验中,我们根据文献评估我们的方法。具体来说,从中给出的跟踪数据集中选择30个视频。在视频的前10帧中选择模板,并分别与视频中的其余帧形成模板参考图像对。对于每一对,我们可以在参考图像中生成一个预测框,该框定位模板的位置,如图2所示。3(a)和3(b)。由于该跟踪数据集包含地面真相数据,因此我们通过计算地面真相框和预测框的联合交集(IoU)的值并计算曲线下面积(AUC)来执行定量比较。
我们还将我们的方法与以前的方法进行了比较,例如DCIM、A-MNS、SA + NCC、QATM、2ch-2stream、2ch-deep、Siamese、SBS、NCC、SSD、HM.35
3.2. Experimental results
3.2.1. Discussion on the choice of target layer
我们利用经过训练的VGG网络进行规模自适应深度特征提取。VGG网络的结构非常简洁,卷积核大小( 3 × 3 3\times 3 3×3)和最大池化层大小( 2 × 2 2\times 2 2×2)相同,在整个网络中使用。我们选择完全连接和输出层以外的网络层,并计算它们的感知场大小,如表1所示。我们验证的模板图像的平均大小为 90 × 90 90 \times 90 90×90像素。
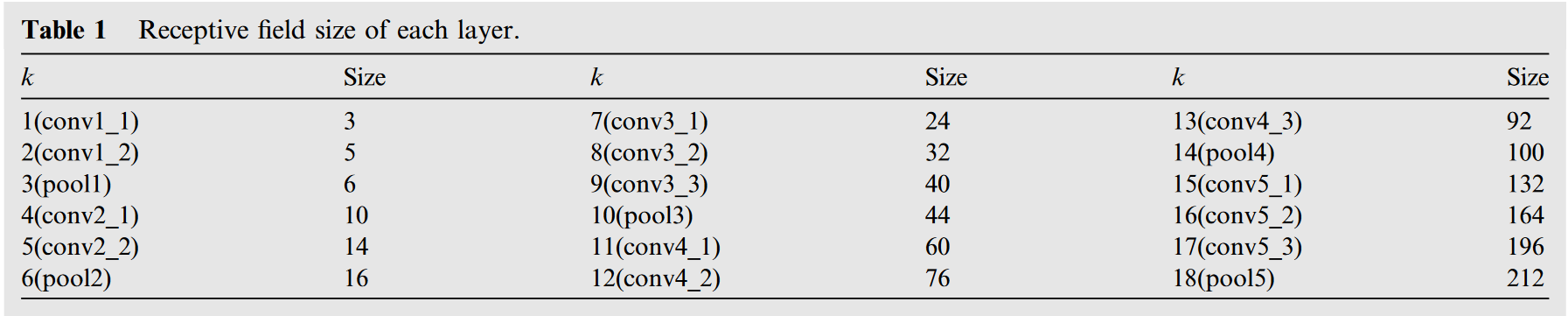
首先,将网络每一层从模板图像中提取的特征分别与模板特征进行匹配,并分析其AUC性能,如图4(a)所示。通过比较,我们发现conv3_3层的表现更好,其AUC值为0.67。
其次,对于我们的尺度自适应特征提取方法,当第 k k k 层感知场的大小满足小于或等于输入模板图像的大小时,我们取出第 k ′ k' k′层的特征图( k ′ = k − j k'=k-j k′=k−j)进行分析并验证其有效性。当 k − j ≤ 0 k-j\leq0 k−j≤0 时,令 k ′ = 1 k'=1 k′=1。如图4(b)所示,我们取 j j j 的值从0到17,当 j j j 为3时达到最佳性能。而且越接近3,例如2或4,它的性能也可以更好。

因此,我们使用第( k − 3 k-3 k−3)层作为特征提取的目标层。自适应特征提取方法在整体性能上优于固定层特征提取方法。此外,根据我们选择的模板图像大小的平均值,可以确定 k = 12 k = 12 k=12, k ′ = 9 k' = 9 k′=9。目标层即conv3_3。从图4(a)还可以看出,conv3_3也是固定层特征提取中的最佳层。
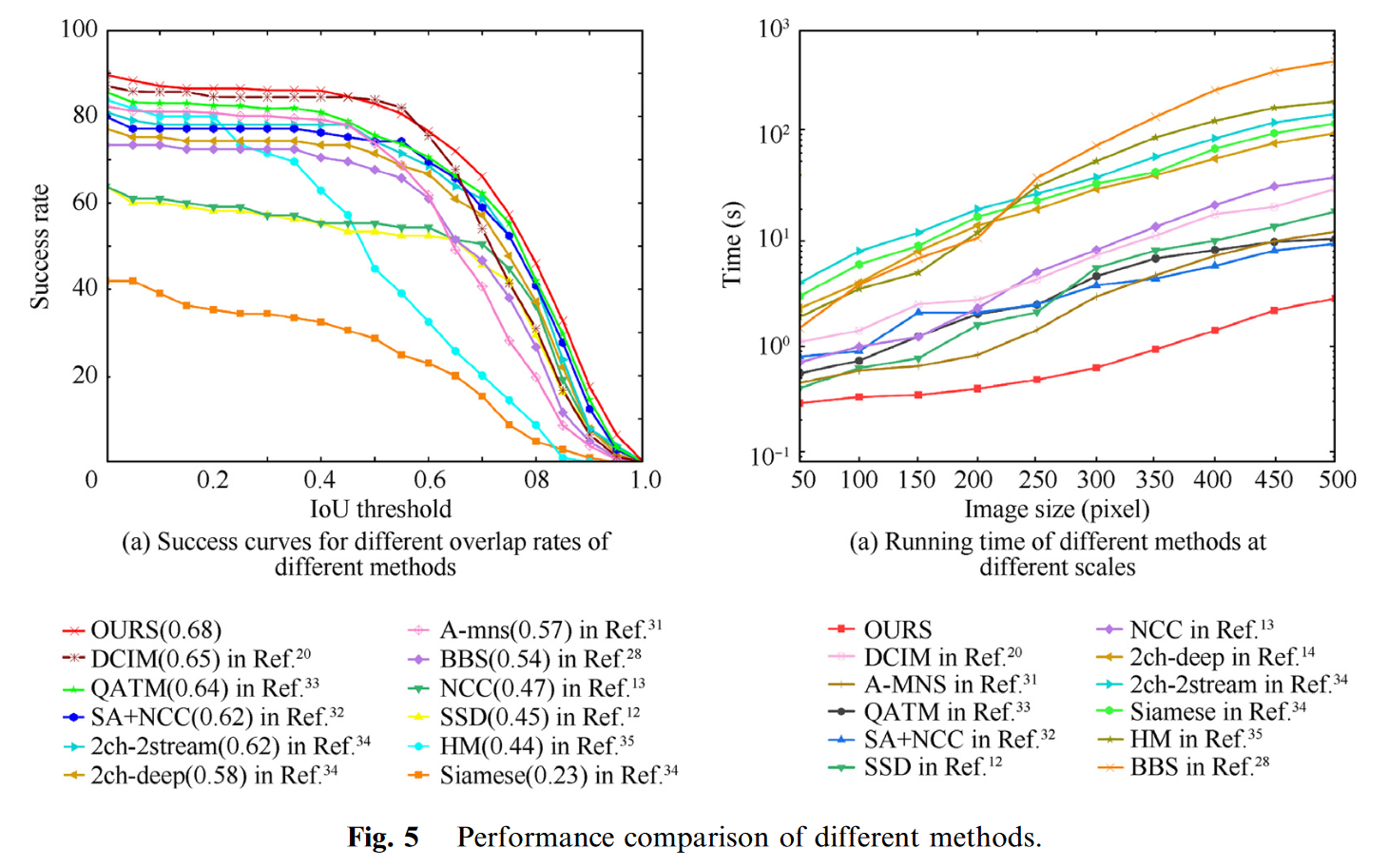
3.2.2. External comparison
为了验证该方法的有效性,我们进行了一些定量的分析。首先,如图5(A)所示,通过对成功曲线的定量分析,可以看出我们的方法的性能优于文献中的方法。在DCMI中,对于具有大视点变换的图像,在模板和参考图像之间建立点对点对应以进行模板匹配的性能较差。A-mns中使用的是一种具有旋转不变性的模板匹配方法,但对于光照变化和运动模糊的某些场景中的图像,该方法的性能较差。SA+NCC中提出了一种基于NCC的卷积神经网络,当模板与参考图像之间的变换比较复杂,并加入遮挡、背景变换等因素时,NCC的性能较差。2ch-2stream中的方法的目的相对明确,使用双通道网络来匹配两个图像块并比较它们的相似性。
根据匹配相似度排名生成匹配热图。如图3(c)所示,我们还可以看到此时匹配结果的质量,其中红色表示相似度高。
在速度方面,我们分析并比较了我们的方法与近年来的匹配算法的运行时性能。我们将图像大小限制在50像素范围内 50像素至500像素 500像素,并通过运行不同的方法比较它们的时间差。对于基于卷积神经网络的特征提取方法来说,网络层多,结构复杂,每层中的大部分操作都是卷积操作。滑动窗口也用于详尽特征提取,因此此类方法通常需要数十秒。在我们的方法中,只对图像进行一次特征提取,避免了详尽列举时的滑动窗口操作。如图5(b)所示,我们的方法在大规模图像中具有更大的优势,运行速度明显快于SBS(505.3 s),NCC、SSD、QATM和A-MNS也在数十秒内,而大多数基于CNN的方法都在数百秒或更长时间内。
3.3. Matching localization test and analysis
我们使用DJI Phantom 4 Pro拍摄南京理工大学的无人机图像,图像大小为1920像素 1080像素。我们驾驶无人机在150 m-200 m处收集20组目标物体,空间分辨率约为0.5 m-0.8 m,用于实验验证。对应的卫星遥感图像为南京理工大学上空的Google地图,卫星图像大小为2000像素 2000像素,覆盖面积1公里 1公里,空间分辨率为0.5 m,如图6所示。从左到右是:模板图像、参考图像(不同颜色表示不同方法的匹配定位结果)以及OURS、BBS、SA + NCC、QATM、AMNS、和DCIM的匹配热图。
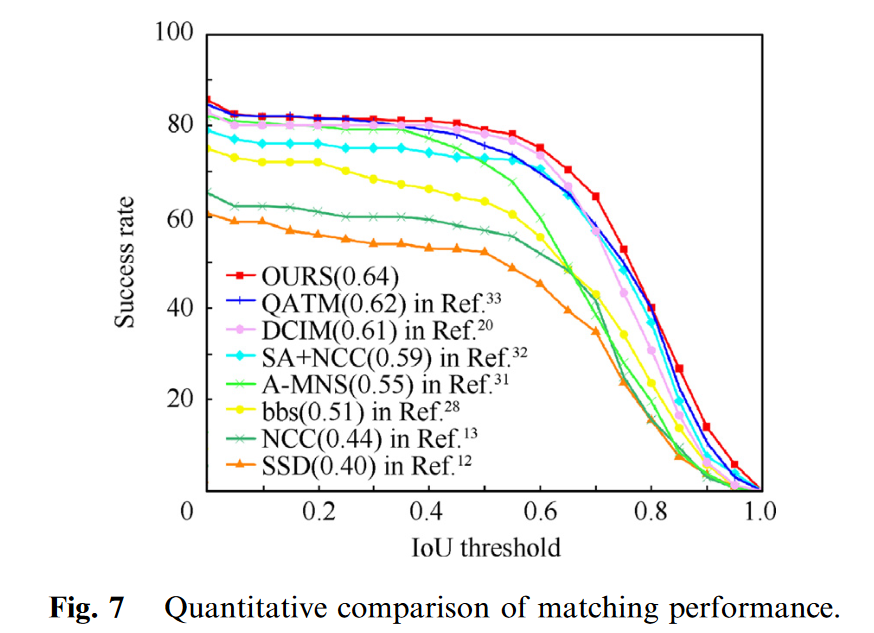
对于大比例尺卫星遥感图像来说,处理起来非常麻烦。首先,卫星图像的数据信息量大。其次,作为参考图像,噪音干扰较多,许多传统的模板匹配算法(SSD、NCC等)将导致更多的计算。它们在处理时对噪音异常敏感。同样,我们通过使用具有不同重叠率的成功曲线下面积对此进行了定量比较。如图7所示,从图中可以看出,我们的方法的曲线下面积值处于领先地位,优于其他方法。

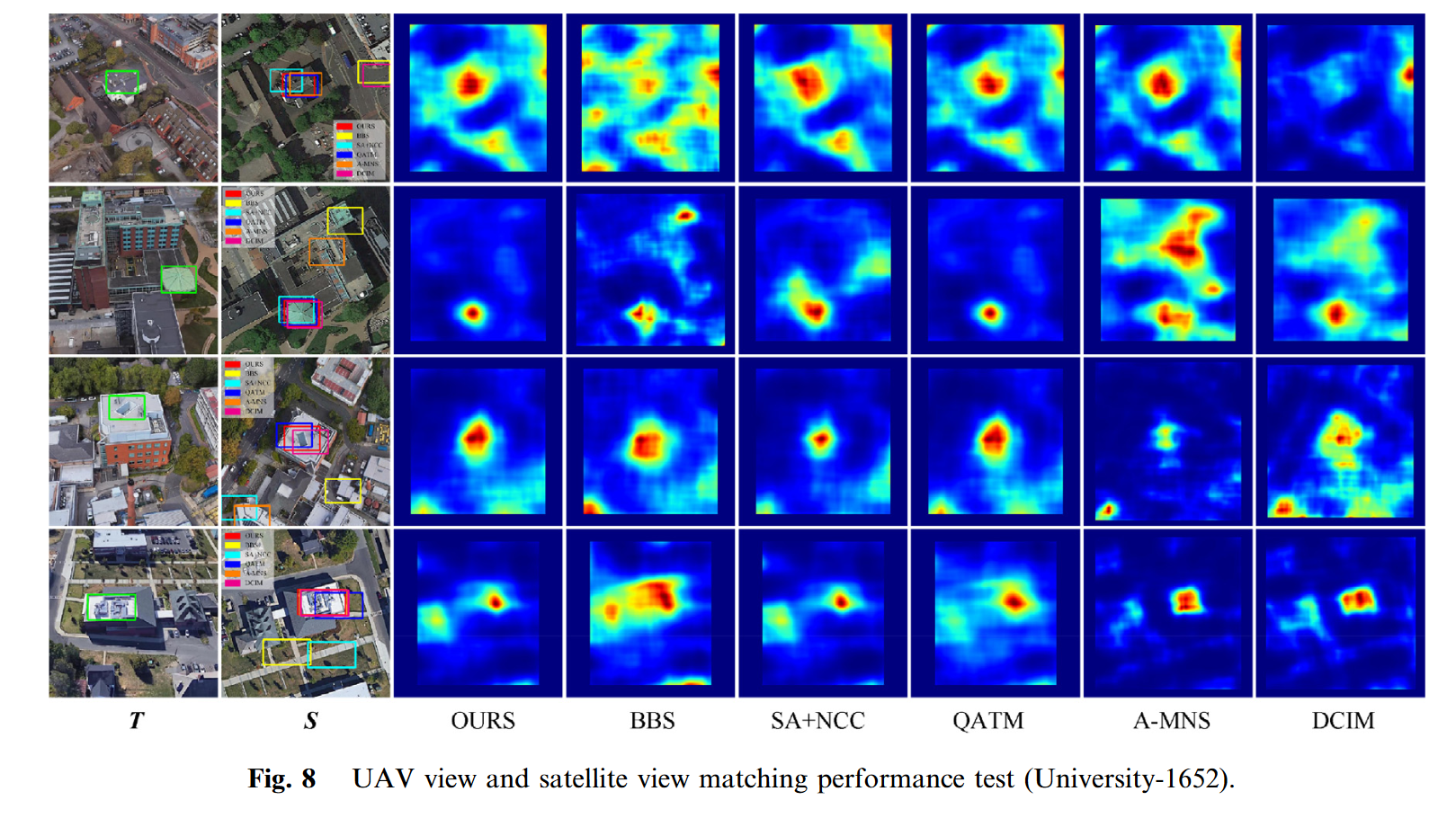
我们还从数据集University-1652中选择了一些数据进行测试,该数据集由Zheng等人23发布,包含1652个区域的三个不同视图(卫星视图、无人机视图和地面视图)。我们选择一个卫星视图和无人机视图进行模板匹配测试,如图8所示。数据集University-1652在严格意义上存在一些限制。该数据集基于不同高度模拟卫星视图和无人机视图。我们尝试选择视图差异较大的图像对(卫星视图是垂直的,而无人机视图是倾斜的)。就数据集之间而言,与之前的跟踪数据集相比,我们的方法的准确性略有下降,如表2所示。剔除匹配较差的情况下,覆盖面积1 km 1 km的卫星遥感图像的定位误差在10 m以内。
4. Conclusions
无地理信息的无人机图像定位研究具有重要意义。本文提出的基于规模自适应特征的质量感知模板匹配方法取得了良好的效果。对采集的图像进行实验验证了我们方法的可行性。通过规模自适应特征提取选择合适模板大小的特征图,以处理不同大小的模板,避免了穿越图像的冗余计算。然后执行质量感知模板匹配。根据匹配结果的软排序来确定目标在参考图像中的定位。因此,我们的方法可以实现具有地理信息的大规模卫星遥感图像中无人机视图中目标的定位任务。由于真实场景无人机数据稀疏,我们后续将扩大范围,针对更多区域和场景测试和优化无人机视图,进一步提高定位的稳定性和准确性















 3018
3018











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









