








在这个例子中,我们展示了研究论文NeRF的最小实现:将场景表示为Ben Mildenhall等人的视图合成的神经辐射场。作者提出了一种巧妙的方法,通过神经网络对体积场景函数进行建模,从而合成场景的新视图。
为了帮助您直观地理解这一点,让我们从以下问题开始:是否可以将图像中像素的位置提供给神经网络,并要求网络预测该位置的颜色?
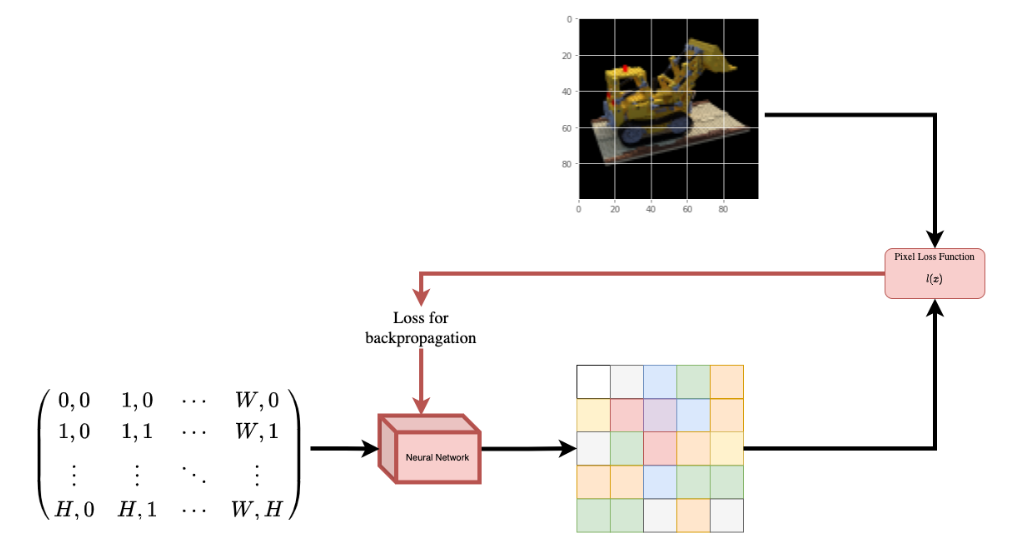
图 1:给定图像坐标的神经网络作为输入并要求预测坐标处的颜色。
神经网络会假设记忆(过拟合)图像。这意味着我们的神经网络会将整个图像编码为其权重。我们可以用每个位置查询神经网络,它最终会重建整个图像。
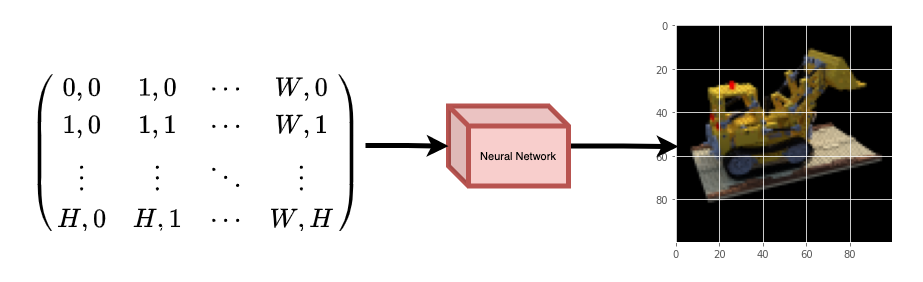
图 2:经过训练的神经网络从头开始重新创建图像。
现在出现了一个问题,我们如何扩展这个想法来学习3D体积场景?实现与上述类似的过程需要了解每个体素(体积像素)。事实证明,这是一项非常具有挑战性的任务。
该论文的作者提出了一种使用场景的一些图像来学习3D场景的最小而优雅的方法。他们放弃使用体素进行训练。网络学习对体积场景进行建模,从而生成模型在训练时未显示的3D场景的新视图(图像)。
需要了解一些先决条件才能充分理解这一过程。我们以这样一种方式构建示例,以便您在开始实施之前拥有所有必需的知识。
设置
import os
os.environ["GLOG_v"] = "3"
import cv2
import json
import time
import numpy as np
from tqdm import tqdm
from pathlib import Path
import matplotlib.pyplot as plt
import mindspore
import mindspore as md
import mindspore.ops.operations as P
from mindspore import nn, ops, Tensor
import mindspore as md
# environment config
mode = "GRAPH_MODE"
seed = 1
device_id = 0
device = "GPU"
init = False
# data config
half_res = True
testskip = 8
white_bkgd = True
render_test = True
# network config
chunk = 32768
cap_n_samples = 64
cap_n_importance = 0
netchunk = 65536
lrate = 0.0005
# runner config
cap_n_iters = 3000
cap_n_rand = 1024
i_testset = 100
lrate_decay = 250
def context_setup(idx, device='GPU', mode=md.context.GRAPH_MODE):
if init:
return
if device == "CPU":
raise NotImplementedError("`cumprod` ops does not support CPU")
md.context.set_context(mode=mode, device_target=device, device_id=idx)
md.set_seed(seed)
context_setup(device_id, device, getattr(md.context, mode))预备知识
数据文件包含图像、相机姿势和焦距。这些图像是从多个摄像机角度拍摄的,如图3所示。

图 3:多个摄像机角度。
要在这种情况下理解相机姿势,我们必须首先让自己认为相机是现实世界和二维图像之间的映射。
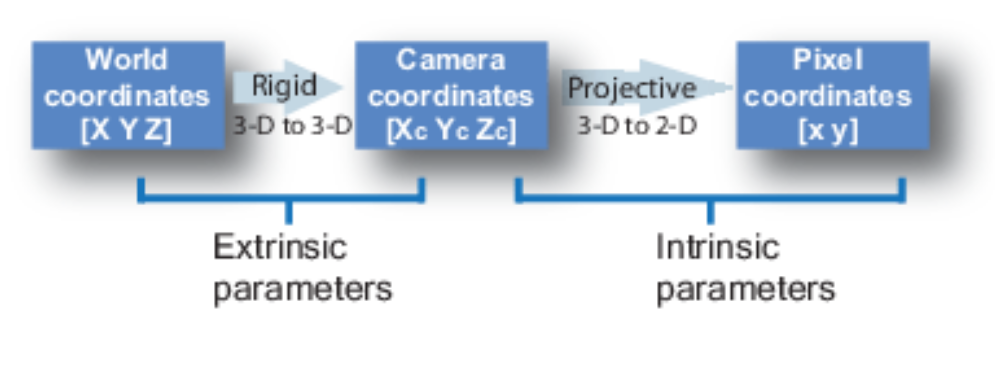
图 4:通过相机将 3-D 世界映射到 2-D 图像。
考虑以下等式:
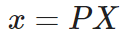
其中x是2-D图像点,X是3-D世界点,P是相机矩阵。P是 一个3 x 4矩阵,在将现实世界对象映射到图像平面上起着至关重要的作用。
相机矩阵是一个仿射变换矩阵,它与一个3 x 1列连接[image height, image width, focal length]以产生姿势矩阵。该矩阵的尺寸为3 x 5,其中第一个3 x 3块位于相机的视点中。轴是[down, right, backwards]或[-y, x, z]相机面向前方的位置-z。
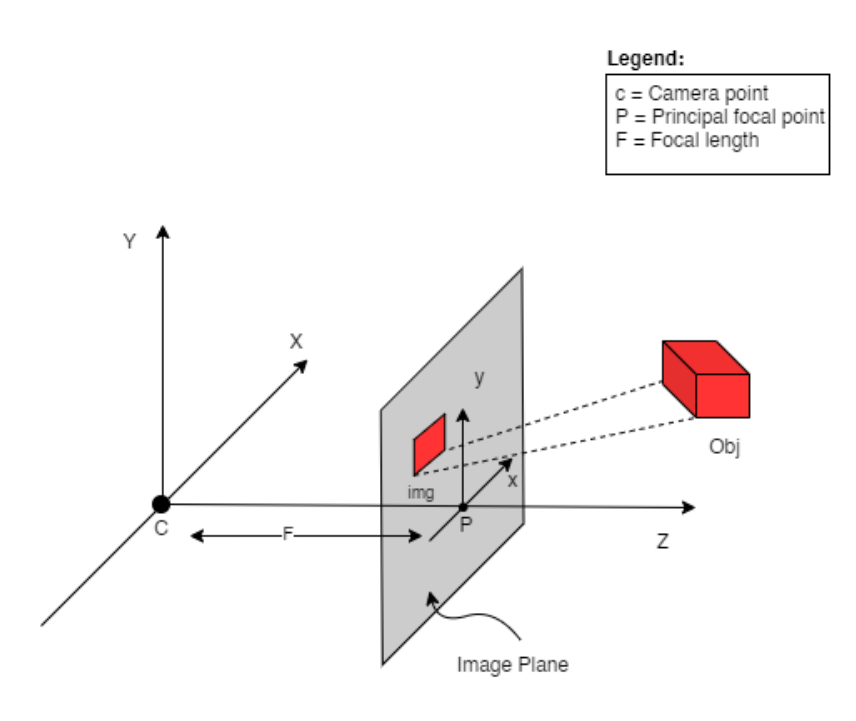
图 5:仿射变换。
COLMAP帧是[right, down, forwards]或[x, -y, -z]。在此处阅读有关COLMAP的更多信息。
下载数据
首先自行下载数据: NeRF Synthetics.
下载数据后, 按照以下结构安排数据:
.datasets/ └── nerf_synthetics └── lego ├── test [600 entries exceeds filelimit, not opening dir] ├── train [100 entries exceeds filelimit, not opening dir] ├── transforms_test.json ├── transforms_train.json ├── transforms_val.json └── val [100 entries exceeds filelimit, not opening dir]
数据加载
datadir = Path("datasets/nerf_synthetics/lego")
train_imgs = list((datadir / "train").glob("*.png"))
num_images = len(train_imgs)
temp_fname = str(train_imgs[np.random.randint(low=0, high=num_images)])
tmp_img = cv2.imread(temp_fname, cv2.IMREAD_UNCHANGED)
tmp_img = cv2.cvtColor(tmp_img, cv2.COLOR_BGRA2RGBA)
plt.imshow(tmp_img)
plt.show()数据管线
现在您已经了解了相机矩阵的概念以及从3D场景到2D图像的映射,让我们来谈谈逆映射,即从2D图像到3D场景。
我们需要讨论使用光线投射和追踪的体积渲染,这是常见的计算机图形技术。本节将帮助您快速掌握这些技术。
考虑一个带有N像素的图像。我们通过每个像素射出一条射线,并在射线上采样一些点。射线通常由方程参数化,r(t) =o+td其中t是参数,o是原点并且d是单位方向矢量。
我们考虑一条射线,并在射线上采样一些随机点。这些采样点每个都有一个独特的位置(x, y, z),并且光线有一个视角(theta, phi)。视角特别有趣,因为我们可以通过许多不同的方式通过单个像素拍摄光线,每种方式都有独特的视角。这里要注意的另一件有趣的事情是添加到采样过程中的噪声。我们为每个样本添加均匀的噪声,使样本对应于连续分布。这些采样点作为NeRF模型的输入。然后要求模型预测该点的RGB颜色和体积密度。
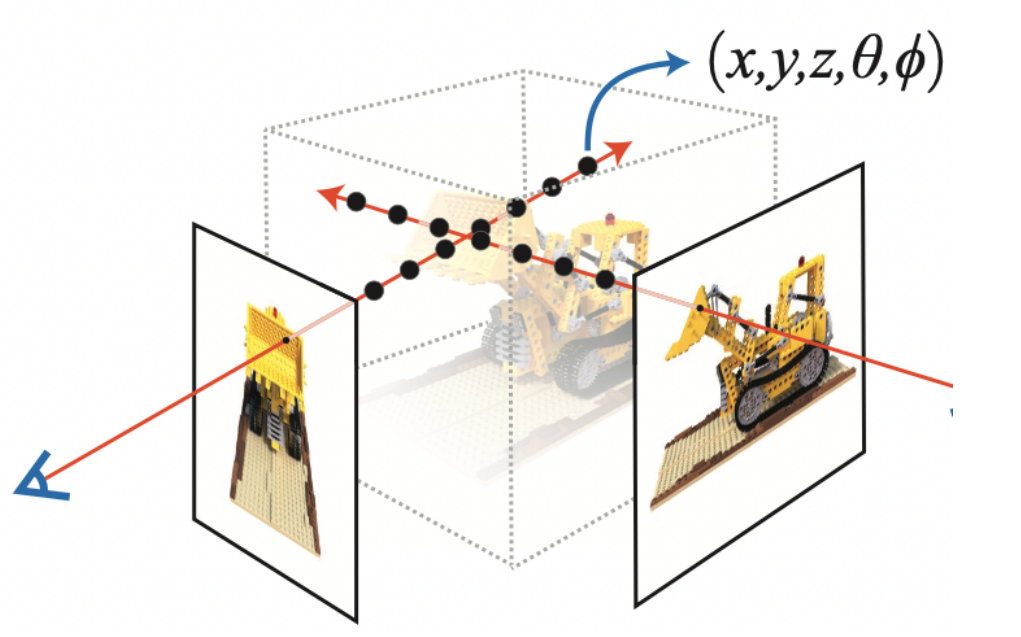
图 6:数据管线
def trans_t(t):
return np.array([[1, 0, 0, 0], [0, 1, 0, 0], [0, 0, 1, t], [0, 0, 0, 1]],
dtype=np.float32)
def rot_phi(phi):
return np.array([[1, 0, 0, 0], [0, np.cos(phi), -np.sin(phi), 0],
[0, np.sin(phi), np.cos(phi), 0], [0, 0, 0, 1]],
dtype=np.float32)
def rot_theta(th):
return np.array([[np.cos(th), 0, -np.sin(th), 0], [0, 1, 0, 0],
[np.sin(th), 0, np.cos(th), 0], [0, 0, 0, 1]],
dtype=np.float32)
def pose_spherical(theta, phi, radius):
"""pose_spherical"""
c2w = trans_t(radius)
c2w = np.matmul(rot_phi(phi / 180. * np.pi), c2w)
c2w = np.matmul(rot_theta(theta / 180. * np.pi), c2w)
c2w = np.matmul(
np.array([[-1, 0, 0, 0], [0, 0, 1, 0], [0, 1, 0, 0], [0, 0, 0, 1]],
dtype=np.float32), c2w)
return c2w
def load_blender_data(basedir, half_res=False, testskip=1):
"""load_blender_data"""
splits = ['train', 'val', 'test']
metas = {}
for s in splits:
with open(os.path.join(basedir, f'transforms_{s}.json'),
'r',
encoding='utf-8') as fp:
metas[s] = json.load(fp)
all_imgs = []
all_poses = []
counts = [0]
for s in splits:
meta = metas[s]
imgs = []
poses = []
if s == 'train' or testskip == 0:
skip = 1
else:
skip = testskip
for frame in meta['frames'][::skip]:
fname = os.path.join(basedir, frame['file_path'] + '.png')
tmp_img = cv2.imread(fname, cv2.IMREAD_UNCHANGED)
tmp_img = cv2.cvtColor(tmp_img, cv2.COLOR_BGRA2RGBA)
imgs.append(tmp_img)
poses.append(np.array(frame['transform_matrix']))
imgs = (np.array(imgs) / 255.).astype(
np.float32) # keep all 4 channels (RGBA)
poses = np.array(poses).astype(np.float32)
counts.append(counts[-1] + imgs.shape[0])
all_imgs.append(imgs)
all_poses.append(poses)
i_split = [np.arange(counts[i], counts[i + 1]) for i in range(3)]
imgs = np.concatenate(all_imgs, 0)
poses = np.concatenate(all_poses, 0)
cap_h, cap_w = imgs[0].shape[:2]
camera_angle_x = float(meta['camera_angle_x'])
focal = .5 * cap_w / np.tan(.5 * camera_angle_x)
render_poses = np.stack([
pose_spherical(angle, -30.0, 4.0)
for angle in np.linspace(-180, 180, 40 + 1)[:-1]
], axis=0)
if half_res:
cap_h = cap_h // 8
cap_w = cap_w // 8
focal = focal / 8.
imgs_half_res = np.zeros((imgs.shape[0], cap_h, cap_w, 4))
for i, img in enumerate(imgs):
imgs_half_res[i] = cv2.resize(img, (cap_h, cap_w),
interpolation=cv2.INTER_AREA)
imgs = imgs_half_res
return md.Tensor(imgs).astype("float32"), md.Tensor(poses).astype(
"float32"), md.Tensor(render_poses).astype("float32"), [
cap_h, cap_w, focal
], i_split
images, poses, render_poses, hwf, i_split = load_blender_data(datadir, half_res, testskip)
print('Loaded blender', images.shape, render_poses.shape, hwf, datadir)
i_train, i_val, i_test = i_split
near = 2.
far = 6.
if white_bkgd:
images = images[..., :3] * images[..., -1:] + (1. - images[..., -1:])
else:
images = images[..., :3]
if render_test:
render_poses = poses[i_test.tolist()]
# Cast intrinsics to right types
cap_h, cap_w, focal = hwf
cap_h, cap_w = int(cap_h), int(cap_w)
hwf = [cap_h, cap_w, focal]NeRF 模型
该模型是一个多层感知器 (MLP),以ReLU作为其非线性。
论文摘录:
“我们通过限制网络将体积密度sigma预测为仅位置的函数来鼓励表示是多视图一致的x,同时允许将RGB颜色c预测为位置和查看方向的函数。为此,MLP首先使用8个全连接层(使用ReLU激活和每层256个通道)处理输入3D坐标,并输出sigma和256维特征向量。然后将该特征向量与相机光线的观察方向连接并传递到一个额外的全连接层(使用ReLU激活和128个通道),输出与视图相关的RGB颜色。”
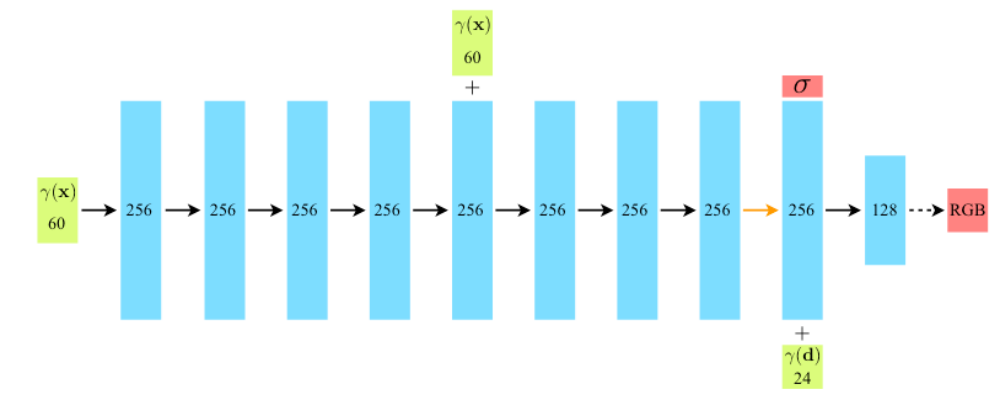
图 7:NeRF 模型
class NeRFMLP(nn.Cell):
"""
NeRF MLP architecture.
Args:
cap_d (int, optional): Model depth. Default: 8.
cap_w (int, optional): Model width. Default: 256.
input_ch (int, optional): Input channel. Default: 3.
input_ch_views (int, optional): Input view channel. Default: 3.
output_ch (int, optional): Output channel. Default: 4.
skips (tuple, optional): Skip connection layer index. Default: (4).
use_view_dirs (bool, optional): Use view directions or not. Default: False.
Inputs:
- **x** (Tensor) - Query tensors. points and view directions (..., 6).
Outputs:
Tensor, query features (..., feature_dims).
Supported Platforms:
``Ascend`` ``GPU`` ``CPU``
Examples:
>>> model = NeRFMLP()
>>> inputs = ms.numpy.randn(1, 3)
>>> outputs = model(inputs)
[[0.2384 0.8456 0.6845 0.1584]]
"""
def __init__(
self,
cap_d=8,
cap_w=256,
input_ch=3,
input_ch_views=3,
output_ch=4,
skips=(4),
use_view_dirs=False,
):
super().__init__()
self.cap_d = cap_d
self.cap_w = cap_w
self.input_ch = input_ch
self.input_ch_views = input_ch_views
self.skips = skips
self.use_view_dirs = use_view_dirs
self.pts_linears = nn.CellList([nn.Dense(in_channels=input_ch, out_channels=cap_w)] + [
nn.Dense(in_channels=cap_w, out_channels=cap_w) if i not in
self.skips else nn.Dense(in_channels=cap_w + input_ch, out_channels=cap_w) for i in range(cap_d - 1)
])
self.views_linears = nn.CellList([nn.Dense(in_channels=input_ch_views + cap_w, out_channels=cap_w // 2)])
if use_view_dirs:
self.feature_linear = nn.Dense(in_channels=cap_w, out_channels=cap_w)
self.alpha_linear = nn.Dense(in_channels=cap_w, out_channels=1)
self.rgb_linear = nn.Dense(in_channels=cap_w // 2, out_channels=3)
else:
self.output_linear = nn.Dense(in_channels=cap_w, out_channels=output_ch)
def construct(self, x):
"""NeRF MLP construct"""
input_pts, input_views = x[..., :self.input_ch], x[..., self.input_ch:]
h = input_pts
for i, _ in enumerate(self.pts_linears):
h = self.pts_linears[i](h)
h = P.ReLU()(h)
if i in self.skips:
h = P.Concat(-1)([input_pts, h])
if self.use_view_dirs:
alpha = self.alpha_linear(h)
feature = self.feature_linear(h)
h = P.Concat(-1)([feature, input_views])
for i, _ in enumerate(self.views_linears):
h = self.views_linears[i](h)
h = P.ReLU()(h)
rgb = self.rgb_linear(h)
outputs = P.Concat(-1)([rgb, alpha])
else:
outputs = self.output_linear(h)
return outputs可微分渲染器
class VolumeRenderer(nn.Cell):
"""
Volume Renderer architecture.
Args:
chunk (int): Number of rays processed in parallel, decrease if running out of memory.
cap_n_samples (int): Number of coarse samples per ray for coarse net.
cap_n_importance (int): Number of additional fine samples per ray for fine net.
net_chunk (int): Number of pts sent through network in parallel, decrease if running out of memory.
white_bkgd (bool): Set to render synthetic data on a white background (always use for DeepVoxels).
model_coarse (nn.Cell): Coarse net.
model_fine (nn.Cell, optional): Fine net, or None.
embedder_p (Dict): Config for positional encoding for point.
embedder_d (Dict): Config for positional encoding for view direction.
near (float, optional): The near plane. Default: 0.0.
far (float, optional): The far plane. Default: 1e6.
Inputs:
- **rays** (Tensor) - The ray tensor. (..., num_pts_per_ray, ray_batch_dims).
Outputs:
Tuple of 2 Tensor, the output tensors.
- **fine_net_output** (Tensor, optional) - The fine net output features.
- **coarse_net_output** (Tensor) - The coarse net output features.
Supported Platforms:
``Ascend`` ``GPU`` ``CPU``
Examples:
>>> model = VolumeRenderer(1000, 6, 12, 1000, False, P.Identity(), P.Identity(), P.Identity(), P.Identity())
>>> inputs = ms.numpy.randn(1, 1, 3)
>>> outputs = model(inputs)
([[0.2384 0.8456 0.1273]], [[0.8653 0.1866 0.6382]])
"""
def __init__(self,
chunk,
cap_n_samples,
cap_n_importance,
net_chunk,
white_bkgd,
model_coarse,
model_fine,
embedder_p,
embedder_d,
near=0.0,
far=1e6):
super().__init__()
self.chunk = chunk
self.cap_n_samples = cap_n_samples
self.cap_n_importance = cap_n_importance
self.net_chunk = net_chunk
self.white_bkgd = white_bkgd
self.model_coarse = model_coarse
self.model_fine = model_fine
# embedder for positions
self.embedder_p = Embedder(**embedder_p)
# embedder for view-in directions
self.embedder_d = Embedder(**embedder_d)
self.near = near
self.far = far
def construct(self, rays):
"""Volume renderer construct."""
return self.inference(rays)
def inference(self, rays):
"""Volume renderer inference."""
# make the number of rays be multiple of the chunk size
cap_n_rays = (rays.shape[1] // self.chunk + 1) * self.chunk
cap_n = self.cap_n_samples
res_ls = {"rgb_map_coarse": [], "rgb_map_fine": []}
for i in range(0, cap_n_rays, self.chunk):
ray_origins, ray_dirs = rays[:, i:i + self.chunk, :]
reshape_op = mindspore.ops.Reshape()
view_dirs = reshape_op(
ray_dirs / mindspore.numpy.norm(ray_dirs, axis=-1, keepdims=True),
(-1, 3),
)
near, far = self.near * mindspore.numpy.ones_like(ray_dirs[..., :1]), self.far * mindspore.numpy.ones_like(
ray_dirs[..., :1])
cap_m = ray_origins.shape[0]
if cap_m == 0:
continue
# stratified sampling along rays
s_samples = sample_along_rays(near, far, cap_n)
# position samples along rays
unsqueeze_op = P.ExpandDims()
pos_samples = unsqueeze_op(ray_origins,
1) + unsqueeze_op(ray_dirs, 1) * unsqueeze_op(s_samples, 2)
# expand ray directions to the same shape of samples
expand_op = P.BroadcastTo(pos_samples.shape)
dir_samples = expand_op(unsqueeze_op(view_dirs, 1))
reshape_op = P.Reshape()
pos_samples = reshape_op(pos_samples, (-1, 3))
dir_samples = reshape_op(dir_samples, (-1, 3))
# retrieve optic data from the network
optic_d = self._run_network_model_coarse(pos_samples, dir_samples)
optic_d = mindspore.numpy.reshape(optic_d, [cap_m, cap_n, 4])
# composite optic data to generate a RGB image
rgb_map_coarse, weights_coarse = self._composite(optic_d, s_samples, ray_dirs)
if self.cap_n_importance > 0:
z_vals_mid = 0.5 * (s_samples[..., 1:] + s_samples[..., :-1])
z_samples = sample_pdf(z_vals_mid, weights_coarse[..., 1:-1], self.cap_n_importance)
z_samples = mindspore.ops.stop_gradient(z_samples)
sort_op = P.Sort(axis=-1)
z_vals, _ = sort_op(P.Concat(-1)([s_samples, z_samples]))
pts = (ray_origins[..., None, :] + ray_dirs[..., None, :] * z_vals[..., :, None]
)
expand_op_2 = P.BroadcastTo(pts.shape)
dir_samples = expand_op_2(unsqueeze_op(view_dirs, 1))
pts = reshape_op(pts, (-1, 3))
dir_samples = reshape_op(dir_samples, (-1, 3))
optic_d = self._run_network_model_fine(pts, dir_samples)
optic_d = reshape_op(optic_d, (cap_m, cap_n + self.cap_n_importance, 4))
rgb_map_fine, _ = self._composite(optic_d, z_vals, ray_dirs)
else:
rgb_map_fine = rgb_map_coarse
res_ls["rgb_map_coarse"].append(rgb_map_coarse)
res_ls["rgb_map_fine"].append(rgb_map_fine)
res = {}
for k, v in res_ls.items():
res[k] = P.Concat(0)(v)
return res["rgb_map_fine"], res["rgb_map_coarse"]
def _run_network_model_fine(self, pts, view_dirs):
"""Run fine model."""
inputs_flat = pts
embedded = self.embedder_p(inputs_flat)
if view_dirs is not None:
input_dirs_flat = view_dirs
embedded_dirs = self.embedder_d(input_dirs_flat)
embedded = P.Concat(-1)([embedded, embedded_dirs])
chunk = self.net_chunk
outputs_flat_ls = []
for i in range(0, embedded.shape[0], chunk):
outputs_flat_ls.append(self.model_fine(embedded[i:i + chunk]))
outputs_flat = P.Concat(0)(outputs_flat_ls)
return outputs_flat
def _run_network_model_coarse(self, pts, view_dirs):
"""Run coarse model."""
inputs_flat = pts
embedded = self.embedder_p(inputs_flat)
if view_dirs is not None:
input_dirs_flat = view_dirs
embedded_dirs = self.embedder_d(input_dirs_flat)
embedded = P.Concat(-1)([embedded, embedded_dirs])
chunk = self.net_chunk
outputs_flat_ls = []
for i in range(0, embedded.shape[0], chunk):
outputs_flat_ls.append(self.model_coarse(embedded[i:i + chunk]))
outputs_flat = P.Concat(0)(outputs_flat_ls)
return outputs_flat
def _transfer(self, optic_d, dists):
"""Transfer occupancy to alpha values."""
sigmoid = P.Sigmoid()
rgbs = sigmoid(optic_d[..., :3])
alphas = 1.0 - P.Exp()(-1.0 * (P.ReLU()(optic_d[(..., 3)])) * dists)
return rgbs, alphas
def _composite(self, optic_d, s_samples, rays_d):
"""Composite the colors and densities."""
# distances between each samples
dists = s_samples[..., 1:] - s_samples[..., :-1]
dists_list = (
dists,
(mindspore.numpy.ones([]) * 1e10).expand_as(dists[..., :1]),
)
dists = P.Concat(-1)(dists_list)
dists = dists * mindspore.numpy.norm(rays_d[..., None, :], axis=-1)
# retrieve display colors and alphas for each samples by a transfer function
rgbs, alphas = self._transfer(optic_d, dists)
weights = alphas * mindspore.numpy.cumprod(
P.Concat(-1)([mindspore.numpy.ones((alphas.shape[0], 1)), 1.0 - alphas + 1e-10])[:, :-1],
axis=-1,
)
sum_op = mindspore.ops.ReduceSum()
rgb_map = sum_op(weights[..., None] * rgbs, -2)
acc_map = sum_op(weights, -1)
if self.white_bkgd:
rgb_map = rgb_map + (1.0 - acc_map[..., None])
return rgb_map, weights
class Embedder(nn.Cell):
"""
Embedder for positional embedding.
Args:
input_dims (int): Input dimensions.
max_freq_pow (float): Maximum frequency pow.
num_freqs (int): Number of frequencies.
periodic_fns (list, optional): Periodic fns. Default: [mindspore.ops.Sin(), mindspore.ops.Cos()].
log_sampling (bool, optional): Log sampling. Default: True.
include_input (bool, optional): Include input or not. Default: True.
Inputs:
inputs (Tensor) - Input tensor.
Outputs:
Tensor, input concatenated with positional embeddings.
Supported Platforms:
``Ascend`` ``GPU`` ``CPU``
Examples:
>>> model = Embedder(1, 1)
>>> inputs = ms.numpy.randn(1)
>>> outputs = model(inputs)
[0.1384 0.4426]
"""
def __init__(
self,
input_dims,
max_freq_pow,
num_freqs,
periodic_fns=(mindspore.ops.Sin(), mindspore.ops.Cos()),
log_sampling=True,
include_input=True,
):
super().__init__()
embed_fns = []
out_dims = 0
if include_input:
embed_fns.append(mindspore.ops.Identity())
out_dims += input_dims
if log_sampling:
freq_bands = mindspore.Tensor(2.0)**mindspore.numpy.linspace(0.0, max_freq_pow, num=num_freqs)
else:
freq_bands = mindspore.numpy.linspace(2.0**0.0, 2.0**max_freq_pow, num=num_freqs)
for _ in freq_bands:
for p_fn in periodic_fns:
embed_fns.append(p_fn)
out_dims += input_dims
self.embed_fns = embed_fns
self.out_dims = out_dims
self.freq_bands = freq_bands
def construct(self, inputs):
"""Embedder construct."""
out = []
for i, fn in enumerate(self.embed_fns):
if i == 0:
out.append(fn(inputs))
else:
out.append(fn(inputs * self.freq_bands[(i - 1) // 2]))
return P.Concat(-1)(out)定义模型
def get_embedder(multi_res, i=0):
"""
Get embedder function.
Args:
multi_res (int): Log2 of max freq for positional encoding.
i (int, optional): Set 0 for default positional encoding, -1 for none. Default: 0.
Returns:
Tuple of nn.Cell and int, embedder and the output dimensions.
- **embedder** (nn.Cell) - The embedder.
- **out_dims** (int) - The output dimensions.
"""
if i == -1:
return md.ops.Identity(), 3
embed_kwargs = {
"include_input": True,
"input_dims": 3,
"max_freq_pow": multi_res - 1,
"num_freqs": multi_res,
"log_sampling": True,
"periodic_fns": [md.ops.Sin(), md.ops.Cos()],
}
embedder_obj = Embedder(**embed_kwargs)
embed = embed_kwargs
return embed, embedder_obj.out_dims
def create_nerf(multires=10,
i_embed=0,
multires_views=4,
netdepth=8,
netwidth=256,
netdepth_fine=8,
netwidth_fine=256,
use_view_dirs=True,
cap_n_importance=0,
ckpt_path=None):
"""create nerf model and load weights"""
embed_fn, input_ch = get_embedder(multires, i_embed)
input_ch_views = 0
embeddirs_fn = None
if use_view_dirs:
embeddirs_fn, input_ch_views = get_embedder(multires_views,
i_embed)
# Create networks
output_ch = 4
skips = [4]
model_coarse = NeRFMLP(cap_d=netdepth,
cap_w=netwidth,
input_ch=input_ch,
output_ch=output_ch,
skips=skips,
input_ch_views=input_ch_views,
use_view_dirs=use_view_dirs)
grad_vars = [{"params": model_coarse.trainable_params()}]
model_fine = None
if cap_n_importance > 0:
model_fine = NeRFMLP(cap_d=netdepth_fine,
cap_w=netwidth_fine,
input_ch=input_ch,
output_ch=output_ch,
skips=skips,
input_ch_views=input_ch_views,
use_view_dirs=use_view_dirs)
grad_vars += [{"params": model_fine.trainable_params()}]
optimizer = None
start_iter = 0
# Load checkpoints
if ckpt_path is not None:
print("Reloading from", ckpt_path)
ckpt = md.load_checkpoint(ckpt_path)
# Load training steps
start_iter = int(ckpt["global_steps"]) + 1
# Load network weights
md.load_param_into_net(
model_coarse,
{key: value for key, value in ckpt.items() if ".model_coarse." in key},
)
if model_fine is not None:
md.load_param_into_net(
model_fine,
{key: value for key, value in ckpt.items() if ".model_fine." in key},
)
else:
print("No ckpt reloaded")
return start_iter, optimizer, model_coarse, model_fine, embed_fn, embeddirs_fn
class RendererWithCriterion(nn.Cell):
"""
Renderer with criterion.
Args:
renderer (nn.Cell): Renderer.
loss_fn (nn.Cell, optional): Loss function. Default: nn.MSELoss().
Inputs:
- **rays** (Tensor) - Rays tensor.
- **gt** (Tensor) - Ground truth tensor.
Outputs:
Tensor, loss for one forward pass.
"""
def __init__(self, renderer, loss_fn=nn.MSELoss()):
"""Renderer with criterion."""
super().__init__()
self.renderer = renderer
self.loss_fn = loss_fn
def construct(self, rays, gt):
"""Renderer Trainer construct."""
rgb_map_fine, rgb_map_coarse = self.renderer(rays)
return self.loss_fn(rgb_map_fine, gt) + self.loss_fn(rgb_map_coarse, gt)
# Create nerf model
start_iter, optimizer, model_coarse, model_fine, embed_fn, embeddirs_fn = create_nerf()
# Training steps
global_steps = start_iter
# Create volume renderer
renderer = VolumeRenderer(chunk, cap_n_samples,
cap_n_importance, netchunk,
white_bkgd, model_coarse, model_fine,
embed_fn, embeddirs_fn, near, far)
renderer.model_coarse.to_float(md.dtype.float16)
if renderer.model_fine is not None:
renderer.model_fine.to_float(md.dtype.float16)
renderer_with_criteron = RendererWithCriterion(renderer)
optimizer = nn.Adam(params=renderer.trainable_params(),
learning_rate=lrate,
beta1=0.9,
beta2=0.999)
grad_scale = ops.MultitypeFuncGraph("grad_scale")
@grad_scale.register("Tensor", "Tensor")
def gradient_scale(scale, grad):
return grad * ops.cast(scale, ops.dtype(grad))
class CustomTrainOneStepCell(nn.TrainOneStepCell):
def __init__(self, network, optimizer, sens=1.0):
super(CustomTrainOneStepCell, self).__init__(network, optimizer, sens)
self.hyper_map = ops.HyperMap()
self.reciprocal_sense = Tensor(1 / sens, mindspore.float32)
def scale_grad(self, gradients):
gradients = self.hyper_map(ops.partial(grad_scale, self.reciprocal_sense), gradients)
return gradients
def construct(self, *inputs):
loss = self.network(*inputs)
sens = ops.fill(loss.dtype, loss.shape, self.sens)
# calculate gradients, the sens will equal to the loss_scale
grads = self.grad(self.network, self.weights)(*inputs, sens)
# gradients / loss_scale
grads = self.scale_grad(grads)
# reduce gradients in distributed scenarios
grads = self.grad_reducer(grads)
loss = ops.depend(loss, self.optimizer(grads))
return loss
loss_scale = 1024.0
train_renderer = CustomTrainOneStepCell(renderer_with_criteron, optimizer, loss_scale)
train_renderer.set_train()训练
def generate_rays(h, w, f, pose):
'''
Given an image plane, generate rays from the camera origin to each pixel on the image plane.
Arguments:
h: height of the image plane.
w: width of the image plane.
f: focal length of the image plane.
pose: the extrinsic parameters of the camera. (3, 4) or (4, 4)
Returns:
A tuple: origins of rays, directions of rays
'''
# Coordinates of the 2D grid
cols = md.ops.ExpandDims()(
md.numpy.linspace(-1.0 * w / 2, w - 1 - w / 2, w) / f,
0).repeat(h, axis=0) # (h, w)
rows = md.ops.ExpandDims()(
-1.0 * md.numpy.linspace(-1.0 * h / 2, h - 1 - h / 2, h) / f,
1).repeat(w, axis=1) # (h, w)
# Ray directions for all pixels
ray_dirs = md.numpy.stack([cols, rows, -1.0 * md.numpy.ones_like(cols)],
axis=-1) # (h, w, 3)
# Apply rotation transformation to make each ray orient according to the camera
unsqueeze_op = md.ops.ExpandDims()
ray_dirs = md.numpy.sum(unsqueeze_op(ray_dirs, 2) * pose[:3, :3], axis=-1)
# Origin position
rays_oris = pose[:3, -1].expand_as(ray_dirs) # (h, w, 3)
return rays_oris, ray_dirs.astype(pose.dtype) # (h, w, 3), (h, w, 3)
def train_net(iter_, train_renderer, optimizer, rays, gt):
'''
Train a network.
Arguments:
config: configuration.
iter_: current iterations.
renderer: a volume renderer.
optimizer: a network optimizer.
rays: a batch of rays for training. (#rays * #samples, 6)
gt: the groundtruth.
Returns:
A tuple: (MSE loss, PSNR).
'''
loss = train_renderer(rays, gt)
# Update learning rate
decay_rate = 0.1
decay_steps = lrate_decay * 1000
new_lrate = lrate * (decay_rate**(iter_ / decay_steps))
optimizer.learning_rate = md.Parameter(new_lrate)
return float(loss), float(psnr_from_mse(loss))
def test_net(img_h,
img_w,
focal,
renderer,
test_poses,
gt=None,
on_progress=None,
on_complete=None):
'''
Test the network and generate results.
Arguments:
img_h: height of image plane.
img_w: width of image plane.
focal: focal length.
renderer: the volume renderer.
test_poses: poses used to test the network. (#poses, 4, 4)
on_progress: a callback function invoked per generation of a result.
on_complete: a callback function invoked after generating all results.
Returns:
A tuple: (Mean test time, MSE loss, PSNR).
'''
rgb_maps = []
loss_ls = []
psnr_ls = []
time_ls = []
reshape_op = md.ops.Reshape()
stack_op = md.ops.Stack(axis=0)
image_list = []
for j, test_pose in enumerate(test_poses):
t0 = time.time()
# Generate rays for all pixels
ray_oris, ray_dirs = generate_rays(img_h, img_w, focal, test_pose)
ray_oris = reshape_op(ray_oris, (-1, 3))
ray_dirs = reshape_op(ray_dirs, (-1, 3))
test_batch_rays = stack_op([ray_oris, ray_dirs])
# Retrieve testing results
rgb_map, _ = renderer.inference(test_batch_rays)
rgb_map = reshape_op(rgb_map, (img_h, img_w, 3))
rgb_maps.append(rgb_map.asnumpy())
# If given groundtruth, compute MSE and PSNR
if gt is not None:
loss = mse(rgb_map, gt[j])
psnr = psnr_from_mse(loss)
loss_ls.append(float(loss))
psnr_ls.append(float(psnr))
time_ls.append(time.time() - t0)
# Handle each testing result
if on_progress:
if isinstance(on_progress, list):
on_progress[0](j, rgb_maps[-1])
if gt is not None:
on_progress[1](j, gt[j].asnumpy())
else:
on_progress(j, rgb_maps[-1])
image_list.append(to8b(rgb_maps[-1]))
# Handle all testing results
if on_complete:
on_complete(np.stack(rgb_maps, 0))
if not loss_ls:
loss_ls = [0.0]
if not psnr_ls:
psnr_ls = [0.0]
if not time_ls:
time_ls = [0.0]
return np.mean(time_ls), np.mean(loss_ls), np.mean(psnr_ls), image_list
def to8b(x):
"""Convert normalized color to 8-bit color"""
return (255 * np.clip(x, 0.0, 1.0)).astype(np.uint8)
def mse(im1, im2):
'''
MSE between two images.
'''
return md.numpy.mean((im1 - im2)**2)
psnr_from_mse_base = md.Tensor([10.0])
def psnr_from_mse(v):
'''
Convert MSE to PSNR.
'''
return -10.0 * (md.numpy.log(v) / md.numpy.log(psnr_from_mse_base))
def sample_grid_2d(cap_h, cap_w, cap_n):
"""
Sample cells in an cap_h x cap_w mesh grid.
Args:
cap_h (int): Height of the mesh grid.
cap_w (int): Width of the mesh grid.
cap_n (int): The number of samples.
Returns:
Tuple of 2 Tensor, sampled rows and sampled columns.
- **select_coords_x** (Tensor) - Sampled rows.
- **select_coords_y** (Tensor) - Sampled columns.
"""
if cap_n > cap_w * cap_h:
cap_n = cap_w * cap_h
# Create a 2D mesh grid where each element is the coordinate of the cell
stack_op = md.ops.Stack(-1)
coords = stack_op(
md.numpy.meshgrid(
md.numpy.linspace(0, cap_h - 1, cap_h),
md.numpy.linspace(0, cap_w - 1, cap_w),
indexing="ij",
))
# Flat the mesh grid
coords = md.ops.Reshape()(coords, (-1, 2))
# Sample N cells in the mesh grid
select_indexes = np.random.choice(coords.shape[0],
size=[cap_n],
replace=False)
# Sample N cells among the mesh grid
select_coords = coords[select_indexes.tolist()].astype("int32")
return select_coords[:, 0], select_coords[:, 1]
def sample_along_rays(near,
far,
cap_cap_n_samples,
lin_disp=False,
perturb=True):
"""
Sample points along rays.
Args:
near (Tensor): A vector containing nearest point for each ray. (cap_n_rays).
far (Tensor): A vector containing furthest point for each ray. (cap_n_rays).
cap_n_samples (int): The number of sampled points for each ray.
lin_disp (bool): True for sample linearly in inverse depth rather than in depth (used for some datasets).
perturb (bool): True for stratified sampling. False for uniform sampling.
Returns:
Tensor, samples where j-th component of the i-th row is the j-th sampled position along the i-th ray.
"""
# The number of rays
cap_n_rays = near.shape[0]
# Uniform samples along rays
t_vals = md.numpy.linspace(0.0, 1.0, num=cap_cap_n_samples)
if not lin_disp:
z_vals = near * (1.0 - t_vals) + far * t_vals
else:
z_vals = 1.0 / (1.0 / near * (1.0 - t_vals) + 1.0 / far * t_vals)
expand_op = md.ops.BroadcastTo((cap_n_rays, cap_cap_n_samples))
z_vals = expand_op(z_vals)
if perturb:
# Get intervals between samples
mids = 0.5 * (z_vals[..., 1:] + z_vals[..., :-1])
cat_op = md.ops.Concat(-1)
upper = cat_op([mids, z_vals[..., -1:]])
lower = cat_op([z_vals[..., :1], mids])
# Stratified samples in those intervals
t_rand = md.numpy.rand(z_vals.shape)
z_vals = lower + (upper - lower) * t_rand
return z_vals
def sample_pdf(bins, weights, cap_cap_n_samples, det=False):
"""
Sample pdf function.
Args:
bins (int): The number of bins for pdf.
weights (Tensor): The estimated weights.
cap_cap_n_samples (int): The number of points to be sampled.
det (bool, optional): Deterministic run or not. Default: False.
Returns:
Tensor, sampled pdf tensor.
"""
weights = weights + 1e-5
pdf = weights / md.numpy.sum(weights, -1, keepdims=True)
cdf = md.numpy.cumsum(pdf, -1)
cdf = md.ops.Concat(-1)([md.numpy.zeros_like(cdf[..., :1]), cdf])
# Take uniform samples
temp_shape = cdf.shape[:-1]
cap_cap_n_samples_new = cap_cap_n_samples
temp_shape_new = list(temp_shape) + [cap_cap_n_samples_new]
if det:
u = md.numpy.linspace(0.0, 1.0, num=cap_cap_n_samples)
expand_op = md.ops.BroadcastTo(temp_shape_new)
u = expand_op(u)
else:
u = md.numpy.rand(temp_shape_new)
# Invert CDF
indexes = nd_searchsorted(cdf, u)
below = md.numpy.maximum(md.numpy.zeros_like(indexes - 1), indexes - 1)
above = md.numpy.minimum((cdf.shape[-1] - 1) * md.numpy.ones_like(indexes),
indexes)
indexes_g = md.ops.Stack(axis=-1)([below, above])
matched_shape = (indexes_g.shape[0], indexes_g.shape[1], cdf.shape[-1])
gather_op = md.ops.GatherD()
unsqueeze_op = md.ops.ExpandDims()
expand_op = md.ops.BroadcastTo(matched_shape)
cdf_g = gather_op(expand_op(unsqueeze_op(cdf, 1)), 2, indexes_g)
bins_g = gather_op(expand_op(unsqueeze_op(bins, 1)), 2, indexes_g)
denom = cdf_g[..., 1] - cdf_g[..., 0]
denom = md.numpy.where(denom < 1e-5, md.numpy.ones_like(denom), denom)
t = (u - cdf_g[..., 0]) / denom
samples = bins_g[..., 0] + t * (bins_g[..., 1] - bins_g[..., 0])
return samples
def nd_searchsorted(cdf, u):
"""N-dim searchsorted.
Args:
cdf (Tensor): The cdf sampling weights.
u (Tensor): The interval tensors.
Returns:
Tensor, index after searchsorted ops.
"""
spatial_shape = cdf.shape[:-1]
last_dim_cdf, last_dim_u = cdf.shape[-1], u.shape[-1]
cdf_, u_ = cdf.view(-1, last_dim_cdf), u.view(-1, last_dim_u)
indexes_ls = []
for i in range(cdf_.shape[0]):
indexes_ls.append(cdf_[i].searchsorted(u_[i], side="right"))
indexes = md.ops.Stack(axis=0)(indexes_ls)
indexes = indexes.view(*spatial_shape, last_dim_u)
return indexes
train_image_list = []
with tqdm(range(1, cap_n_iters + 1)) as pbar:
pbar.n = start_iter
for i in pbar:
# Show progress
pbar.set_description(f'Iter {global_steps + 1:d}')
pbar.update()
# Start time of the current iteration
time0 = time.time()
img_i = int(np.random.choice(i_train))
target = images[img_i]
pose = poses[img_i, :3, :4]
if cap_n_rand is not None:
rays_o, rays_d = generate_rays(
cap_h, cap_w, focal,
pose) # (cap_h, cap_w, 3), (cap_h, cap_w, 3)
sampled_rows, sampled_cols = sample_grid_2d(
cap_h, cap_w, cap_n_rand)
rays_o = rays_o[sampled_rows, sampled_cols] # (cap_n_rand, 3)
rays_d = rays_d[sampled_rows, sampled_cols] # (cap_n_rand, 3)
batch_rays = md.ops.Stack(axis=0)([rays_o, rays_d])
target_s = target[sampled_rows, sampled_cols] # (cap_n_rand, 3)
loss, psnr = train_net(global_steps, train_renderer, optimizer,
batch_rays, target_s)
pbar.set_postfix(time=time.time() - time0, loss=loss, psnr=psnr)
# Save testing results
if (global_steps + 1) % i_testset == 0:
test_idx = np.random.randint(low=0, high=len(i_test))
test_time, test_loss, test_psnr, sub_train_image_list = test_net(
cap_h, cap_w, focal, renderer,
poses[i_test[test_idx:test_idx + 1].tolist()],
images[i_test[test_idx:test_idx + 1].tolist()])
train_image_list.extend(sub_train_image_list)
global_steps += 1import matplotlib.pyplot as plt
import matplotlib.animation as animation
%matplotlib inline
def showGif(image_list, name):
show_list = []
fig = plt.figure(figsize=(4, 4), dpi=120)
for epoch in range(len(image_list)):
plt.axis("off")
show_list.append([plt.imshow(image_list[epoch])])
ani = animation.ArtistAnimation(fig, show_list, interval=1000, repeat_delay=1000, blit=True)
ani.save(f'images/{name}.gif', writer='pillow', fps=1)
showGif(train_image_list, "nerf.train")
渲染
test_time, test_loss, test_psnr, test_image_list = test_net(
cap_h,
cap_w,
focal,
renderer,
md.Tensor(poses[i_test.tolist()]),
images[i_test.tolist()])
print(
f"Testing results: [ Mean Time: {test_time:.4f}s, Loss: {test_loss:.4f}, PSNR: {test_psnr:.4f} ]"
)
showGif(test_image_list, "nerf.test")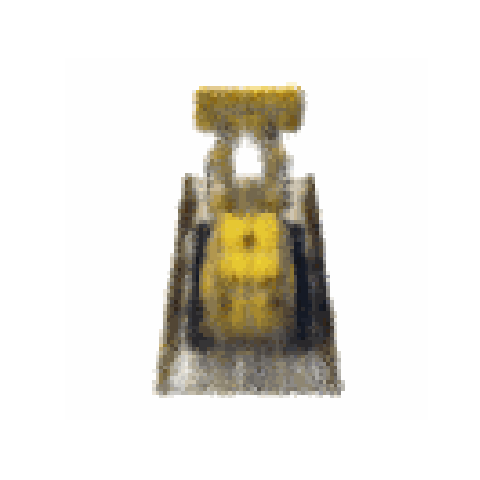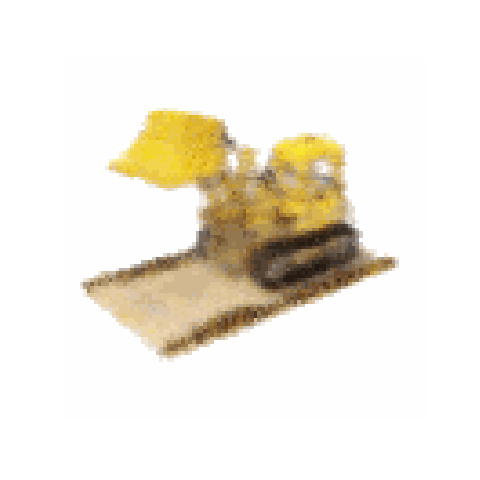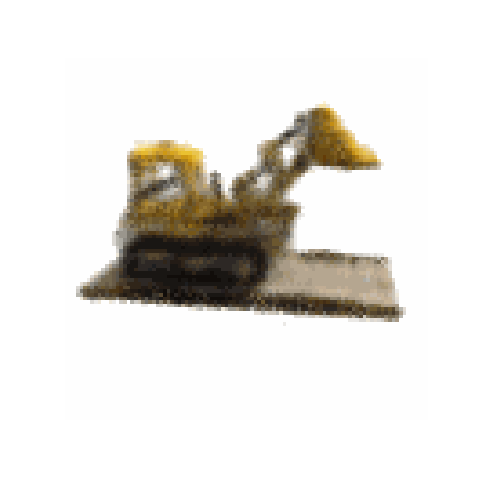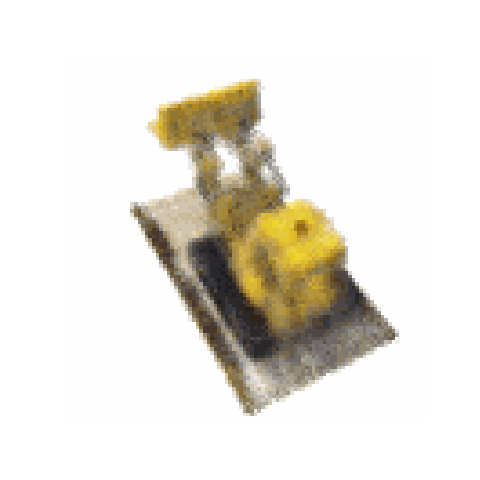
推理
使用预训练权重推理最佳结果。建议重启 jupyter kernel 后运行以下代码块,避免内存不足问题。
device = "GPU"
device_id = 0
mode = "GRAPH_MODE"
# 下载权重
!if [[ ! -f ckpts/200000.blender_lego_coarse_0.ckpt ]]; then mkdir -p ckpts/ && wget -P ckpts/ https://download.mindspore.cn/vision/nerf/lego/200000.blender_lego_coarse_0.ckpt; fi
# 运行推理脚本
!cd src && GLOG_v=3 python eval.py --name lego_coarse --data_dir ../datasets/nerf_synthetics/lego --dataset_type blender --half_res --cap_n_rand 4096 --cap_n_samples 192 --capimport glob
import imageio
import matplotlib.pyplot as plt
import matplotlib.animation as animation
%matplotlib inline
def showGif(image_list, name):
show_list = []
fig = plt.figure(figsize=(4, 4), dpi=120)
for epoch in range(len(image_list)):
plt.axis("off")
show_list.append([plt.imshow(image_list[epoch])])
ani = animation.ArtistAnimation(fig, show_list, interval=1000, repeat_delay=1000, blit=True)
ani.save(f'images/{name}.gif', writer='pillow', fps=1)
inference_image_list = [imageio.imread(image_path) for image_path in sorted(glob.glob("src/results/blender_lego_coarse_0/renderonly_200000/*.png"))]
showGif(inference_image_list, "nerf.inference")
总结
本案例对NeRF的论文中提出的模型进行了详细的解释,向读者完整地展现了该算法的流程。
引用
[1] Mildenhall, Ben et al. “NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis.” ECCV (2020).
参考资料
NeRF仓库:官方NeRF的存储库。
链接:https://github.com/bmild/nerf
NeRF 视频:关于 NeRF 的讲解视频。
链接:https://www.youtube.com/watch?v=dPWLybp4LL0
更多昇思MindSpore应用案例请访问官网开发者案例:https://www.mindspore.cn/resources/cases

MindSpore官方资料
官方QQ群 : 871543426
官网:https://www.mindspore.cn/
Gitee : https://gitee.com/mindspore/mindspore
GitHub : https://github.com/mindspore-ai/mindspore
论坛:https://www.hiascend.com/forum/forum-0106101385921175002-1.html
Openl启智社区:https://openi.org.cn

















 4508
4508

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









