










NeRF—神经辐射场
本文介绍了三维重建相关技术,特别是神经辐射场(NeRF)的进步,它通过深度学习实现逼真的三维场景重建。NeRF在计算机图形学、自动驾驶和元宇宙等领域展现出广阔的应用前景,通过改进传统方法,提供更高质量的渲染和沉浸式体验。
NeRF 是 2020年 ECCV 的 best paper NeRF解决新视图合成问题。
因为其使用了较为简单的神经网络结构,因此属于是可微渲染的一种。NeRF也称为神经辐射场,因为其使用了体渲染的技术来实现的。
NeRF的定义
广义的定义: NeRF是使用神经网络(MLP)来隐式的存储3D信息。
NeRF是隐式的存储3d信息的,也就可以从另外的一个方向说明了,之前的3d信息是通过显示的方式来进行存储的。
显式的3D信息:有明确x,y,z的值(mesh,voxel,点云…等)

隐式的3D信息:无明确的x/y/z的值,只能输出指定角度的2D图片。
实际上模型的结构比较简单,我们是在图片的前后处理上做了很多的工作,主要就包括了图像转为5维的前处理操作。以及一个4d转为2d图片的后处理操作。
这就是两个核心的过程信息。
我们从论文中就可以得到。
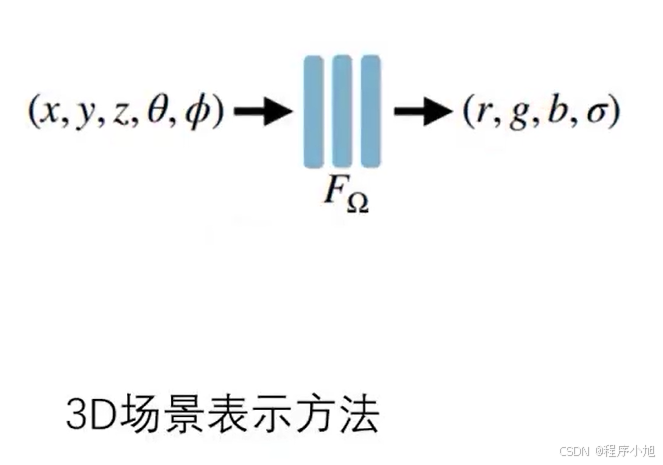
- 模型输入是5D向量(x, y, z, theta, phi) ;
- 模型输出是4D向量, (密度,颜色(
RGB)); - 模型是8层的MLP

输入为 5D coordinate:空间位置 ( x , y , z ) ,视觉方向 ( θ , ϕ ) 也可以说是粒子的空间位姿, (x, y, z, theta, phi)。视觉方向 ( θ , ϕ )可以说是光线所在的视角的方向。
NERF使用多层感知机,将光线上的点位编码成了颜色以及密度值。它将它所表达的场景存储在了MLP的权值中。它的输入是很多已知姿态的图像将其进行训练得到的场景表征。
推论:
- 模型不具有泛化能力;
- 一个模型只能存储一个3D信息
真实场景与相机模型
体渲染
渲染是指对光线进行追踪或者是积分累积从而生成图像的一种方法。(如何将采样点的颜色值和不透明度转换到图片当中呢?)
属于渲染技术的分支目的是解决云/烟/果冻等非刚性物体的渲染建模
将物质抽象成一团飘忽不定的粒子群光线在穿过时,是光子在跟粒子发生碰撞的过程。

光子与粒子发生作用的过程: 吸收:光子被粒子吸收 放射:粒子本身发光 外射光:光泽在冲击后,被弹射; 内射光:其他方向弹射来的例子
NERF的假设:
-
物体是一团自发光的粒子。
-
粒子有密度和颜色。
-
外射光和内射光抵消。
-
多个粒子被渲染成指定角度的图片。
模型的输入:将物体进行稀疏表示的单个粒子的位姿
模型的输出:该粒子的密度和颜色

粒子采集的原理
首先对于一个自发光的粒子的空间坐标为空间坐标 (x, y, z)。其发射出来的光线会通过相机模型。成为图片上的像素坐标(u,v)粒子颜色即是像素颜色。
这个粒子的颜色即为像素的颜色。
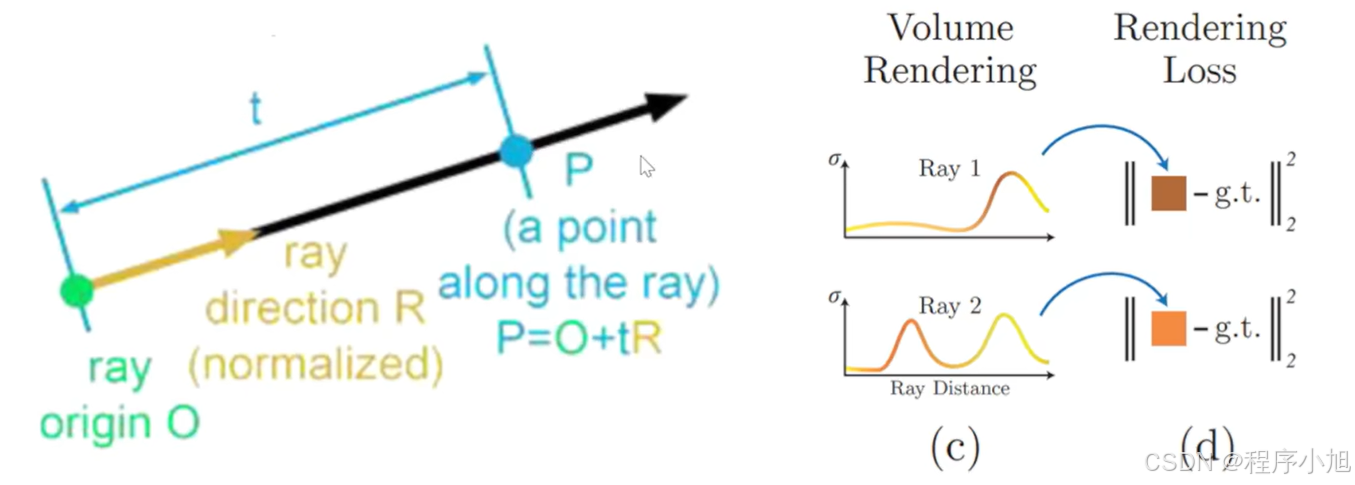
通过将一条光线上的许多(无数)的点的这些视为向量,进行一个合成的操作,最终就可以的得到该条光线在输出图像上的像素值。将该参数值与真实的图像的参数值进行计算,就会得到我们的LOSS
我们的神经辐射场是将2d的输入表征为一个3d场景的过程。而我们的体渲染Rendering Volume是将3d场景下的许多点位给投射出一个二维图像的过程。
-
输入图像进入网络的部分可以看作是2d转变为3d的一个过程。
-
最后得到的网络的输出在通过
体渲染技术对点位来进行合成。最终输出到图像上。可以认为是一个3d到2d的过程
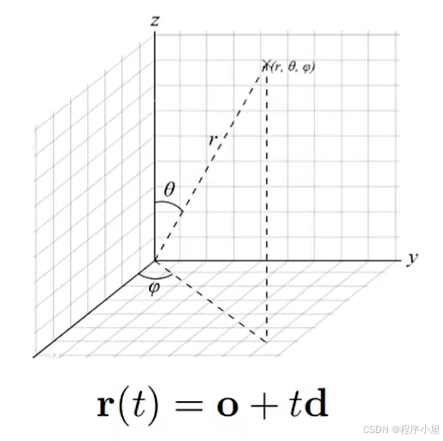
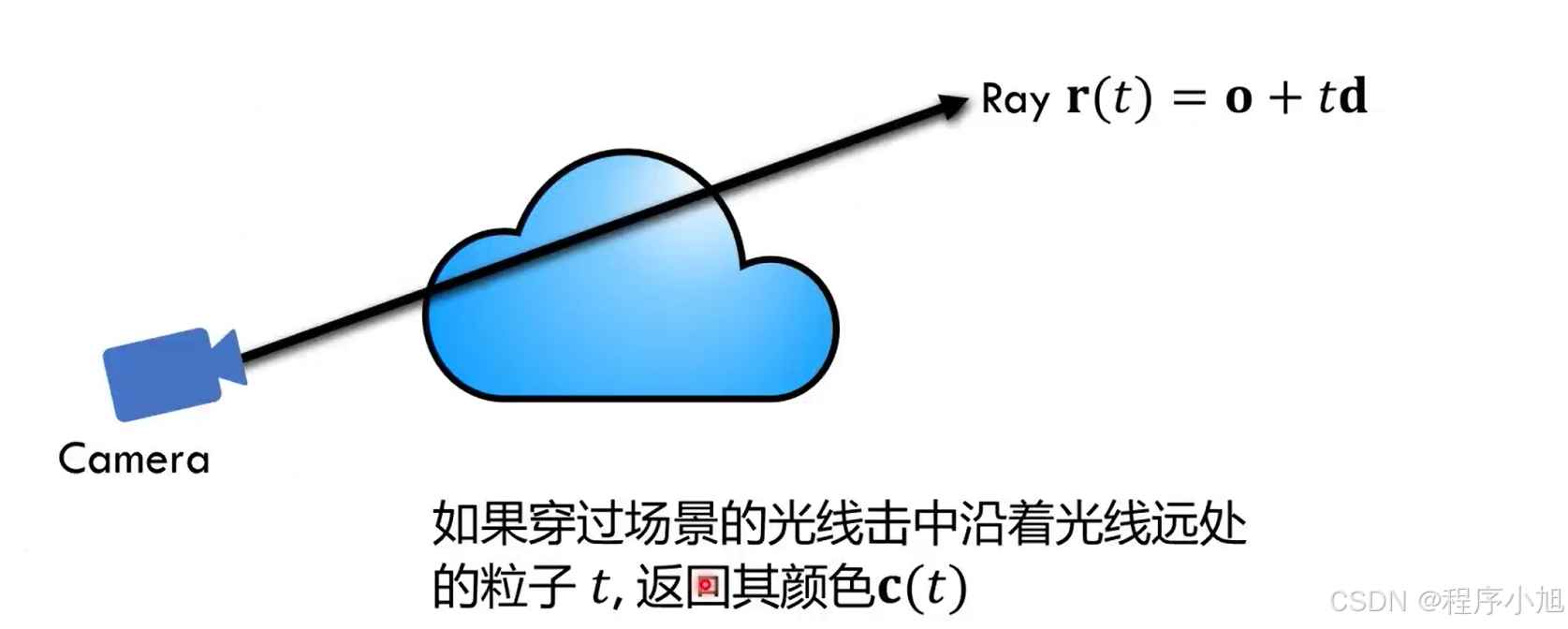
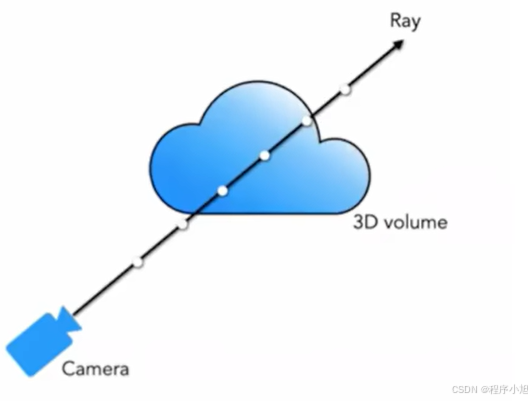
首先我们定义一条光线的公式为:r(t)=0+td
r ( t ) = 0 + t d r(t)=0+t d r(t)=0+td
-
O:表示的是光线的起始位置。
-
t:表示在光线上经过的距离
-
d:代表着光线所对应的方向

(选取采样点 t1,t2,t3)例如每间隔多少个点或者说间隔多少的距离。
方法:设置near=2,far=6 在near和far之间均匀采样64个点
训练时,一张图片取1024个像素,得到1024条射线,每条射线上采样64个粒子共1024*64个粒子
粒子以batch形式输入模型。
三维重建的隐式神经表示:
-
像素点对应射线上的一组采样点的颜色值(r,g,b)和不透明度(o)
-
射线方向上对采样渲染点进行积分,在第一次出现波峰对该像素点的着色影响最大
- 注:Density(密度值/不透明度):o该值与观测角度无关
Direction(观测角度):(θ,Φ)这个是球坐标的表现方法只需两个参数,方位角和俯仰角,代表的是相机位置与成像平面所对应像素连线发出的“光线”射线的方位。
我们说一个像素点对应的射线和一组采样点位置,即为一个训练资料。
神经网络输入仅有相机参数所以一个深度学习网络模型只能训练一个物体,这个三维模型的渲染信息就隐式地储存在深度学习模型中,而不是像点云体素是显示的表示。一个神经网络模型只需要40mb的大小就能储存下3D模型内容.
经过之前的内容我们可以知道当得到对应的采样点的位置坐标之后我们将其输入到神经网络中就可以通过计算获得对应的RGB信息。
坐标系转换的计算
在体渲染的过程中,需要涉及到坐标系的相关计算。这里的坐标系分为以下几种类型。
-
世界坐标系
-
相机坐标系
-
像素坐标系(平面坐标系)
对于这几种坐标变换进行简单的说明。
- 真实的物体位于坐标系中是位于世界坐标系中。相机加物体的一个坐标系
- 相机坐标系是指以照相机作为原点,物体相对于照相机的一个位置坐标。
- 平面坐标系(图像坐标):要渲染的图像上的点在图像上的坐标位置信息。
这三种坐标直接的变换就需要涉及到相机的外参和相机的内参,来进行坐标的变换。
相机内参变换
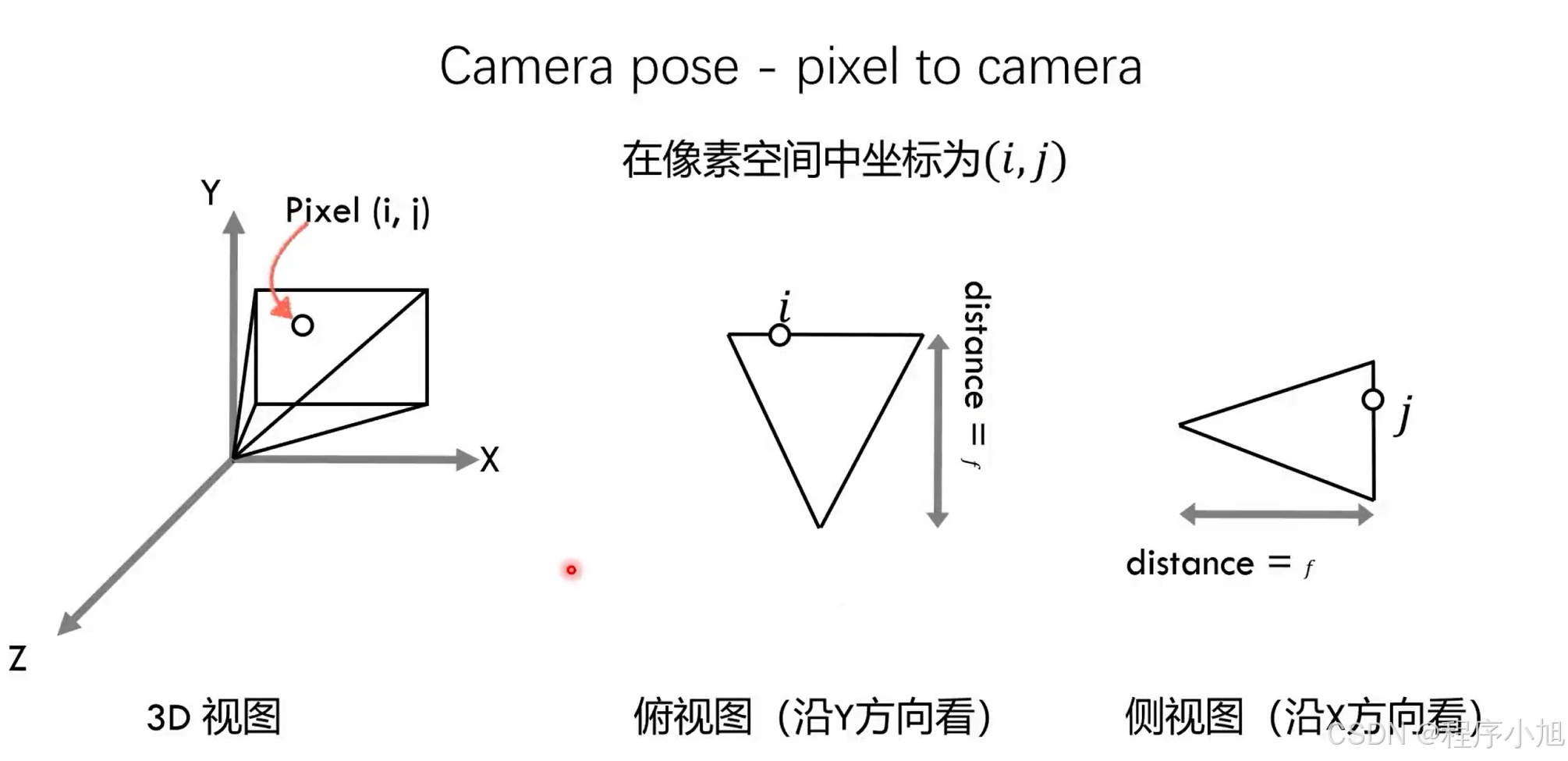
从原点位置向二维的图像发射多条射线,与每一个像素形成交点。我们将像素空间中的一个点定义为(i,j)
其中我们的distance代表的是焦距。图片像素映射到[0,1] ,像素的位置位于(i/w,j/h)处,(w,h)是图片的分辨率。
通过相机的内参完成二维图像上的点到相机坐标的一个映射关系。
先计算其相对于中间坐标的一个位置。
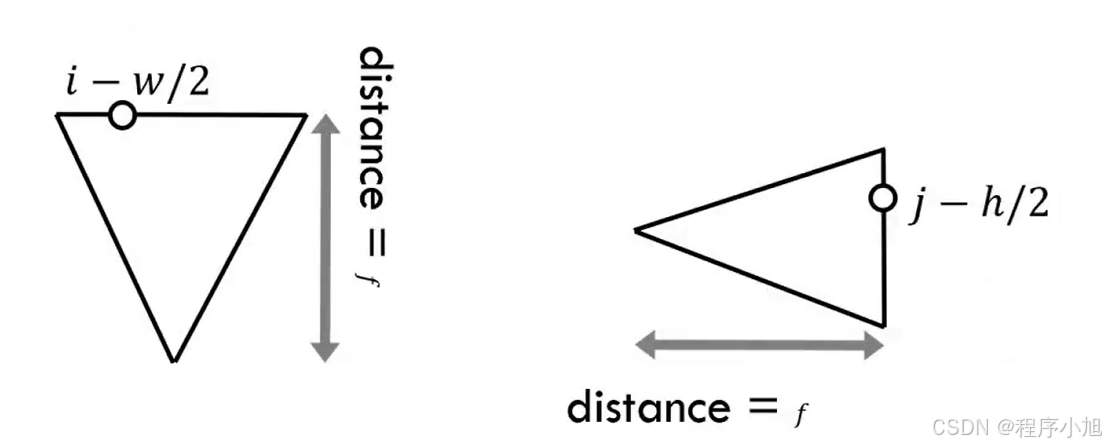
图像映射到[-w/2f;w/2f] ×[-h/2f,h/2f,]焦距f控制“缩放"的大小
从而通过映射
(
i
,
j
)
→
(
i
−
w
/
2
f
,
j
−
h
/
2
f
,
−
1
)
(i, j) \rightarrow\left(\frac{i-w / 2}{f}, \frac{j-h / 2}{f},-1\right)
(i,j)→(fi−w/2,fj−h/2,−1)
以获得平面上点的3d坐标信息。 摄相机空间光线从原点指向该点。
相机外参变换
我们之前是将一个二维的图像从像素坐标,结合相机的内参变换到了相机坐标系下。
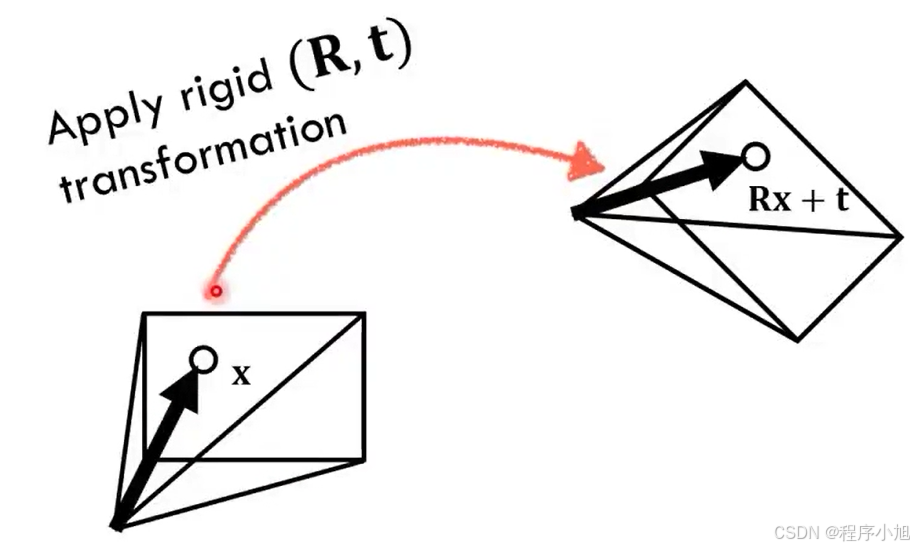
之后在通过相机的外参变换到世界坐标系的下面。
只需将刚性旋转和平移应用于原点和图像平面点(六个自由度)
光线颜色计算公式 C( r ) 我们认为是投射出来的光线所呈现的颜色。(体渲染表示为连续积分)
C ( s ) ^ = ∫ 0 + ∞ T ( s ) σ ( s ) C ( s ) d s T ( s ) = e − ∫ 0 s σ ( t ) d t \begin{array}{l} \hat{C(s)}=\int_{0}^{+\infty} T(s) \sigma(s) C(s) d s \\ T(s)=e^{-\int_{0}^{s} \sigma(t) d t} \end{array} C(s)^=∫0+∞T(s)σ(s)C(s)dsT(s)=e−∫0sσ(t)dt
连续类型的体渲染公式
C ( r ) = ∫ t n t f T ( t ) σ ( r ( t ) ) c ( r ( t ) , d ) d t , where T ( t ) = exp ( − ∫ t n t σ ( r ( s ) ) d s ) C(\mathbf{r})=\int_{t_{n}}^{t_{f}} T(t) \sigma(\mathbf{r}(t)) \mathbf{c}(\mathbf{r}(t), \mathbf{d}) d t \text {, where } T(t)=\exp \left(-\int_{t_{n}}^{t} \sigma(\mathbf{r}(s)) d s\right) C(r)=∫tntfT(t)σ(r(t))c(r(t),d)dt, where T(t)=exp(−∫tntσ(r(s))ds)
- C( r ) 我们认为是投射出来的光线所呈现的颜色
- σ(r(t) 是我们预测出来的体密度
- c(r(t),d) 是指预测出来的一个颜色
- T(t)指的是透射率没有发射阻挡
简单理解为一种体渲染的光学模型。
-
C(r):理想情况下,通过积分的方式计算像素点颜色值。
-
C^(r):算法实际计算,通过求和的方式近似积分的方式求和。(因为计算机无法处理这样的积分方式。图片中的颜色值、不透明度都不是连续的值。所以,公式也需要进行离散化,采样点的计算数量是有限的,就像图片的分辨率一样)
-
t:采样点离原点o的距离
-
o:密度值/不透明度
-
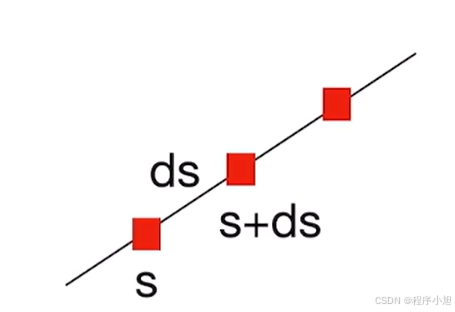
dieo:采样点间距
-
T(t):可以理解为不透光率是将采样点的密度值(o)*影响范围(dieo)累加起来,那么越叠不透光率就越高
离散采样公式:
C ^ ( r ) = ∑ i = 1 N T i ( 1 − exp ( − σ i δ i ) ) c i , where T i = exp ( − ∑ j = 1 i − 1 σ j δ j ) \hat{C}(\mathbf{r})=\sum_{i=1}^{N} T_{i}\left(1-\exp \left(-\sigma_{i} \delta_{i}\right)\right) \mathbf{c}_{i}, \text { where } T_{i}=\exp \left(-\sum_{j=1}^{i-1} \sigma_{j} \delta_{j}\right) C^(r)=i=1∑NTi(1−exp(−σiδi))ci, where Ti=exp(−j=1∑i−1σjδj)
t i ∼ U [ t n + i − 1 N ( t f − t n ) , t n + i N ( t f − t n ) ] t_{i} \sim \mathcal{U}\left[t_{n}+\frac{i-1}{N}\left(t_{f}-t_{n}\right), t_{n}+\frac{i}{N}\left(t_{f}-t_{n}\right)\right] ti∼U[tn+Ni−1(tf−tn),tn+Ni(tf−tn)]
- c(r(t),d):代表颜色值c与采样点位置和观测角度都有关
- o(r(t)):代表不透明度仅与位置有关与观测角度无关
其中: δ i = t i + 1 − t i \text { 其中: } \delta_{i}=t_{i+1}-t_{i} 其中: δi=ti+1−ti
公式的推导过程
r ( t ) = 0 + t d r(t)=0+t d r(t)=0+td
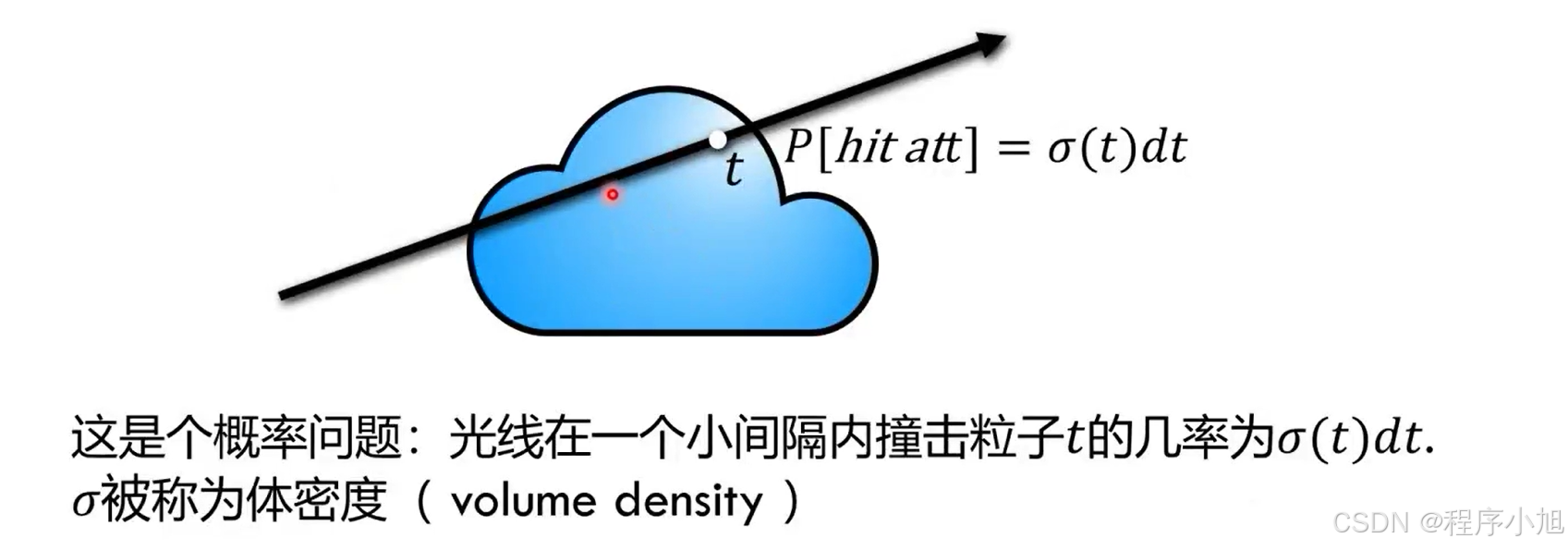
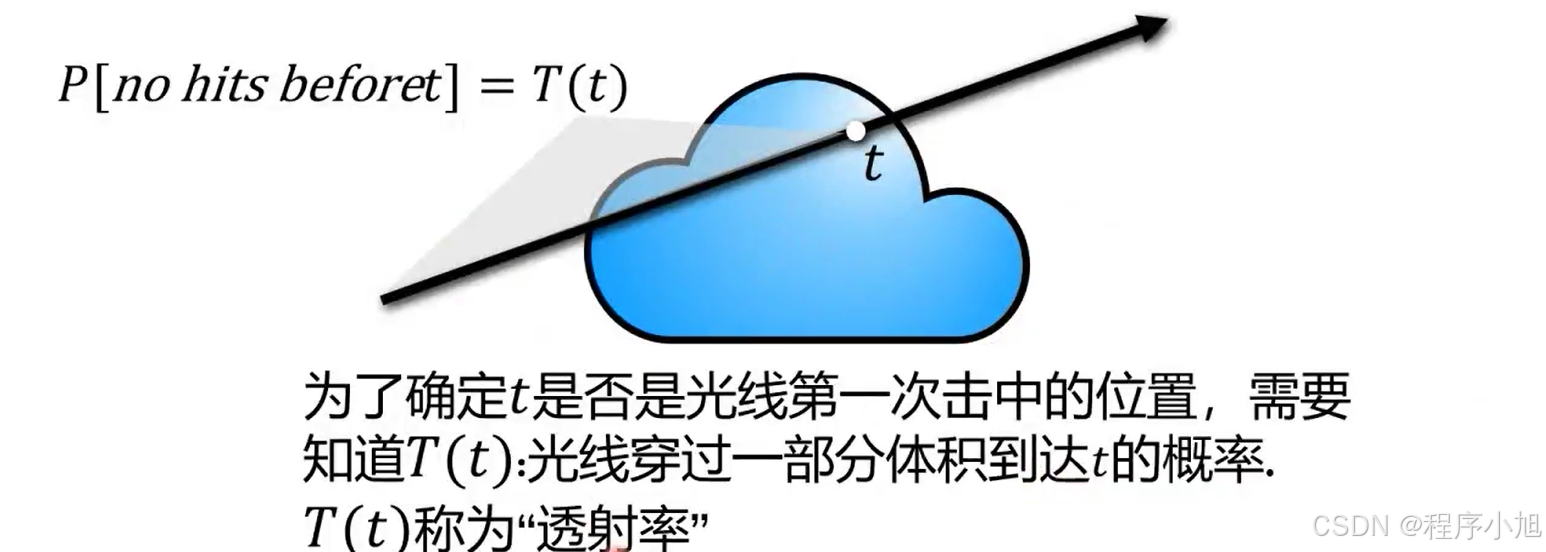
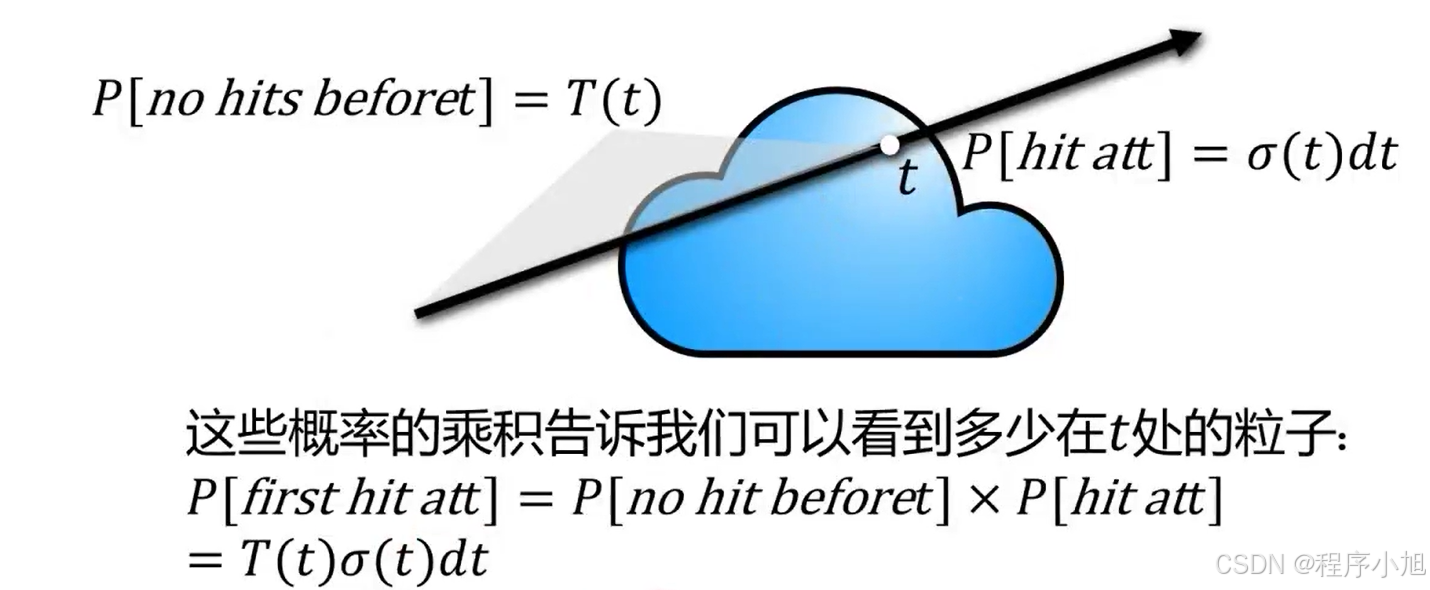
含义:
用 network 存体素信息:然后用体素渲染方程获得生成视角图片:光线采样+积分。最后与原视角图片计算损失更新网络
T ( s + d s ) = T ( s ) ( 1 − σ ( s ) d s ) T ( s + d s ) − T ( s ) = − T ( s ) σ ( s ) d s d T ( s ) T ( s ) = − σ ( s ) d s T ( s ) = e − ∫ 0 s σ ( t ) d t C ^ ( t ) = ∫ 0 ∞ T ( s ) σ ( s ) C ( s ) d s \begin{array}{c} T(s+d s)=T(s)(1-\sigma(s) d s) \\ T(s+d s)-T(s)=-T(s) \sigma(s) d s \\ \frac{d T(s)}{T(s)}=-\sigma(s) d s \\ T(s)=e^{-\int_{0}^{s} \sigma(t) d t} \\ \hat{C}(t)=\int_{0}^{\infty} T(s) \sigma(s) C(s) d s \end{array} T(s+ds)=T(s)(1−σ(s)ds)T(s+ds)−T(s)=−T(s)σ(s)dsT(s)dT(s)=−σ(s)dsT(s)=e−∫0sσ(t)dtC^(t)=∫0∞T(s)σ(s)C(s)ds
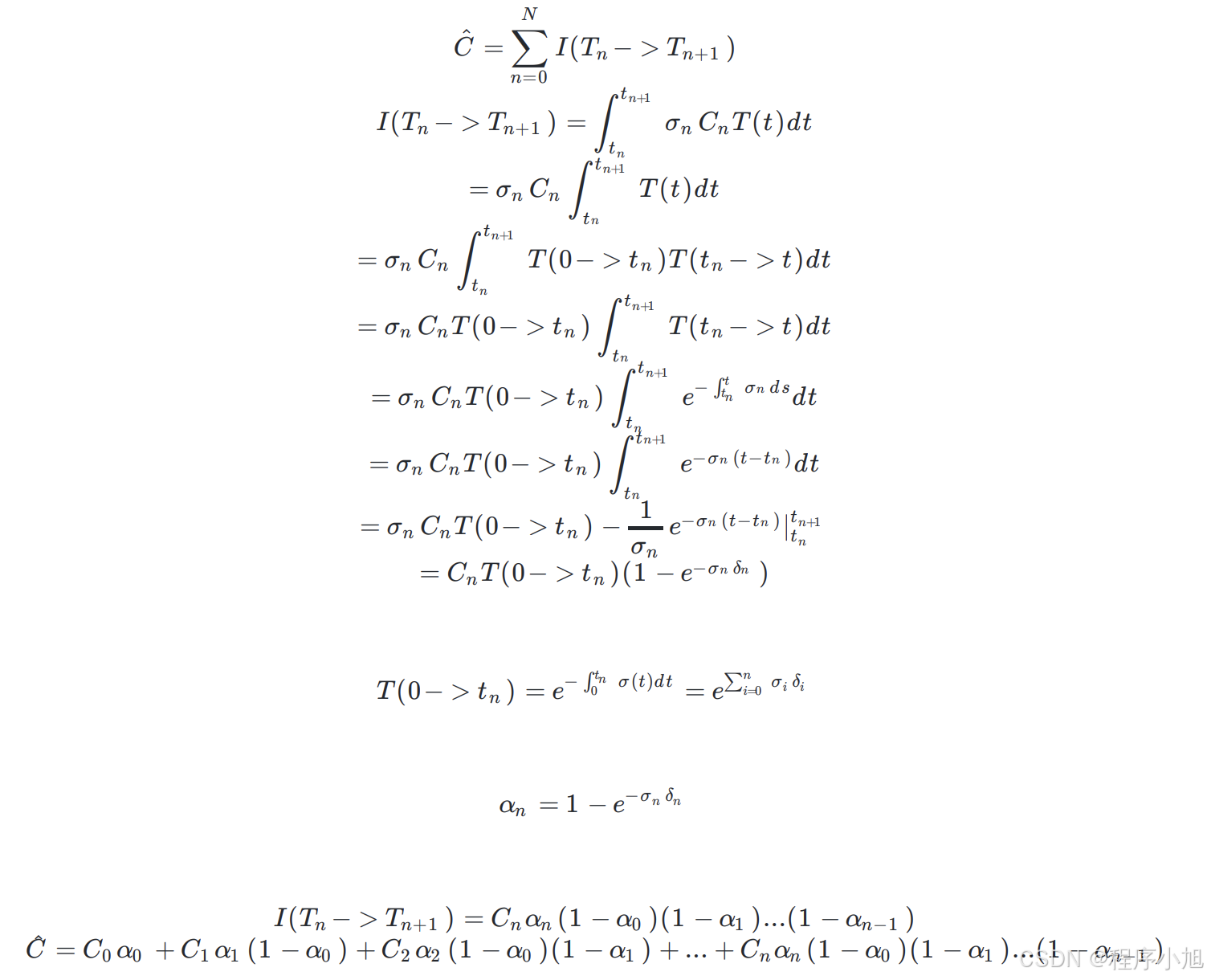
输入模型中的每一个粒子,模型给出该点的一个颜色值,经过上面的连续积分后就可以得出该射线对应像素的一个像素值信息。
网络结构
分层采样
Hierarchica丨sampling 分层采样(在不同的层选择使用粗网络进行采样或使用精细网络来进行采样,即所谓的分层采样的概念。)
- 粗网络coarse,均匀采样64个点
- 精细网络fine,基于粗网络的结果权重逆变换采样128个点,并带上之前粗网络的64个点=192个点
粗网络coarse采样:
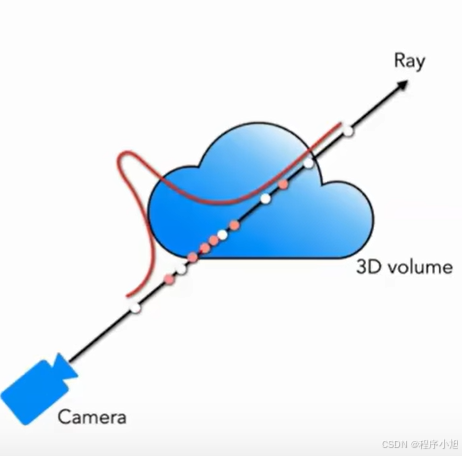
缺点:如果仅使用粗网络会存在点位浪费和欠采样的问题,比如空气中很多无效的点
精细网络采样:
在密度值高的地方多采样一些点,在密度值低的地方少采样一些点。这个权重w是基于粗网络中输出的“密度值o”,权重可以看作为射线的分段常数概率密度函数(Piecewise-constantPDF)
C ^ c ( r ) = ∑ i = 1 N c w i c i , w i = T i ( 1 − exp ( − σ i δ i ) ) \hat{C}_{c}(\mathbf{r})=\sum_{i=1}^{N_{c}} w_{i} c_{i}, \quad w_{i}=T_{i}\left(1-\exp \left(-\sigma_{i} \delta_{i}\right)\right) C^c(r)=i=1∑Ncwici,wi=Ti(1−exp(−σiδi))
C ≈ ∑ i = 1 N T i α i ϵ i C \approx \sum_{i=1}^{N} T_{i} \alpha_{i} \epsilon_{i} C≈i=1∑NTiαiϵi
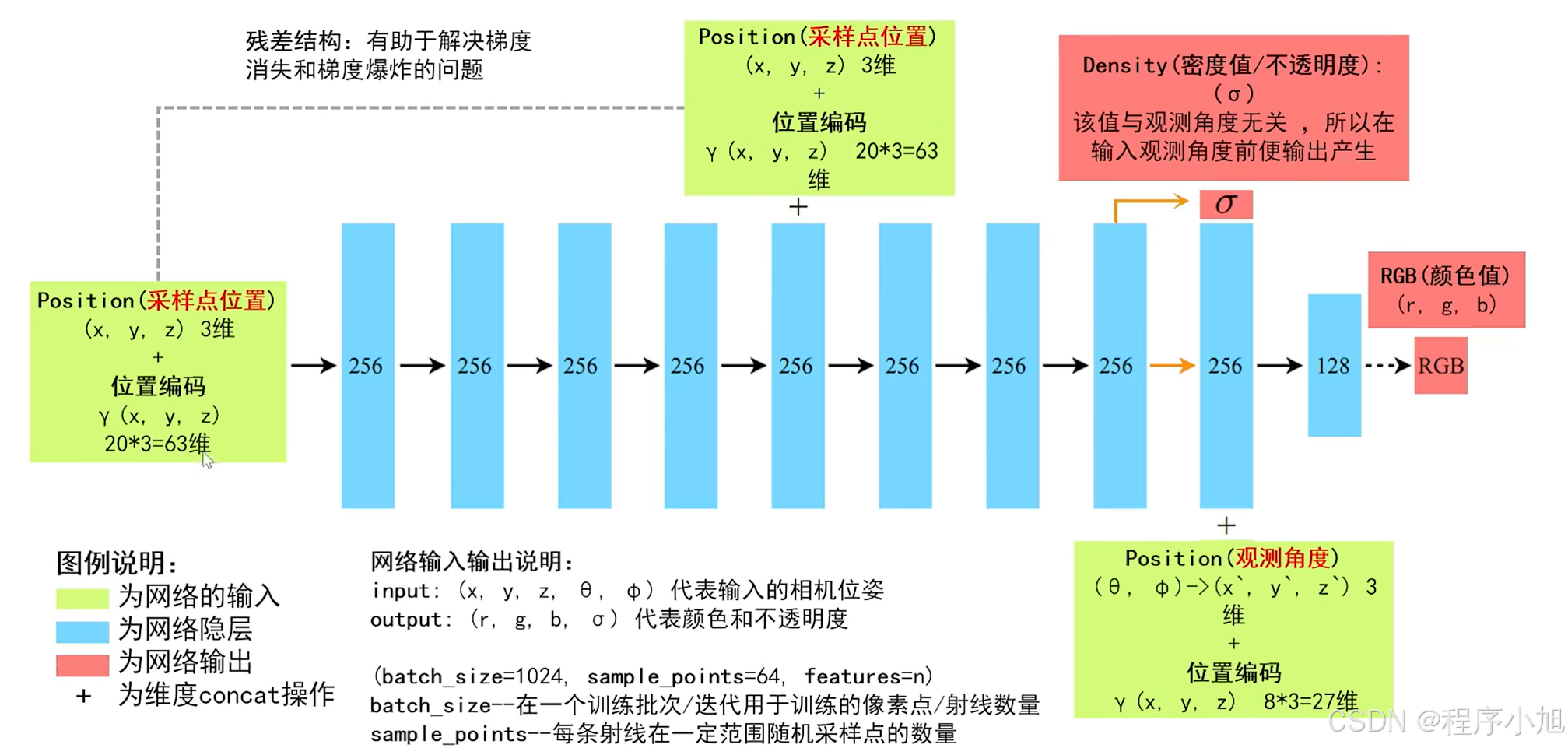
- 8层全连接层
- 半路再次输入位置坐标
- 后半路输出密度の
- 后半路输入方向视角
- 最后输出颜色RGB

训练方法
-
从数据集中采样一批相机光线(batch_size=4096)
-
使用分层采样查询粗略点和精细点
-
使用体渲染公式计算光线的颜色
-
计算渲染图像和真实图像像素之间的平方误差
L = ∑ r ∈ R [ ∥ C ^ c ( r ) − C ( r ) ∥ 2 2 + ∥ C ^ f ( r ) − C ( r ) ∥ 2 2 ] \mathcal{L}=\sum_{\mathbf{r} \in \mathcal{R}}\left[\left\|\hat{C}_{c}(\mathbf{r})-C(\mathbf{r})\right\|_{2}^{2}+\left\|\hat{C}_{f}(\mathbf{r})-C(\mathbf{r})\right\|_{2}^{2}\right] L=r∈R∑[ C^c(r)−C(r) 22+ C^f(r)−C(r) 22]

- 使用Adam优化网络参数


















 225
225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











