







论文连接
CORE: Cooperative Reconstruction for Multi-Agent Perception
0. 摘要
本文提出了 CORE,一种概念简单、有效且通信高效的多智能体协作感知模型。
-
从合作重建的新颖角度解决了该任务:
- 合作主体共同提供对环境的更全面的观察
- 整体观察可以作为有价值的监督,明确指导模型学习如何基于协作重建理想的观察
-
CORE 利用三个组件实现:
- 每个代理共享的压缩器,用于创建更紧凑的特征表示以实现高效广播
- 用于跨代理消息聚合的轻量级细心协作组件
- 基于聚合特征表示重建观察的重建模块
CORE 模型在 OPV2V 数据集上进行验证,包括 3D 对象检测和语义分割两个任务。
1. 简介
感知——识别和解释感官信息,是智能体感知周围环境的关键能力。得益于深度学习的不断进步,个体感知在多项任务中展现出了令人瞩目的成就。尽管前景广阔,但它往往会遇到由于单个代理的视线可见性有限而引起的问题(例如遮挡),并且受到安全问题的挑战。
协同感知的方法达成了共识:利用多个代理共同提供对环境的观察。但需要解决性能与带宽权衡的实际挑战。其中,有一个关键问题尚未得到解决:
经过信息交换和聚合后,每个智能体的理想感觉状态是什么样的?
本文提出了一种从合作重建的新颖角度出发的方法。

CORE 从合作重建的新角度解决了多智能体感知问题。CORE 采取了一个简单但非常有效的步骤来解决这个问题:除了任务感知学习(例如,对象检测、语义分割)之外,CORE 还明确地学习从合作代理的不完整观察中重建完整的场景(即重建的 BEV)。重建感知学习目标是一个更明智的目标,可以激发互联代理更有效的合作,最终提高感知性能。
CORE 通过三个关键的模块进行协同重建:压缩模块,协作模块,重建模块
-
压缩模块计算每个BEV的压缩特征表示以实现高效传输。与大多数仅考虑通道压缩的先前工作不同,该模块通过沿空间维度屏蔽(子采样)特征来施加更显着的压缩
-
协作模块是一个轻量级的注意力模块,它鼓励合作代理之间的知识交换,以增强每个代理的特征表示
-
重建模块采用解码器结构从增强的特征表示中恢复完整的场景观察
在本文的工作中,原始数据融合因为需要较高的通信成本,仅在训练阶段使用,整个重建模块在推理过程中将被丢弃。
2. 相关工作
协同感知
协作感知使多个智能体能够通过共享观察结果和知识来协作感知周围环境,这为提高个体的安全性、弹性和适应性提供了巨大的潜力。
早期研究中广泛研究的一种简单的解决方案是在合作代理之间直接传输和融合原始传感器数据。尽管性能改进很有希望,但传输高维数据所需的昂贵通信带宽限制了它们在实际情况中的部署。
最近,基于中间融合的方法广播了紧凑的中间表示,已被广泛研究,因为它们能够在感知性能和网络带宽之间提供更好的权衡。这些方法的一个主流分支是采用注意力机制来获得融合权重,而其他方法使用图神经网络对不同代理之间的相对关系进行建模。
CORE
CORE 与 DiscoNet 密切相关,因为两种方法都依赖于早期协作来产生整体视图输入并利用它们作为网络学习的有价值的指导。然而,CORE 解决了基于学习到重构的问题。
CORE 主要由两个有点
-
通过优化重建感知目标,CORE 实现了更好的泛化性并提高了感知性能
-
重构思想使得CORE能够进一步屏蔽掉要传输的空间特征,从而实现更高效的通信
3. 方法
CORE 的框架图如下
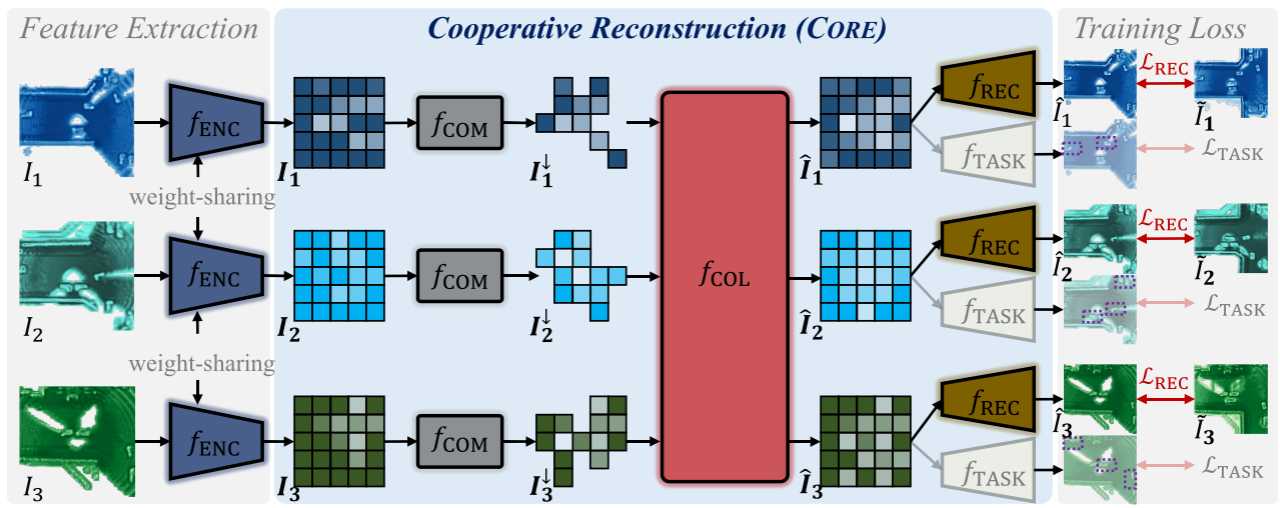
给定单个代理的原始 BEV 表示(即 I 1 、 I 2 、 I 3 I_1、I_2、I_3 I1、I2、I3 ),CORE 通过多个组件实现协作感知:用于特征提取的共享 f E N C f_{ENC} fENC 、用于空间和通道特征压缩的压缩器 f C O M f_{COM} fCOM 、轻量级专注协作器 fCOL对于信息聚合,重建解码器 f R E C f_{REC} fREC 用于回归理想、完整的 BEV(即 I 1 ^ 、 I 2 ^ 、 I 3 ^ \hat{I_1}、\hat{I_2}、\hat{I_3} I1^、I2^、I3^ ),以及用于例如对象检测的特定于任务的解码器 f T A S K f_{TASK} fTASK 。 CORE 由重建 L R E C \mathcal{L}_{REC} LREC 和特定任务 L T A S K \mathcal{L}_{TASK} LTASK 损失联合训练。
CORE 的基本流程图如下
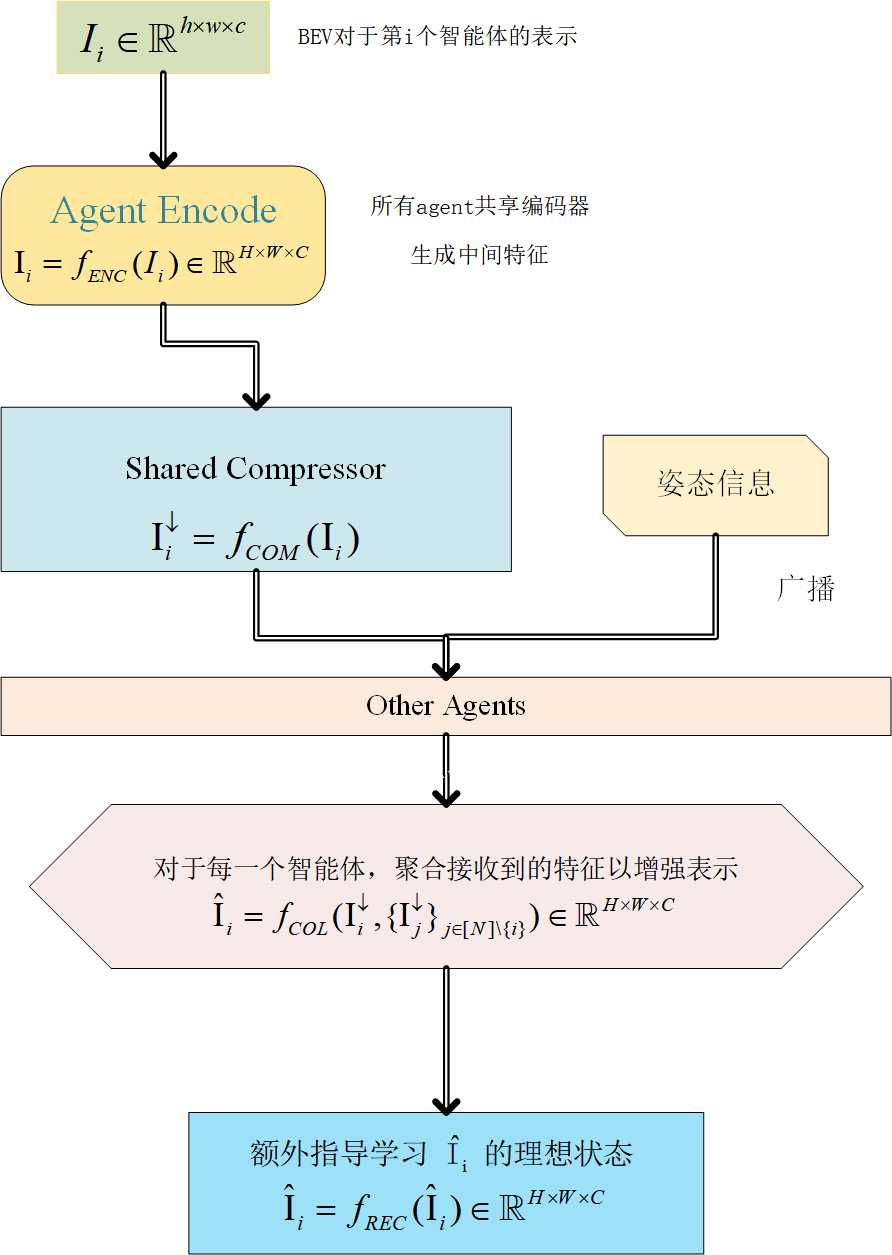
3.1 特征压缩与共享
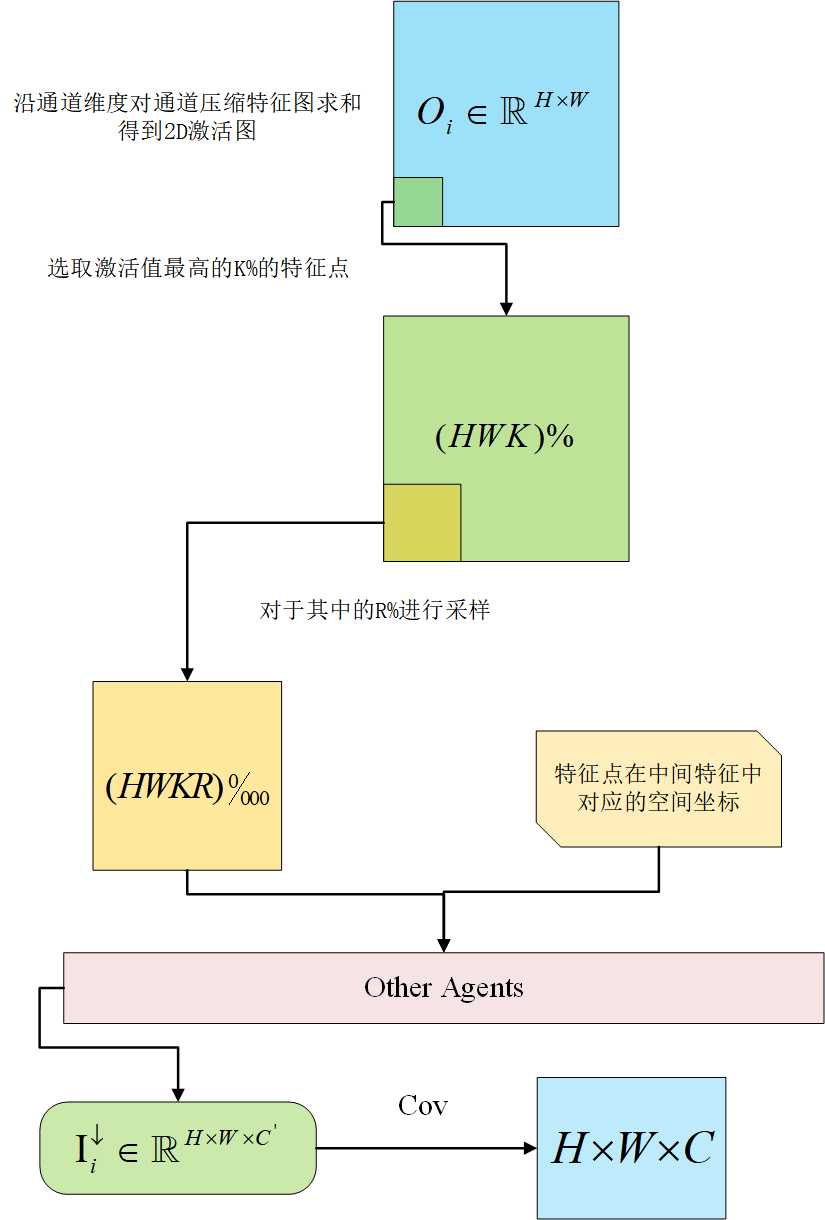
特征压缩的目标是在保持感知性能的同时尽可能地减少通信带宽。以前的方法仅通过 1 × 1 卷积自动编码器等沿通道维度压缩特征(例如,代理 i 的 I i I_i Ii )。然而,我们认为简单地压缩信道维度并不能最大程度地节省带宽。
具体来说,对于通道压缩,我们按照使用一系列1×1卷积层逐步压缩Ii,压缩后的特征具有形状 (H,W,C′) 且 C′≪C。
其特征图压缩流程如下图所示
3.2 注意机制协作
多智能体协作学习的重点是通过聚合来自其合作伙伴的信息消息来更新每个智能体的特征图。
其注意机制协作的流程图如下:
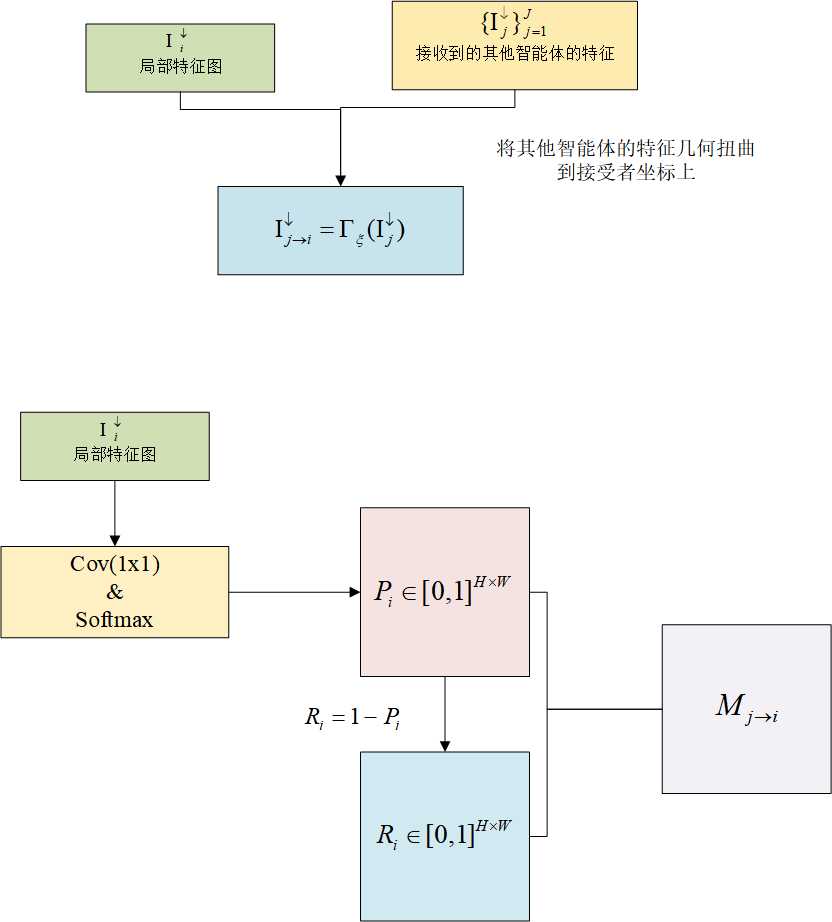
其中, P i P_i Pi 传达了代理 i 可以向他人提供的信息代理。此外,我们通过 R i = 1 − P i R_i = 1 −P_i Ri=1−Pi 计算另一个置信图 R i ∈ [ 0 , 1 ] H × W R_i ∈ [0, 1]^{H×W} Ri∈[0,1]H×W 。与 P i P_i Pi 相比, R i R_i Ri 中具有较高值的空间位置表明存在由于遮挡或可见性有限而导致的潜在信息丢失,因此,它反映了代理 i 最需要的信息。
给定置信图,对于自我代理 i 及其伙伴代理 j,我们计算如下注意力图
M j → i = R i ⨀ P j ∈ [ 0 , 1 ] H × W M_{j→i}=R_i \bigodot P_j \in[0,1]^{H \times W} Mj→i=Ri⨀Pj∈[0,1]H×W
其中 ⨀ \bigodot ⨀ 是哈达玛积。这里,注意力图 M j → i M_{j→i} Mj→i 突出显示了智能体 i 需要信息而智能体 j 可以满足 i 的要求的位置。注意力图使我们能够执行更准确和自适应的特征聚合。除此之外,根据代理 j 的校准特征和注意力掩码更新自我代理 i 的特征。
其公式如下所示
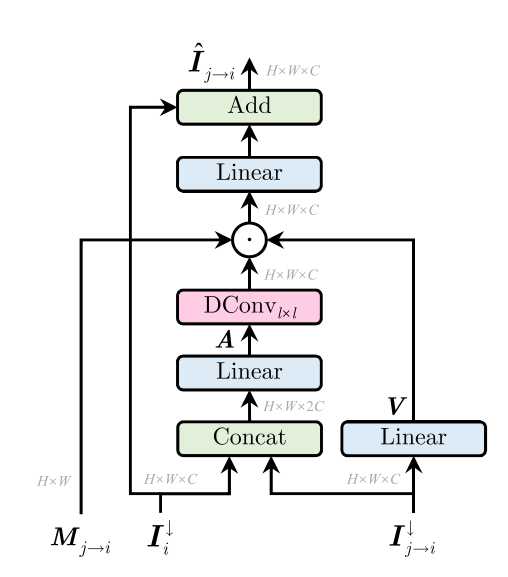
I ^ j → i ↓ = D C o n v l × l ( A ) ⨀ V ⨀ M j → i + I i ↓ ∈ R H × W × C , \hat{I}_ {j→i}^↓= DConv_{l\times l} (A)\bigodot V \bigodot M_{j→i} + I^↓_{i} \in \mathbb{R}^{H\times W \times C} , I^j→i↓=DConvl×l(A)⨀V⨀Mj→i+Ii↓∈RH×W×C,
A 和 W 分别为如下表示
A = W 1 [ I i ↓ , I j → i ↓ ] ∈ R H × W × 2 C , A=W_1[I^↓_{i},I^↓_{j→i}] \in \mathbb{R}^{H\times W \times 2C}, A=W1[Ii↓,Ij→i↓]∈RH×W×2C,
V = W 2 I j → i ↓ ∈ R H × W × C . V=W_2I^↓_{j→i} \in \mathbb{R}^{H\times W \times C }. V=W2Ij→i↓∈RH×W×C.
这里 I ^ j → i \hat{I}_ {j→i} I^j→i 是基于代理 j 的信息更新的代理 i 的消息, D C o n v l × l DConv_{l\times l} DConvl×l 表示内核大小为 l × l l\times l l×l 的深度卷积,生成输入通道数一半的输出。它增强了特征的感受野,同时降低了复杂性和计算成本。 ‘ [ ⋅ , ⋅ ] ’ ‘[·,·]’ ‘[⋅,⋅]’ 是一个通道式张量串联运算符,组合来自不同代理的消息。 W 1 W_1 W1 和 W 2 W_2 W2 是可学习的线性权重,允许跨渠道信息交互。
其计算结构如下图所示
3.3 BEV 重建
本文的 BEV 重建方案通过学习深度卷积解码器从交互的消息重建多视图 BEV 表示来缓解这些问题。

我们首先将来自所有相邻代理的点云 { S j } j = 1 J \{S_j \}^J_{j=1} {Sj}j=1J 投影到自我的坐标系: { S j → i } j = 1 J = Γ ξ ( { S j } j = 1 J ) \{ S_{j→i}\}^J_{j=1} = \Gamma_{\xi}(\{ S_j\}^J_{j=1}) {Sj→i}j=1J=Γξ({Sj}j=1J) 。接下来,我们聚合每个单独的点云以生成多视图 3D 场景: S ~ = f S t a ( { S j → i } j = 1 J , S i ) \tilde{S} = f_{Sta}(\{ S_{j→i}\}^J_{j=1}, S_i) S~=fSta({Sj→i}j=1J,Si) ,其中 f S t a ( ⋅ , ⋅ ) f_{Sta}(·,·) fSta(⋅,⋅) 是堆叠算子。
随后,我们投影回每个局部坐标并根据感知范围对其进行裁剪: S i ~ = Γ ξ − 1 ( S ~ ) \tilde{S_i} = Γ^{−1}_\xi (\tilde{S}) Si~=Γξ−1(S~) 。最后,我们将 S i ~ \tilde{S_i} Si~ 转换为其相应的 BEV 表示 I i ~ ∈ R h × w × c \tilde{I_i} ∈ \mathbb{R}^{h×w×c} Ii~∈Rh×w×c 。
对于每个智能体 i,重建解码器将更新后的特征 I i ^ \hat{I_i} Ii^ 作为输入,并重建相应的 BEV 特征,如下所示:
I i ^ = f R E C ( I i ^ ) ∈ R h × w × c \hat{I_i}=f_{REC}(\hat{I_i}) ∈ \mathbb{R}^{h×w×c} Ii^=fREC(Ii^)∈Rh×w×c
重建损失计算为它们之间的均方误差 (MSE):
L R E C = ∑ x = 1 h ∑ y = 1 w ∣ ∣ I i ^ ( x , y ) − I i ~ ( x , y ) ∣ ∣ 2 2 \mathcal{L}_ {REC}=\displaystyle \sum^{h}_ {x=1}\displaystyle \sum ^{w}_ {y=1} ||\hat{I_i}(x,y)-\tilde{I_i}(x,y)||^2_2 LREC=x=1∑hy=1∑w∣∣Ii^(x,y)−Ii~(x,y)∣∣22
3.4 网络结构细节
网络结构由三个主要部分组成:
特征提取器
特征提取器
f
E
N
C
f_{ENC}
fENC 将 BEV 表示作为输入并将其编码为中间特征。我们通过三个内核大小为3×3的2D卷积层来实现它,并且在每层之后采用批量归一化层和ReLU激活层。
重构解码器
重建解码器
f
R
E
C
f_{REC}
fREC 用于生成高质量的 BEV 特征。它由三个块组成,每个块由一个 2×2 转置卷积层和一个 3×3 普通卷积层组成。每层后面都有一个批量归一化层和一个 ReLU 激活层。
任务特定解码器
对于分割,解码器由三个用于上采样的反卷积层和一个用于生成最终语义分割图的 3×3 卷积层组成。
对于整个网络,其损失函数如下所示
L = L T A S K + λ L R E C \mathcal{L}=\mathcal{L}_ {TASK} + λ\mathcal{L}_ {REC} L=LTASK+λLREC
其中第一项 L T A S K \mathcal{L}_ {TASK} LTASK 是特定于任务的损失。对于检测,我们使用焦点损失作为分类损失,并使用平滑损失进行边界框回归。对于分割,我们使用交叉熵损失。第二个是我们的重建损失 L R E C \mathcal{L}_ {REC} LREC ,用于监督重建解码器的输出。系数 λ 平衡两个损失项。
4. 实验
4.1 实验设置
数据集
我们的实验是在 OPV2V 上进行的,这是一个由联合仿真框架 OpenCDA 和 CARLA 模拟器收集的大规模公共数据集,用于车辆间协作感知。
训练
在训练阶段,从场景中随机选择一组可以相互建立通信的智能体,每个智能体被分配70 m的通信范围。对于 3D 物体检测任务,我们将沿 x、y 和 z 轴的点云范围限制为 [−140.8, 140.8] × [−40, 40] × [−3, 1],并将点云范围限制为 [−51.2] , 51.2] × [−51.2, 51.2] × [−3, 1] 用于 BEV 语义分割任务。由于体素分辨率设置为0.4 m,我们可以得到分辨率分别为200×704×128和256×256×128的BEV图。我们对训练数据应用了多种数据增强技术,包括随机翻转、[0.95, 1.05] 范围内的缩放以及 [−45°, 45°] 的旋转。我们使用 Adam 优化器来训练我们的 CORE,学习率为 0.002,批量大小为 1。我们还采用基于验证损失的早期停止来防止过度拟合。根据经验,超参数 λ、R 和 K 分别设置为 1、90 和 90。
推理
我们应用 0.25 的置信度阈值和 IoU 阈值 0.15 的非极大值抑制 (NMS) 来过滤掉重叠检测
基线
构建了两个基线模型。无协作是指仅使用单个传感器数据而没有来自其他代理的任何信息的单代理感知系统。早期协作在感知管道的早期阶段直接聚合来自多个代理的原始传感器数据。后期协作收集多个智能体的预测结果,并使用 NMS 组合它们以提供最终结果。
评估标准
交并并集 (IoU) 阈值分别为 0.5 和 0.7 时的平均精度 (AP)
4.2 定量结果
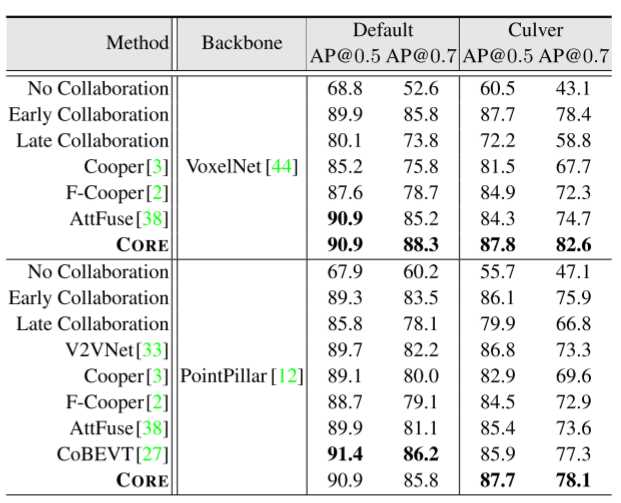
3D 目标检测
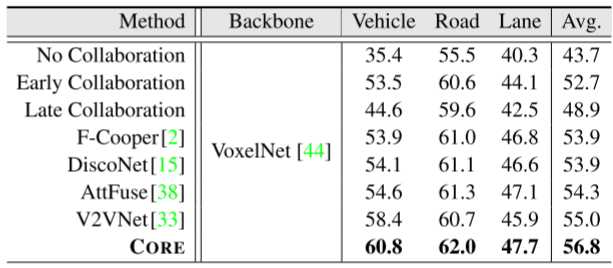
BEV 语义分割
4.3 定性结果
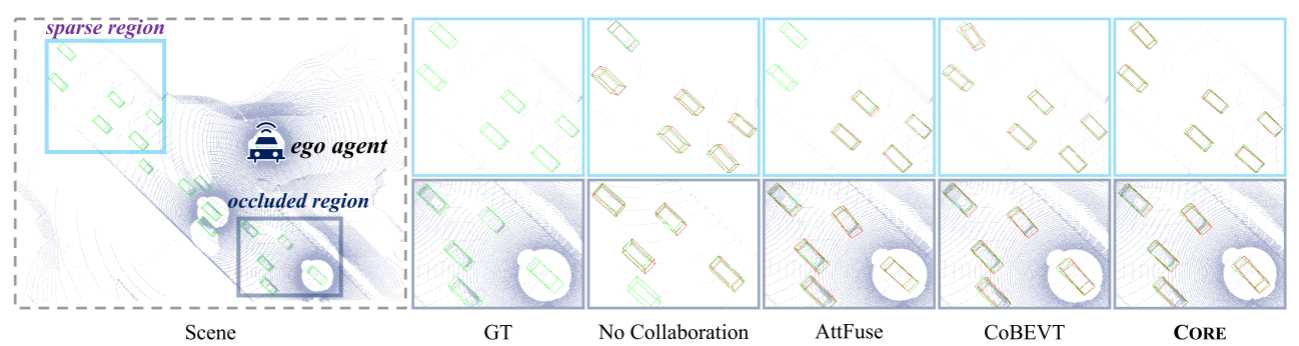
CORE 可以成功地检测杂乱、稀疏的点云和遮挡环境中的多个对象

CORE即使在拥挤和动态环境等复杂场景下也能实现高质量的分割结果
4.4 消融实验
关键因素分析
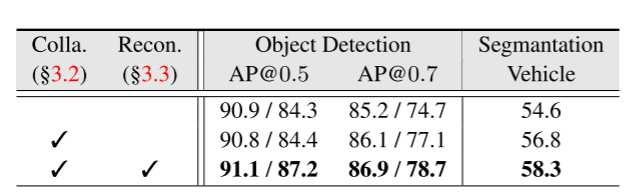
通过单独添加注意力协作(即“Colla.”)模块,我们观察到 AP@ 0.7 和 IoU 分数有所提高,与基本情况相比,对 AP@ 0.5 的影响轻微。在协作模块之上添加 BEV 重建(即“侦察”)模块可以进一步改善所有指标。此外,结合重建模块还可以显着提高分割性能,与协作基线相比,IoU 提高了 1.5%。这些发现证明了协作和重建模块在多智能体感知任务中实现最先进性能的重要性。
空间特征压缩
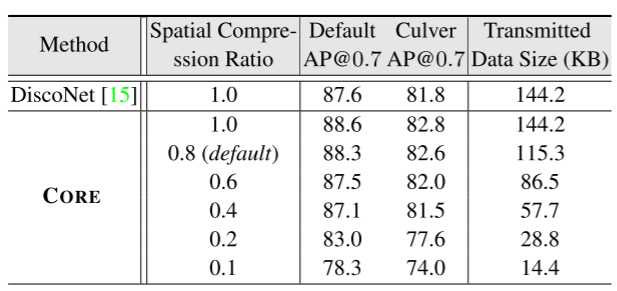
随着空间压缩比从 1.0 增加,性能逐渐下降至 0.1。但令人欣喜的是,即使在 0.4 的大压缩比下,CORE 也能够提供非常有前景的性能。此外,比率为0.6的CORE可以达到与无压缩的DiscoNet相当的性能。为了更好地权衡感知性能和通信效率,我们默认将空间压缩比设置为0.8。
超参数 R 和 K
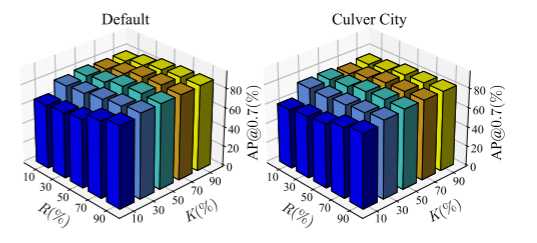
随着 R 或 K 变小,CORE 的性能往往会变差。然而,我们观察到 CORE 对于这些超参数通常是鲁棒的,即使压缩比低至 10%,性能下降也是中等的。
超参数 λ
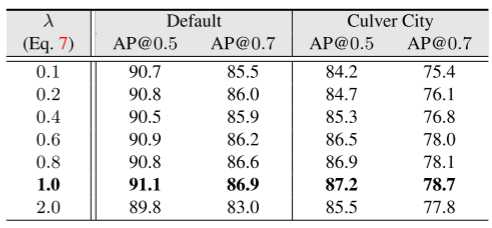
最佳性能是在 λ = 1 时实现的,并且当 λ 从此最佳值增加或减少时,我们观察到性能略有下降。
5. 总结
本文引入了 CORE 来解决多智能体场景中的协作感知问题。通过从协作重建的角度解决任务,CORE能够学习更有效的多智能体协作,这有利于特定的感知任务。此外,协作重建自然地与屏蔽数据建模的思想联系在一起,启发我们屏蔽空间特征以进一步减少传输的数据量。 CORE 在 3D 对象检测和 BEV 语义分割任务中展示了 OPV2V 的卓越性能与带宽权衡。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









