






子空间是啥:

平凡子空间:{0}(只有一个0元素)和V(原本的子空间)
向量组生成的子空间:

比如说,我们的三维空间就是由三个标准基组成的向量组“张”成的空间,而标准基组成的向量组就是三维空间的一个生成向量组。由于都是用一堆向量乘以系数得到的向量,显然大家都是满足对加法,数乘封闭的要求的,天然就是子空间。

子空间的生成组可以线性有关,要求不高。
核与像:

kerA(A的核)其实就是Ax=0的解空间,这些x其实都是解向量
imA就是以A的列向量为向量组(有n个,每个向量为m维,故imA)生成的向量们,y就是A生成的那些向量,也是一个子空间
子空间的交与和


线性映射

线性映射就是保加法,保数乘。
若V1=V2=V,则“谁他”是V上的线性变换,若“谁他”可逆(是一一对应的映射),则“谁他”为线性同构(可以视作是一样的东西)

线性映射的矩阵表示

谁他就是左乘A嘛,给每个标准向量做映射相当于给整个标准基矩阵乘A

这个地方相当于要解一个方程,找到做了映射之后的a在北塔基之下的表示,得到一个向量。大家所有的向量组成一个矩阵叫做A.

这张图给的有点误导性。那个线性映射指的是函数,不是说左乘。
假如出口基和入口基一致的话,那就叫“以……为基的矩阵表示”,不会写谁是入口谁是出口。
假如这个时候问“原本是x的向量,做了线性映射之后是多少?”就回答Ax。因为A记录了原本的基有什么变化,影射了的向量当然也是同样的变化。

a可以写成[a1,a2,a3……]*x,可以写成a1*x1+a2*x2……,做映射之后就是x1*f(a1)+x2*f(a2)……[f(a1),f(a2),……]啥的就是入口基映射之后的样子,我们知道它还可以写成[b1,b2,……]*A,因此a映射之后的坐标就是[b1,b2……]*A*[x1,x2,……]T,因此在出口基下的坐标就是Ax
从简单的角度理解,虽然做了线性映射,但原本的向量和原本的基的关系没有变。原来的大哥(入口基)现在变成A了(入口基映射后在出口基下的坐标矩阵),小弟自然也就是用自己原来的坐标左乘以老大哥的新坐标(A)就是自己的新坐标(在出口基下的坐标)
显然,当出口基与入口基发生变化,同样一个映射其矩阵表示也会变化。
下面是一个例子:

这个例子解释了为什么我们在用矩阵表示线性映射的时候还总是想着入口基与出口基的变化,因为我们遇到的问题可能不是在同一类矩阵上的线性映射,自然在映射完之后我们还要面对基发生变化的问题。
这种题目首先看原本的入口基映射完了之后会变成什么样。可以看到原本的入口基是1,x,x^2,x^3,映射之后就变成了0,1,2x,3x^2
这四个向量在新的基下的表示分别为[0,0,0][1,0,0][0,2,0][0,0,3],这四个列向量组成的矩阵就是A。
另一个例子:旋转变换

这里的入口基和出口基都是原本的标准基,因此入口基映射之后在出口基下的坐标其实就是入口基映射之后的坐标。只要知道了标准基在映射之后的坐标,这些坐标组成的矩阵就是A。假如想知道某个向量在旋转之后是什么坐标,直接左乘A。例子中把z轴设置成了旋转轴,所以只要在意x,y就可以了。
还有一个例子:镜面反射

接下来又有两道题要写。
总结一下:可见只要知晓了A,这个线性映射就被我们拿捏了。接下来我们就只研究A了。
矩阵的等价与相似
矩阵等价


也就是说可以把这里的A当成一个线性映射,此时B就是在入口基为P,出口基为Q下的,线性映射A的矩阵表示(也就是上面之前说的A)(好他妈绕啊,能不能用一个字母表示?)
可以看到两个矩阵形状都是一样的。
我们之前说的某某映射的矩阵表示都是建立在基变换之上的。可以这么理解:每个线性映射都有一个本体矩阵表示最原始的那个变换,之前提到的什么A啊,都是考虑了基变换之后的情况,不然我们也不会一直说是“在这对基之下的矩阵表示”之类的限定词了。

A已知了,要找到一对刚刚好的入口出口,让B最简单。
也就是说,经过Q,P之后要把A化简成最简。也就是行变化列变换这些
你想啊,最简单的形式那不就是对角标准阵嘛?当然,A的秩我们需要考虑一下,B的秩要和它相等(毕竟P,Q都是满秩的)

简单来说,就是:
1.找Ax=0的基础解系(n-r个)(r是A的秩)作为Pr+1,Pr+2……Pn
2.将其扩充成一组基P=[P1,P2……Pr+1,Pr+2……Pn](直接用标准基凑)
3.求q1=Ap1,……qr=Apr,再将其扩充成有m个向量的基(直接用标准基)、
例题:

可以看到,在这种做法下,右边因为B是最简单的都是0,同时左边因为用了Ax=0的解对应的也是0.B的左边都是标准的因此可以直接复制Q的左半边,A这边也只要复制左半边就可以了。

矩阵相似

这回入口基和出口基都一样了
注意:只有方阵有矩阵相似的说法,和矩阵等价不同。


这个不变子空间和矩阵相似有啥关系?

这一节展示了相似三角形和不变子空间之间的同等性。
B21=0,那就是AP1=P1B11,B11只是对P1做列变换而已,相当于里面的列向量都是P1的像(imP1)。可以看到,A不管乘以P1的什么向量,最后得到的都是P1中的向量通过加加减减得到的向量,就是乘的不是P1中直接就有的向量而是做了一点列变换的,也就是往后面再乘一个项的问题,还是逃不出imP1的手掌心,因此imP1是A的不变子空间。
有这上面这个知识,我们就可以方便的把A变成一个上三角或者下三角的矩阵了:

利用不变子空间构建上三角的相似矩阵,只需要找到不变子空间的基就可以了(保证imP1是A的不变子空间)。下三角的也可以类似的构建
现在我们知道怎么用子空间实现相似块对角化了,但感觉还不够劲,毕竟块有点大。真对角化怎么说。

一个向量就直接Im成不变子空间了,劲!那什么样的向量能有这么劲呢?

当然是特征值与特征向量了。[p1,p2,……]是特征向量,最后的对角矩阵对角上的值就是特征值。

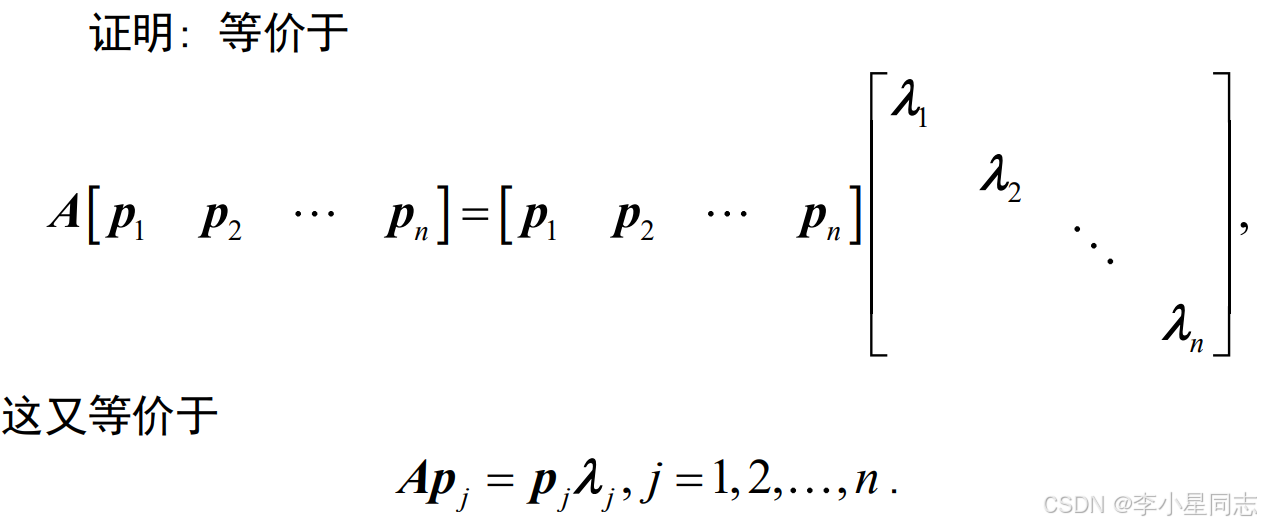
一个特征值可以对应好几个不同的,线性无关的特征向量,但有时候事情没有这么美好(可能一个3重的特征向量只能对应两个线性无关特征向量)那样就凑不成P矩阵了(P至少要线性无关吧?)
当然不是什么矩阵都可以找到n个特征向量。


















 5421
5421

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









