









文章目录

前言
出处: Feng Y, Li J, Sisodia D, et al. On Explainable and Adaptable Detection of Distributed Denial-of-Service Traffic[J]. IEEE Transactions on Dependable and Secure Computing, 2023.
代码资源:
一句话总结: 这篇论文提出了一个可解释和自适应的DDOS攻击检测框架
4. DESIGN
4.2 Explainability & Manual Intervention
4.2.1 Risk Profile
Risk Profile构成:
Risk Profile ∆ = (m, δ)是一个元组,其中:
- m是解释器给出的引起DDoS攻击的特征名称。(其实就是Feature-Attribution explanation,作者在下一段,通过说明如何寻找∆,介绍了解释器interpreter的工作原理)
- δ 是特征f_m需要改动的最小值,以使恶意流量变为良性流。换句话说,δ是f_m上从当前流量分布到KNN搜索空间中的合法流量分布的最短距离。
一个示例的Risk Profile 如下:

这表示受害者当前正遭受 ICMP 洪泛攻击,我们需要每五秒至少消除 8500 个入站 ICMP 数据包才能减轻攻击。
解释器工作原理:
给定一个被检测器D标记为DDoS攻击的traffic profile s(traffic profile其实就是流量特征向量……),为了计算intrusion profile ∆,文中的方法如下:
- 在D的KNN搜索空间中,寻找最近的良性traffic profile l
文中使用了宽度优先搜索(breadth-first search)。 - normalize s and l to ensure that features belonging to both profiles are directly comparable.
- 使用以下公式计算δ and m:

在少数情况下,解释器可能会给出多个risk profile,原因可能是:

4.2.2 Visualized KNN Model 可视化KNN模型
就这两段话,并没有说明方法
为了满足透明度要求并让网络管理员清楚地了解检测模型、网络上下文和检测逻辑,解释器除了检测结果之外还将可视化 KNN 检测模型。 由于训练和输入数据集通常是高维的,解释器将仅包含数据集的三个最重要的特征来绘制三维图。 此外,网络管理员还可以选择更改可视化功能,从不同方面检查情况。
这种可视化的 KNN 模型信息丰富。 通过可视化,网络管理员可以观察当前流量概况与良性和恶意群体的相对距离。 根据这些信息,网络管理员可以直观地了解检测逻辑、攻击严重程度和受害者状态。 我们在 5.3 节中进一步评估可视化 KNN 模型的可解释性。
4.2.3 Status Graph 状态图
为了便于网络管理员根据当前情况和缓解措施的成本效益快速做出决策,解释器会生成状态图,以简洁直观的方式表示攻击阶段、强度和警报的置信度。
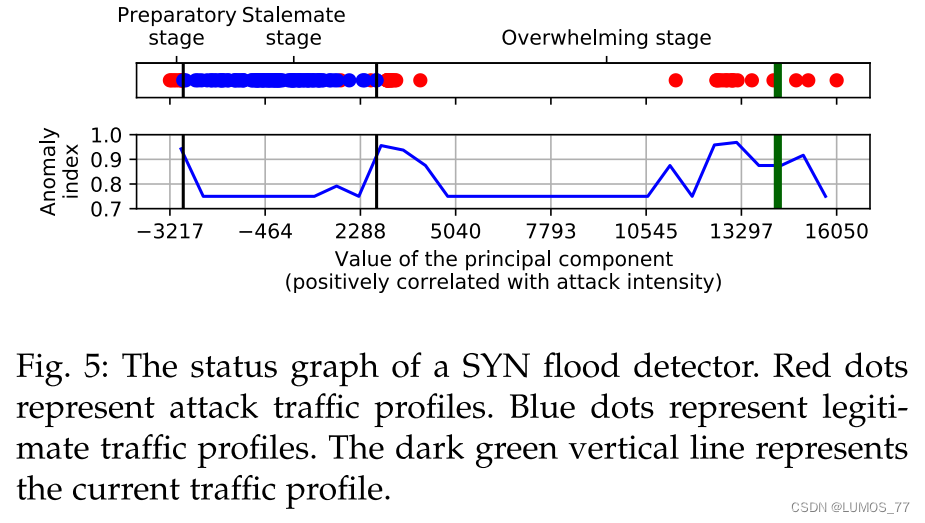
【SYN flood检测器的状态图。 红点代表攻击traffic profile。 蓝点代表合法的traffic profile。 深绿色垂直线代表当前的traffic profile。】
图 5 显示了状态图示例。 它由两个子图组成。上面那个使用PCA将训练和输入数据集映射到一维空间。















 3115
3115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









