







 本文介绍了一种名为TemporalFusionTransformers的模型,它在处理多水平时间序列预测时,提供了可解释性并保持先进性能。模型包括门控机制、变量选择网络、静态协变量编码器等组件,通过可解释的注意力机制理解和解释时间动态。应用实例展示了在不同领域的实际效果,如电力、交通、金融和股票预测。
本文介绍了一种名为TemporalFusionTransformers的模型,它在处理多水平时间序列预测时,提供了可解释性并保持先进性能。模型包括门控机制、变量选择网络、静态协变量编码器等组件,通过可解释的注意力机制理解和解释时间动态。应用实例展示了在不同领域的实际效果,如电力、交通、金融和股票预测。
论文出自:Temporal Fusion Transformers for interpretable multi-horizon time series forecasting
一、引出TFT模型
(一)最近的多水平预测深度学习方法
1. 迭代
除了要预测的变量均是已知变量。
TFT:划分成两类
(1)静态协变量(不随时间变化)
(2)时变变量(随时间变化):
1)过去观察到的 (如预测温度时,湿度,气压,风速等变量)
2)未来已知的(如,月份,星期,天,小时等)
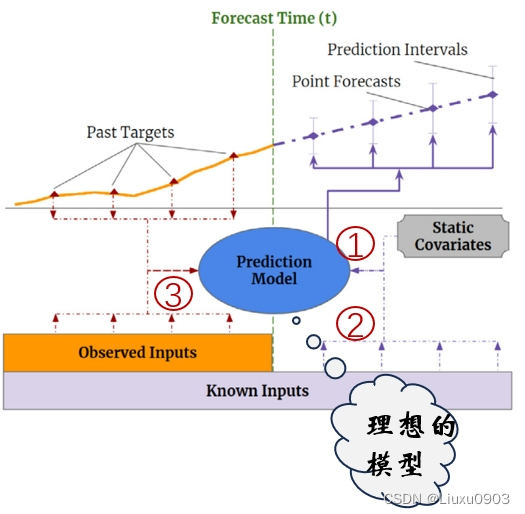
2. Sequence-to-Sequence 模型
在可解释性方面仍然具有挑战性。
TFT:可以提供有关时间动态的富有洞察力的解释,并同时在各种数据集上保持最先进的性能。
(二)基于注意力的时间序列可解释模型
没有考虑静态协变量的重要性,每个输入都是混合变量。(如,"Attention is all you need."用于翻译 ,"Residual attention network for image classification."用于图像分类)
TFT:通过在自注意力之上的每个时间步对静态特征使用单独的 encoder - decoder 注意力来确定随时间变化的输入贡献。从而缓解了这一问题。
(三)变量的重要性
事后解释方法,如:LIME,SHAP等。未考虑输入的时间顺序,限制了对复杂时间序列数据的使用。可解释建模方法用于特征选择的组件直接构建到架构中,根据每个注意力权重计算单个贡献系数。
TFT:能够分析全局时间关系,并允许用户解释模型在整个数据集上的全局行为。(能识别持续的季节或者滞后效应模式,也能识别某类现象发生的环境。)
二、模型架构
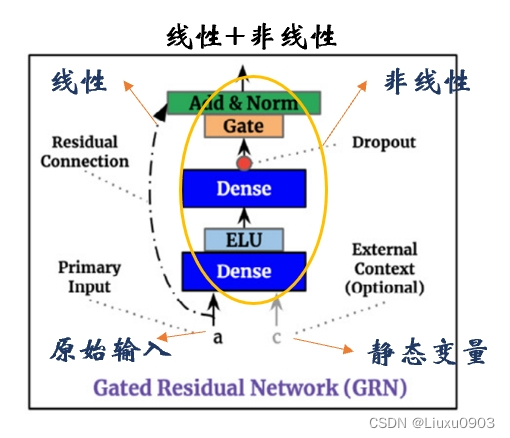
(一)门控机制 (Gating mechanisms)
可以跳过架构中任何未使用的组件,提供自适应深度和网络复杂性,可以应用于各种数据集和场景。
设计此模块的动机——想在需要的地方灵活地处理非线性特征
(1)输入变量与预测目标变量的确切关系往往事先未知,难以预测哪些变量是相关的。
(2)很难确定所需的非线性特征处理程度。
(3)在某些情况下,对更简单模型可能是有益的。(如,数据集小且有噪声)
TFT:在门控机制这里设计了 ELU 和 GLU
(1)ELU 指数线性单元激活函数,好处:输入负数时,也能产生常数的输出。 (对比 ReLU 对负值的响应为0)
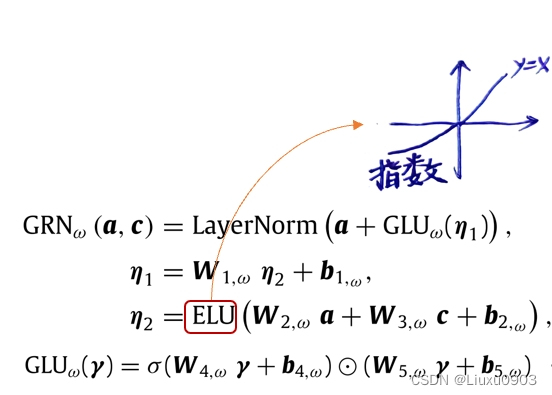
(2)GLU 对特定数据集能够抑制任何架构中不需要的部分。根据 GRU 对原始输入结果进行处理:
1)处理后的输出可能为0,用来抑制非线性特征。
2)如果在必要时,可能会完全跳过这一层。
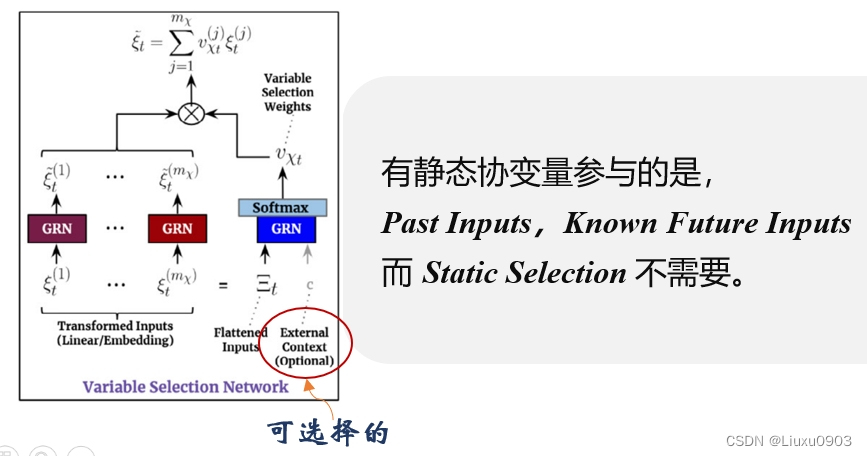
(二)变量选择网络 (Variable selection networks)
每个时间步选择相关的输入变量。现有的模型可能有多个输入变量,它们的相关性和对输出的具体贡献通常是未知的。
TFT:使用静态协变量和时间相关的时变变量来构建网络。
好处在于,可以预测出最重要的变量,还允许 TFT 删除任何对性能产生负面影响的不必要的噪声输入。(在大多数现实世界时间序列数据集,都含有预测内容较少的特征,因此变量选择网络可以仅利用最显著的特征去学习,极大的提高了模型的性能。)
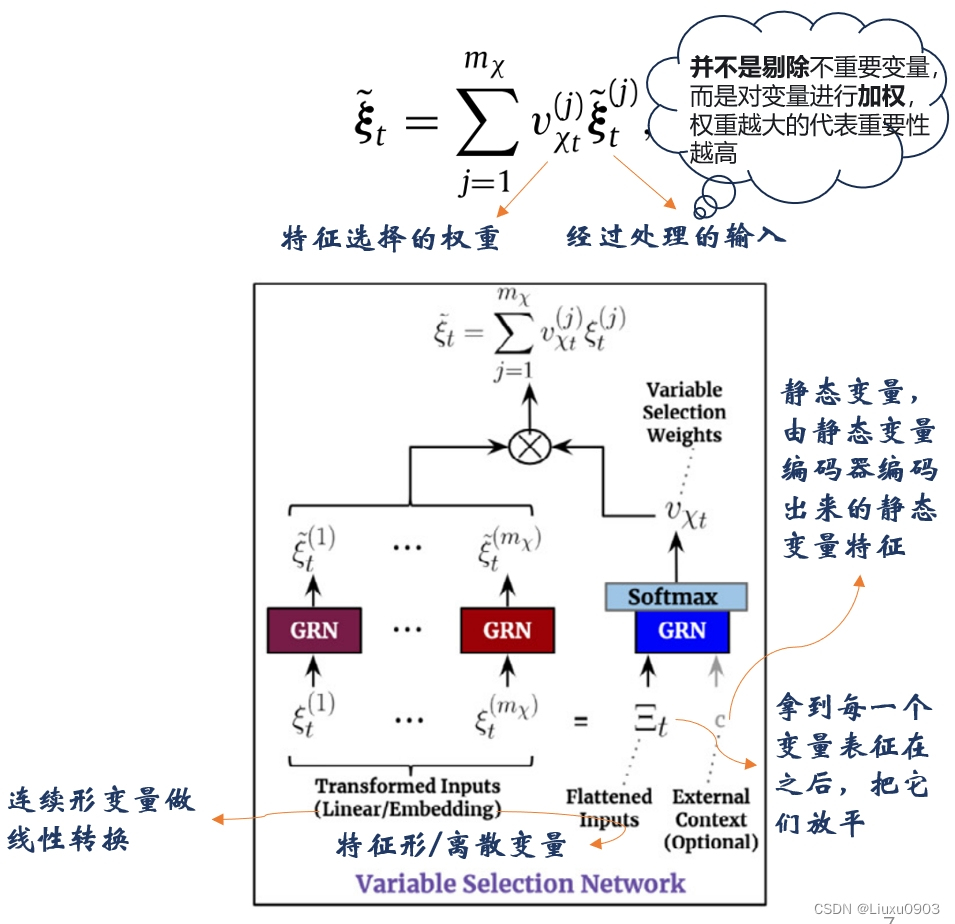
结构中的 c(表示静态协变量) 是可选的上下文向量。
(1)当时变变量输入时,c 需要参与学习
(2)当静态协变量输入时,c 丢弃,因为它本身可以访问静态信息。
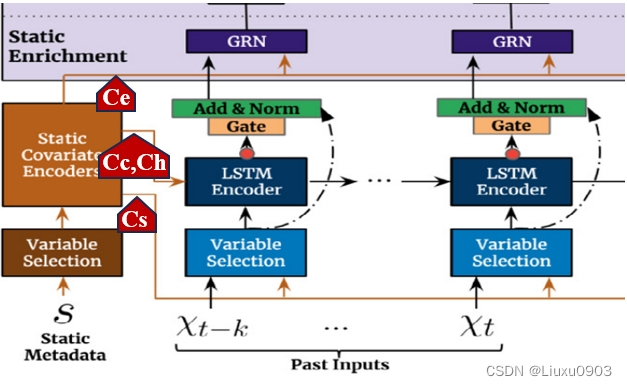
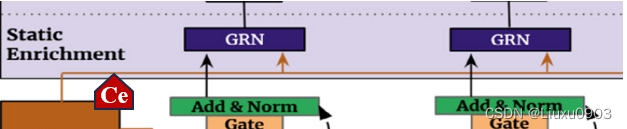
(三)静态协变量编码器 (Static covariate encoders)
静态特征集成到网络中,通过上下文向量编码来调节时间动态。
TFT:此模块是 TFT 精心设计,使用单独的 GRN 编码器,生成四个不同的上下文向量
Cs 时间变量选择
Cc,Ch 时间特征的局部处理
Ce 用静态信息丰富时间特征
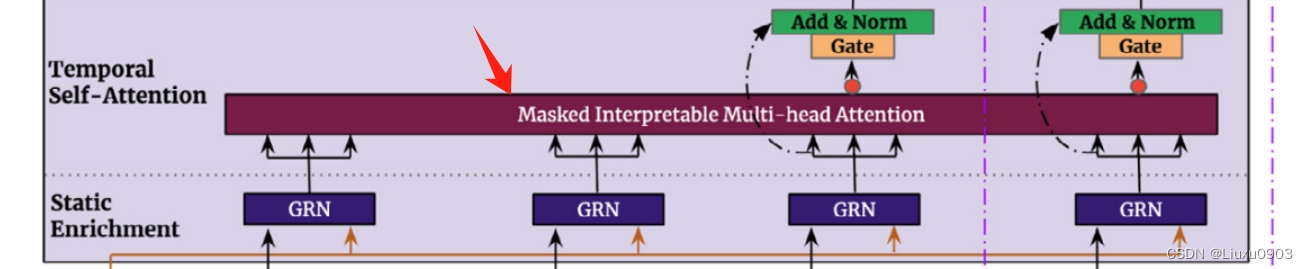
(四)可解释的多头注意力 (Interpretable multi-head attention)
采用自注意力机制来学习不同时间步长的长期关系,可解释的多头注意力与单独的注意力区别在于:生成注意力权重的办法。既能有效增加表示能力,又允许通过分析注意力权重来执行简单的可解释性研究。
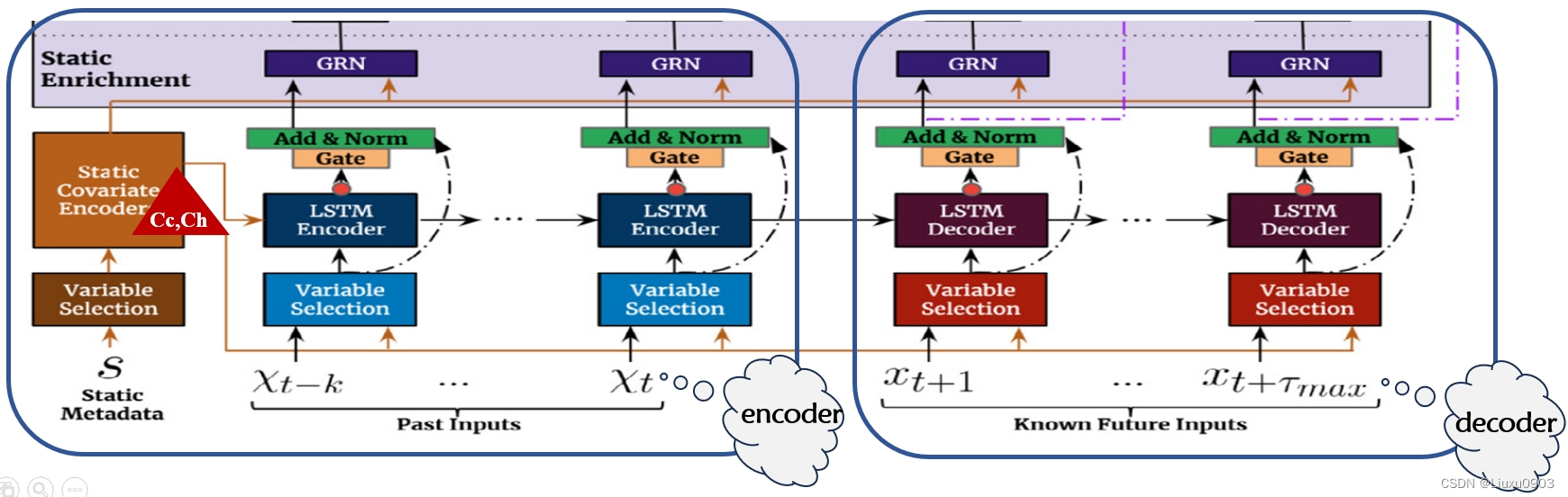
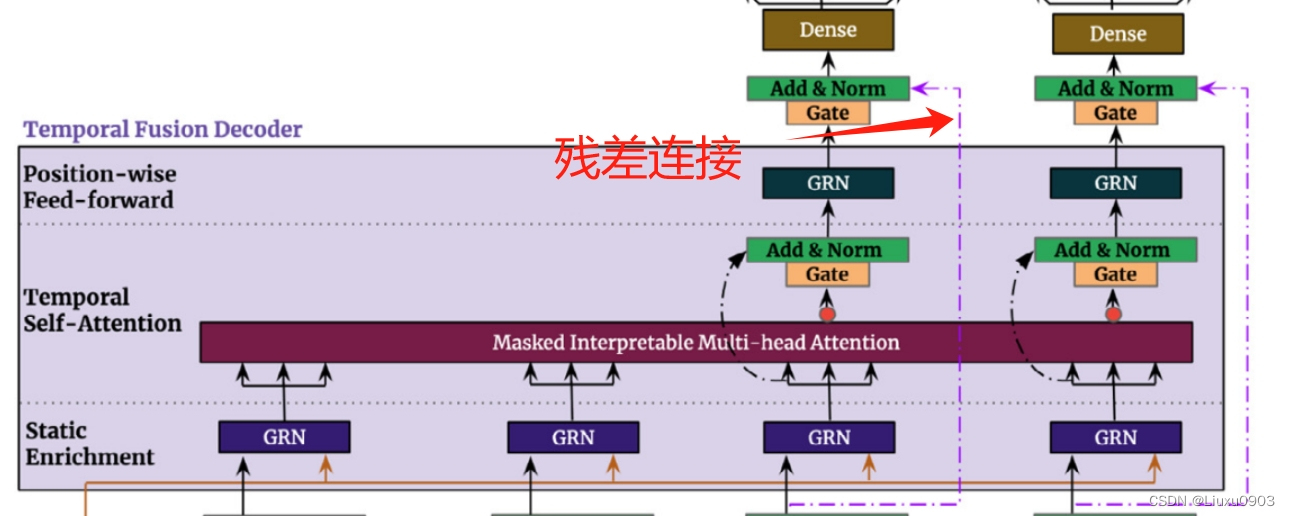
(五)时间融合解码器 (Temporal fusion decoder)
1. 用 Sequence-to-Sequence 局部增强 (Locality enhancement with sequence-to-sequence layer)
在时间序列数据中,重要点通常与它们周围的值相关,如异常,变化点,周期模式等。可以利用本地上下文,通过构造在逐点值之上利用模式信息的特性,可以提高基于注意力的体系结构性能。目前已有单个卷积层进行局域增强(在所有时间采取相同的滤波器提取局部模式)。但是,过去和未来输入数量不同时,之前的单个卷积层局域增强不适用。
TFT:使用 Sequence-to-Sequence ,把过去 k 个输入放入 encoder , 未来的 个输入放入 decoder 使用 LSTM 的 encoder-decoder => 使用静态协变量中的 Cc,Ch )然后生成统一时间特征,作为 Temporal fusion decoder 的输入。
多步预测公式:

2. 静态丰富层(Static enrichment layer)
静态协变量通常对时间动态有显著影响。(如,疾病的遗传信息)
TFT:使用静态协变量中的 Ce 来增强时间特征。
3. 时间自注意力层(Temporal self-attention layer)
(1)每个时间维度只能注意它之前的特征
(2)获取远程依赖关系

4. 位置前馈层(Position-wise feed-forward layer)
对时间自注意力层的输出使用 GRN 非线性处理,还使用了残差连接,可以跳过整个 transformer 模块,能加快训练收敛速度。
(六)分位数预测
为什么要使用分位数回归?采用分位数回归可以多视野预测。提供预测区间对优化决策和风险管理非常有用,因为它提供了确定每个预测层可能目标值范围的预测区间,目标可能采用的最佳和最坏情况值得预测。
TFT:通过每个时间步预测不同的百分位数(0.1,0.5,0.9)来实现的。
(七)损失函数
TFT:对所有分位数输出求和,最小化其分位数损失。
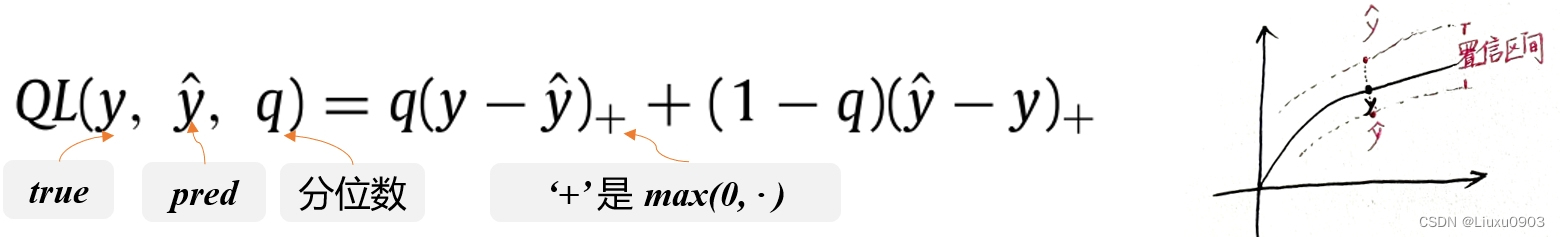
当 q =0.9 时:
y - y_pred > 0 时,即模型预测偏小,则 max(0.9 * (y - y_pred), 0.1 * (y_pred - y))=0.9 * (y - y_pred),loss 的增加更多。
y - y_pred < 0 时,即模型预测偏大,则 max(0.9 * (y - y_pred), 0.1 * (y_pred - y))= 0.1 * (y_pred - y),loss 的增加更少。
三、可解释性用例
使用数据集有,电力,交通,金融和股票。
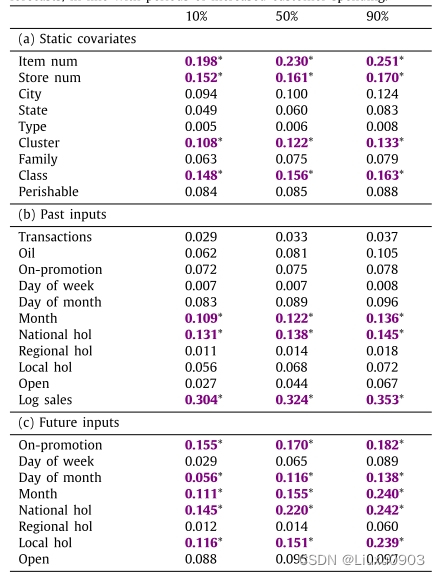
(一)检查预测中每个输入变量的重要性
以零售为例,0.1,0.5,0.9分位数的变量选择权重。
1. 对于静态变量,最大权重是项目编号和存储编号(唯一标识不同实体的变量)
2. 过去的输入,最大权重是对数销售(过去的目标值)
3. 未来的输入,最大权重是促销期和国家法定假日(与实际用户消费增加时期一致)
(二)可视化持久的时间模式
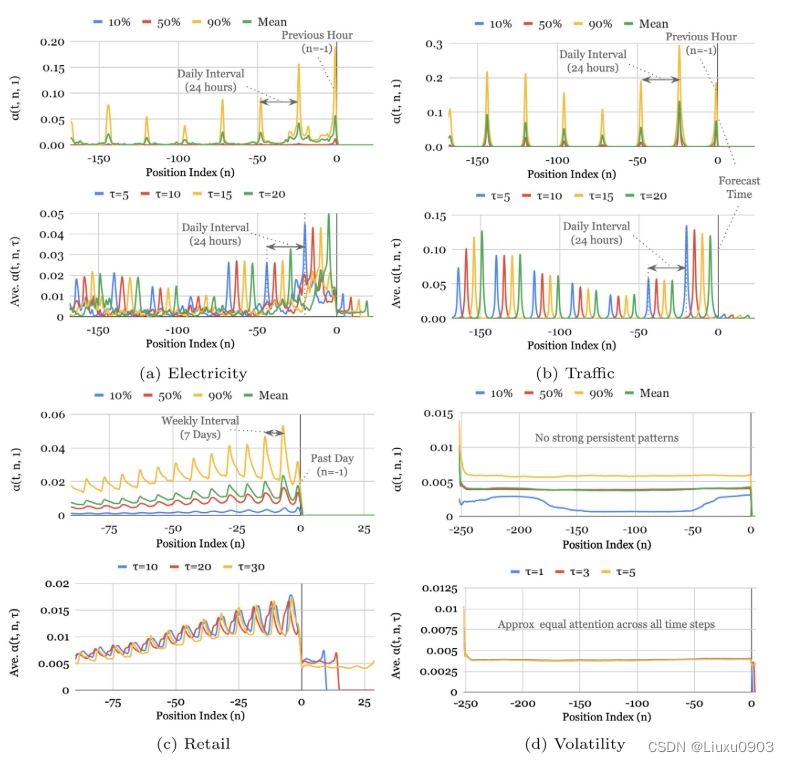
在所有数据集的注意力权重分析(0.1,0.5,0.9 分位数的平均值注意力权重,上面的图绘制了在测试集上提前一步预测,下面的图绘制了多步预测(=5,10,15,20))
1. 电力和交通数据集上观察到每日间隔峰值,零售数据集上有相对较弱的每周峰值并且最近几天的重要性占主导地位。而股票数据集上没有明显的周期性峰值。
2. 可以通过对比模块来改进模型,如:数据收集,特征筛选。
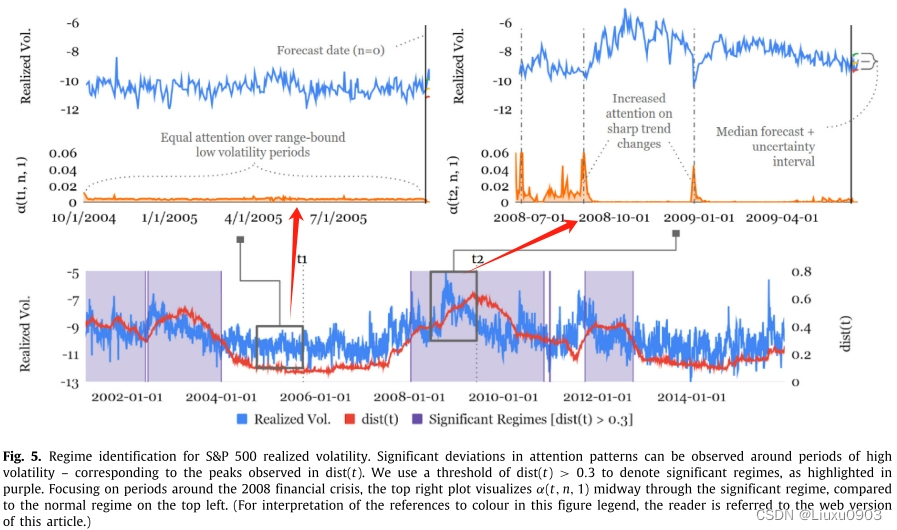
(三)识别导致时间动态显著变化的任何制度或事件
由于重大的制度或者事件存在,可能会发生暂时变化。(如金融市场在制度转换时,特征的有波动性=>特征会随着制度变化而变化)
1. 当波动性低时,对过去输入给予同等关注。
2. 当波动性高时,更多地关注急剧变化(如,2008年金融危机前后时期,左上图的注意力相同,右上图注意力由于特征突然变化而增加)


















 1080
1080

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









