







arXiv: https://arxiv.org/pdf/1603.06937v2.pdf
github: https://github.com/anewell/pose-hg-train
What:
人体关键点预测,输入人体图像输出几个关键点。
使用了反复迭代bottom down/ top down 这个策略在人脸landmark 甚至更早像ASM就有,反复迭代来更精确。
但在CNN上具体是怎么操作的呢?(文题中的hourglass沙漏就是指结构像沙漏一样吧)
How:
1. 基本块
他们使用residual 作为基本网络结构

1*1 的卷积降维256->128 ,3*3 的卷积,1*1的卷积升维128->256
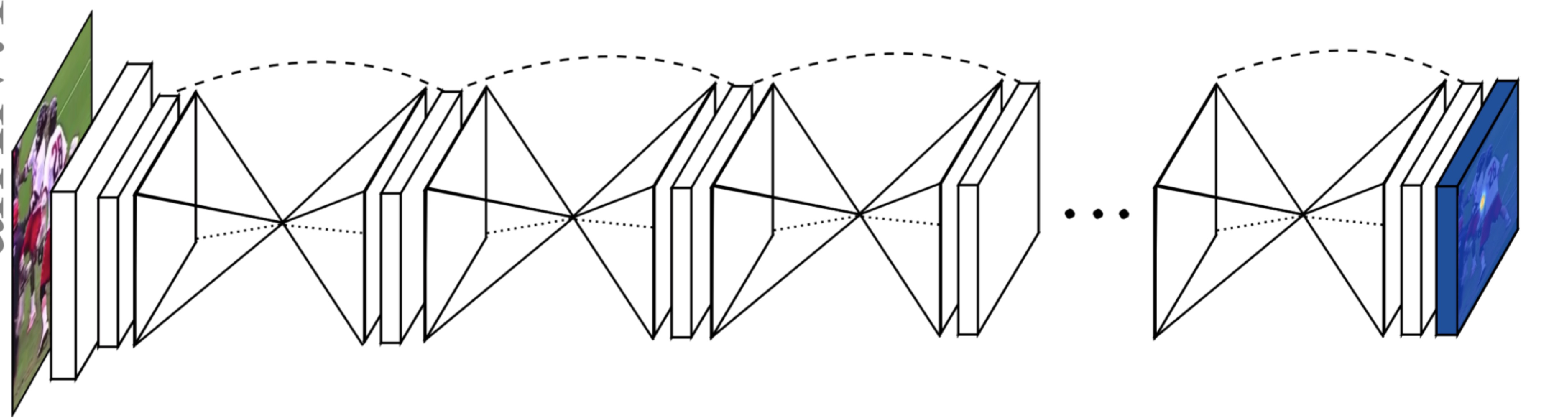
2. 单个沙漏网络的拓扑结构是对称的,结构类似fully convolutional network for semantic segmentation,(语义分割的那篇CVPR paper)
最终一共使用了8个沙漏网络。每个沙漏网络的输入都为 64*64. (输入图片大小为256*256,一开始经过一次7*7 stride2 的conv 和一次 maxpooling 变成64)
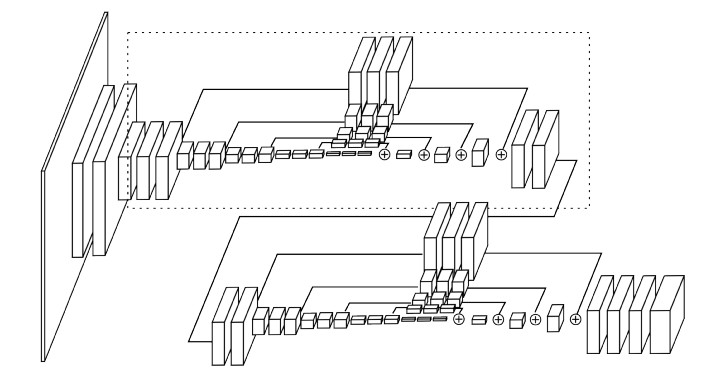
3.如上图,在每次pooling之后都会有1个basic building block 加到之后 upsampling中相同大小的map中。
(这里可以看出每个pooling前的feature map都是256 channel的,up sampling的时候也是256 channel的)
4. 使用了中层监督,对前几个沙漏网络也有loss,这和训练深层res net/inception net一样。而loss的方法如下图
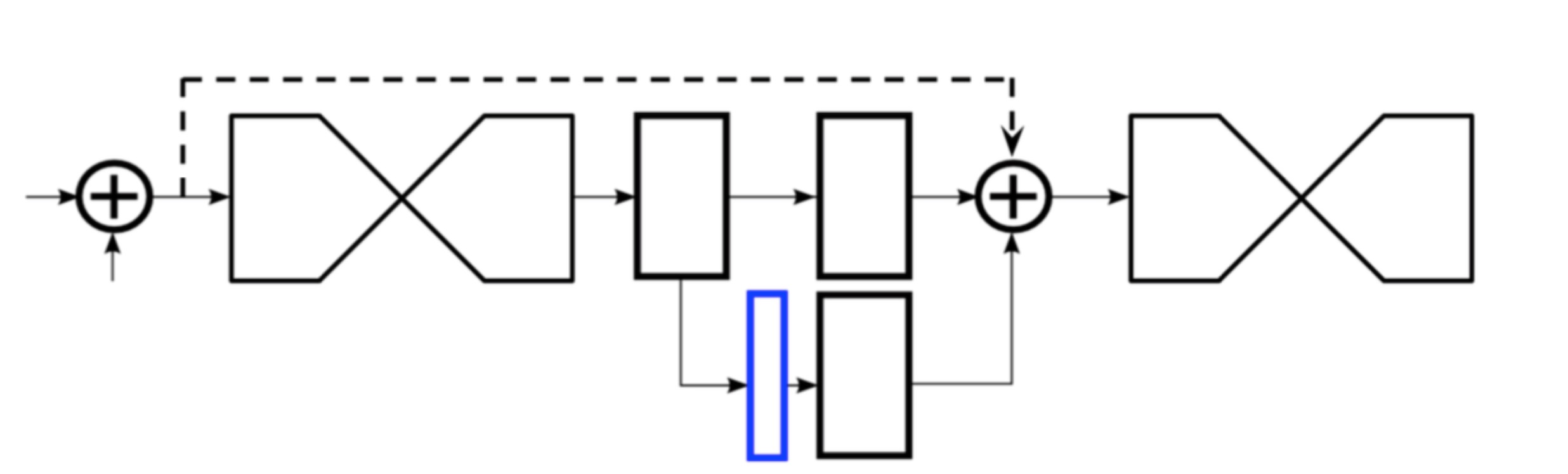
蓝色是prediction(这里有map的 regression Loss),有一路直传,一路从上一个沙漏网络来,三路加到一起传到下一个沙漏
















 1005
1005

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











