






1.1 芯片验证概述
测试平台:对DUT创建测试序列、观察DUT的输入输出、对DUT的输出数据与预期数据进行对比、报告检查结果。
芯片开发流程:用户需求->设计结构和产品描述->系统设计->模块功能详述->硬件设计->硬件描述语言文件->功能验证->验证环境文件->后端综合->芯片产品。
只有经过充分量化验证才能有足够的信心去流片。
1.2 SystemVerilog概述
SystemVerilog是Verilog标准的扩展,旨在通过一种统一的语言来帮助工程师对大型复杂硬件系统进行建模,并且对其功能进行验证。
1.3 数据类型
SV将硬件信号分为“类型”和“数据类型”。
类型:变量(variables、可以使用连续赋值或者过程赋值),线网类型(wire、只能使用连续赋值语句assign)
数据类型:四值逻辑(logic)、二值逻辑(bit)。
四值逻辑类型:logic、integer、reg、wire
二值逻辑类型:bit、byte、shortint、int、longint
无符号类型:logic、bit构成的向量(vector)、reg、wire
有符号类型(加上unsigned变为无符号类型):integer、byte、shortint、int、longint
1.4 自定义类型
通过typedef创建用户自定义类型
通过enum创建枚举类型
通过struct创建结构体类型
1.5 字符串类型
SV引入string类型用来容纳可变长度的字符串,存储单元为byte,长度为N时,索引值从0到N-1,结尾没有null字符。
str.len():返回字符串的长度
str.putc(i,c):将第i个字符替换成字符c,等同于str[i]=c
str.getc(i):返回第i个字符
str.substr(i,j):将从第i个字符到第j个字符的字符串返回
str.{atoi(),atohex(),atooct,atobin}:将字符串转变为十进制、十六进制、八进制、二进制数据
1.6设计特性
添加接口(interface)从而将通信和协议检查进一步封装
添加always_comb(组合逻辑)、always_latch(锁存逻辑)、always_ff(时序逻辑)等过程语句块
添加priority(可重复、按优先级选择)和unique(不可重复) case语句
1.7 接口
SV在Verilog语言基础上扩展了接口(interface),提供一种新型的对抽象级建模的方式,可以简化建模和验证大型复杂设计
Interface允许多个信号被整合到一起来表示一个单一的抽象端口,多个模块可以使用同一个interface避免多个分散的端口信号连接
接口可以包含变量或者线网,封装模块之间的通信协议,还可以嵌入与协议有关的断言检查、功能覆盖率收集等
接口不同于模块的地方在于接口不允许包含设计层次,即接口不能例化module,但是接口可以例化接口
接口可以进一步声明modport来约束不同模块连接时信号方向
2.1 验证环境结构
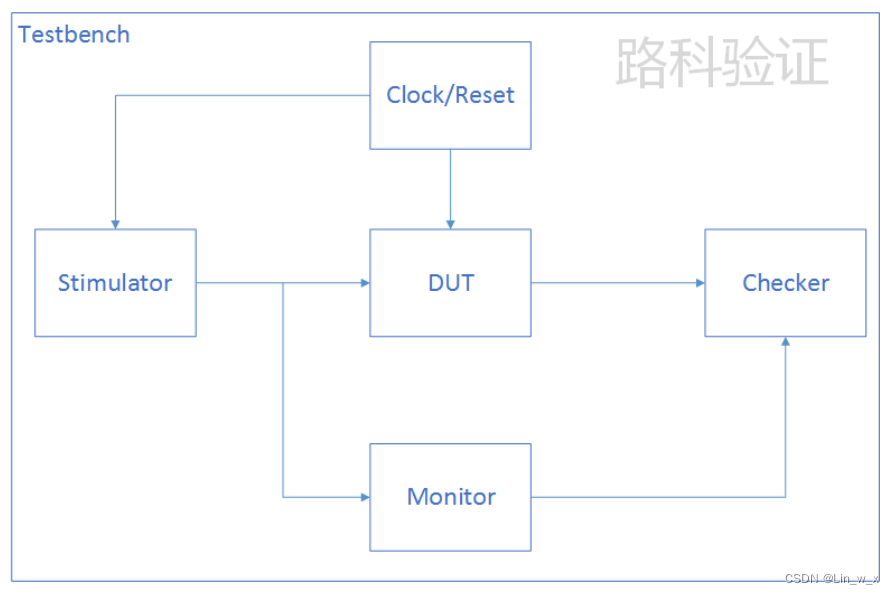
测试平台是整个验证系统的总称,包括各个组件、组件之间的连接关系、测试平台的配置和控制,还包括编译仿真的流程、结果分析报告和覆盖率检查等。
各个组件之间相互独立、验证组件与设计之间需要连接、验证组件之间也需要通信、验证环境也需要时钟和复位信号的驱动。
2.2 验证环境组件
Stimulator的主要职责是模拟与DUT相邻设计的接口协议,只需要关注于如何模拟接口信号,使其能够以真实的接口协议来发送激励给DUT,不应该违反协议,但不拘束于真实的硬件行为,比真实硬件行为更丰富的激励,接口主要同DUT之间连接,可以有其它配置接口,也可以有存储接口数据生成历史的功能。
Monitor的主要功能用来观察DUT的边界信号或者内部信号(尽量少),并且结果打包整理传送给其他验证平台的组件(Checker比较器)。
Checker负责模拟设计行为和功能检查的任务,将DUT输入接口数据汇集给内置的reference model(参考模型),通过数据比较检查DUT功能。
2.3 任务和函数
函数function:
不会消耗仿真时间,无法调用task,可以调用function,可以返回一个单一数据或者不返回,可以作为一个表达式中的操作数
任务task:
会消耗仿真时间,可以调用function和task,不会返回数值
参数传递:input、output、inout属于值传递,只发生在方法的调用和返回时;ref属于指针传递;添加const修饰符变为只读变量。可以有默认参数。
2.4 数组
非组合型数组:int a[7:0][1023:0]; 8\*1024
组合型数组:int [3:0][7:0] a; 4\*8
混合型数组,先看右边,再看左边。如:int[1:0][2:0] arr[3:0][4:0];的维度是4*5*2*3。
初始化:
- 组合型:
logic [3:0][7:0] a = 32’h0;同向量初始化一致; - 非组合型:
int d[0:1][0:3] = ‘{‘{7,3,0,5},’{2,0,1,6}};需要通过’{}来对数组的每一个维度进行赋值。
赋值:
- 非组合型:
byte a[0:3][0:3]; a[3] = ‘{‘hF, ‘hA ,’hC, ‘hE};a[1][0] = 8’h5; - 组合型:
logic[1:0][1:0][7:0] a;a=32'hF1A3C5E7;a[1][1][0]=1'b0;a[1][0][3:0]=4'hF;
拷贝:
- 组合型数组:当位数、维度不一致时自动扩展
- 非组合型数组:维度、大小必须严格一致
- 组合型与非组合型数组无法直接相互赋值
动态数组:一开始为空,使用new[]来为其分配空间,有delete、size等内置函数
int d[];
d=new[5];
d=new[20](d);\\分配20个空间并且前五个空间进行拷贝
d=new[100];\\分配100个空间,之前20个空间丢失、
d.delete();
队列:使用[$]关键字,int q[$] = {3,4};,有insert、push_back、push_front、pop_buck、pop_front等内置函数
关联数组:索引值可以为任意类型,不连续的值等
定位方法:返回值为队列,有min、max、unique等,也可以用foreach
2.5 类的封装
类(class):包含成员变量和成员方法。
对象(object):类在例化后的实例。
句柄(handle):指向对象的指针。
原型(prototype):程序的声明部分,包含程序名、返回类型和参数列表
成员默认都是public,有私有的local(只有类里面才能访问),受保护的protected(只有类以及子类里面才能访问)
2.6 类的继承
使用关键字 extends 继承父类的所有成员(变量和方法)。
class packet;
integer i = 1;
function new(int val);
i = val + 1;
endfunction
function shift();
i << 1;
endfunction
endclass
class linkedpacked extends packet;
// integer i = 3;
function new(int val);
super.new(val);//子类必须要继承父类的new函数
if(val >= 2)
i = val;
endfunction
function shift();
// super.shift();
i << 2;
endfunction
endclass
module tb;
initial begin
packet p = new(3);
linkedpacked lp = new(1);
//packet tmp;
//tem = p;
$display("p.i = %0d", p.i);//4
$display("lp.i = %0d", lp.i);//2,会先进入父类的new在调用自己的new
p.shift();
$display("after shift, p.i = %0d", p.i);//8
lp.shift();
$display("after shift, lp.i = %0d", lp.i);//8,不会进入父类的shift
//$display("tem.i = %0d", tem.i);
end
endmodule
- 子类在创建的时候必须先执行父类的new(),也就是子类在new的时候一定会调用父类的new。
- 如果子类中声明了与父类同名的成员(变量和方法),那么子类中对其同名成员的访问都将指向子类,而父类的成员将被隐藏。
- super用来访问当前对象其父类的成员(变量和方法)。如果子类成员与父类成员同名,需要使用super来指定访问父类的成员。
2.7 包的使用
Package里面只能有软件(类里面的一些类、变量、方法、结构体、枚举)的部分,module属于硬件的部分。Interface也不能在package中,interface介于软件和硬件之间。
通过域的索引号::直接引用,通过通配符*将包中的所有类导入到指定容器中。
package pkg_a;
class packet_a;
int pkg_a_a;
endclass
typedef struct{
int data;
int command;
} struct_a;
int va = 1;
endpackage
package pkg_b;
class packet_b;
int pkg_b_b;
endclass
typedef struct{
int data;
int command;
} struct_b;
int vb = 2;
endpackage
module mod_a;
endmodule
module mod_b;
endmodule
module tb;
class packet_tb;
endclass
typedef struct{
int data;
int command;
} struct_tb;
class packet_a;
int tb_a;
endclass
class packet_b;
int tb_b;
endclass
mod_a ma();//可以识别
mod_b mb();
//添加import可以省去作用域的麻烦
//import pkg_a::packet_a;
//import pkg_a::va;
import pkg_a::*;
import pkg_b::*;
initial begin
//packet_a pta = new();//module里面没有packet_a时,没有import出错,无法识别packet_a和packet_b
//packet_b ptb = new();
//pkg_a::packet_a pta = new();//module里面没有packet_a时,没有import不会出错
//pkg_b::packet_b ptb = new();
//packet_a pta = new();//module里面没有packet_a时,有import不会出错
//packet_b ptb = new();
packet_a pta = new();//module里面有packet_a时先找到自己的,没有的时候再去找packet的
packet_b ptb = new();
packet_tb mptb = new();
//$display("pkg_a::va = %0d , pkg_b::vb = %0d", pkg_a::va, pkg_b::vb);
$display("pkg_a::va = %0d , pkg_b::vb = %0d", va, vb);
end
endmodule
3.1 随机约束
用系统函数std::randomize()可以产生随机数。
$urandom(),可以产生一个32位的无符号随机数。
$urandom_range(maxval, minval=0),可以产生maxval和minval之间的随机数。
**在面向DUT的随机激励发生过程中,为了符合协议、满足测试需求,我们需要添加一些“约束”。**使变量随着希望的变化方向去随机。用类来作为“载体”来容纳这些变量以及它们之间的约束,可将类的成员变量声明为“随机”属性,用rand和randc来表示。
任何类中的整型变量都可以声明为随机的,定长数组、动态数组、关联数组和队列都可以声明为rand/randc,可以对动态数组和队列的长度加以约束。指向对象的句柄也可以声明为rand(不可以为randc),随机时该句柄指向对象中的随机变量也会一并被随机。
- rand在随机化的时候每次的取值的概率是一样的
- randc在随机化的时候会在取值范围内先将所有取值遍历一遍后再开始下一轮,即如果取值范围为0-9,若第一次取2,则接下来的9次取值不会取到2。c 的含义是 cycle。
rand bit [7:0] len;
rand integer data[1];
constraint db { data.size == len; }
class packet;
rand bit [31:0] src, dst, data[4];
rand bit [7:0] kind;
constraint cstr {
src > 10;
src < 15;
}
function print();
$display(" src is %0d\n dst is %0d\n data is %p\n kind is %0d", src, dst, data, kind);
endfunction
endclass
module tb;
packet p;
initial begin
p = new();
$display("before randomize");
p.print();
p.randomize();
$display("after randomize");
p.print();
end
endmodule
typedef struct{
rand bit [31:0] src;
rand bit [31:0] dst;
rand bit [31:0] data[4];
rand bit [7:0] kind;
} packet_t;
module tb2;
packet_t pkt;
initial begin
$display("before randomize");
$display(" src is %0d\n dst is %0d\n data is %p\n kind is %0d", pkt.src, pkt.dst, pkt.data, pkt.kind);
//添加临时约束 in-line/dynamic/temporary constraint
std::randomize(pkt) with { pkt.src > 10; pkt.src < 15; };
$display(" src is %0d\n dst is %0d\n data is %p\n kind is %0d", pkt.src, pkt.dst, pkt.data, pkt.kind);
end
endmodule
module tb3;
bit [31:0] src;
bit [31:0] dst;
bit [31:0] data[4];
bit [7:0] kind;
initial begin
$display("before randomize");
$display(" src is %0d\n dst is %0d\n data is %p\n kind is %0d", src, dst, data, kind);
std::randomize(src, dst, data, kind);
$display(" src is %0d\n dst is %0d\n data is %p\n kind is %0d", src, dst, data, kind);
end
endmodule
class packet2;
rand packet_t pkt;//结构体也可以随机
function print();
$display(" src is %0d\n dst is %0d\n data is %p\n kind is %0d", pkt.src, pkt.dst, pkt.data, pkt.kind);
endfunction
endclass
module tb4;
packet2 p;
initial begin
p = new();
$display("before randomize");
p.print();
p.randomize();
$display("after randomize");
p.print();
end
endmodule
约束块一般用类来实现,可以是一些随机的取值也可以为变量之间的关系。
rand integer x,y,z;
constraint c1 {x inside {3, 5, [9:15], [24:32], [y:2*y], z};}
rand integer a,b,c;
constraint c2 {a inside {b, c};}
integer fives[4] = '{5, 10, 15, 20 };
rand integer v;
constraint c3 {v inside {fives};}
也可以加上权重发布:①:=操作符,表示每一个值的权重是相同的;②\=操作符,表示权重会平均分配到每个值。
x dist {[100:102] := 1, 200 := 2, 300 := 5}//100,101,102,200,500分别为1-1-1-2-5
x dist {[100:102] :/ 1, 200 := 2, 300 := 5}//100,101,102,200,500分别为1/3-1/3-1/3-2-5
unique可以用来约束一组变量,在随机化之后变量之间的取值不会一样。
//b,a[2],a[3],excluded在随机化后将包含不同的取值
constraint u {unique {b, a[2:3], excluded};}
条件约束,可以使用if-else或者->操作符来表示条件约束
mode == little -> len < 10;
mode == big -> len > 100;
bit [3:0] a,b;
constraint c {(a == 0) -> (b == 1);}
if(mode == little)
len < 10;
else if(mode == big)
len > 100;
迭代约束,foreach可以用来迭代约束数组(定长、动态、关联数组,队列)中的元素
class c;
rand byte A[];
constraint c1 {foreach (A[i]) A[i] inside {2,4,8,16}; }
constraint c2 {foreach (A[j]) A[j] > 2 * j; }
end class
module tb5;
class packet;
rand byte arr[];
constraint cstr {
foreach(arr[i]) arr[i] inside {2, 4, 8, 16};
foreach(arr[i]) arr[i] > 2 * i;
arr.size() < 8;
}
endclass
initial begin
packet p = new();
repeat(10) begin
if(p.randomize()) $display("arr size is %d ,data is %p", p.arr.size(), p.arr);
else $error("randomize failure!");
end
end
endmodule
约束里面也可以使用函数
软约束(soft),可以用来指定变量的默认值和权重,若在外部做二次约束时,硬约束会覆盖掉软约束,并且不会导致随机数产生失败。
module tb6;
class packet_a;
rand int length;
constraint cstr {soft length inside {[5:15]};}
endclass
class packet_b extends packet_a;
//constraint cstr{ length inside {[10:20]};}//与父类同名会覆盖掉packet_a的约束
//constraint cstr1 { length inside {[10:20]};}//不同名同时满足packet_a的约束
//constraint cstr2 { length inside {[16:20]};}//满足硬约束
constraint cstr2 {soft length inside {[16:25]};}//满足就近约束
endclass
initial begin
packet_b pkt = new();
repeat(10) begin
if(pkt.randomize() with {soft length inside {[26:30]};}) $display("pkt.length is %d", pkt.length);
else $error("randomize failure!");
end
end
endmodule
模糊指向,使用local::和this来指定约束的指向。
module tb7;
class packet1;
rand bit[7:0] x;
constraint cstr {soft x == 5;}
endclass
class packet2;
bit[7:0] x = 10;
function int get_rand_x(input bit[7:0] x = 20);
packet1 pkt = new();
//pkt.randomize with {x == x;};//默认为5
//pkt.randomize with {x == local::x;};//30,为传进来的值
pkt.randomize() with {x == local::this.x;};//10,当前类中的值
return pkt.x;
endfunction
endclass
initial begin
packet2 pkt = new();
$display("pkt.x = %0d", pkt.get_rand_x(30));
end
endmodule
随机控制,使用rand_mode()来禁止随机化,使随机变量不参与到随机化中。p.rand_mode(0)禁止类中所有的随机变量参与到随机化中,p.value.rand_mode(1)将类中的指定变量解除禁止参与到随机化中。
约束控制,使用constraint()来禁止约束使用,用法同随机控制。
3.2 线程控制
fork join相当于begin end,此外还有fork join_any和fork join_none。

- join:所有子线程执行结束再继续执行
- join_any:任何一个线程结束就继续执行
- join_none:不会等待子线程就直接继续执行
`timescale 1ns/1ps
module tb;
task automatic exec(int id, int t);
$display("@%t exec[%0d] entered", $time, id);
#(t*1ns);
$display("@%t exec[%0d] exited", $time, id);
endtask
//initial 之间并行
initial begin
exec(1, 10);
end
initial begin
exec(2, 20);
end
initial begin
exec(3, 30);
end
initial begin
exec(4, 40);
end
endmodule
module tb1;
task automatic exec(int id, int t);
$display("@%t exec[%0d] entered", $time, id);
#(t*1ns);
$display("@%t exec[%0d] exited", $time, id);
endtask
//initial 内部串行
initial begin
exec(1, 10);
exec(2, 20);
exec(3, 30);
exec(4, 40);
end
endmodule
module tb2;
task automatic exec(int id, int t);
$display("@%t exec[%0d] entered", $time, id);
#(t*1ns);
$display("@%t exec[%0d] exited", $time, id);
endtask
initial begin
//使用 fork join 并行
fork
exec(1, 10);
exec(2, 20);
exec(3, 30);
exec(4, 40);
join
end
endmodule
module tb3;
task automatic exec(int id, int t);
$display("@%t exec[%0d] entered", $time, id);
#(t*1ns);
$display("@%t exec[%0d] exited", $time, id);
endtask
initial begin
//使用 fork join_any/join_none 并行
$display("@%t fork join_any entered", $time);
fork
exec(1, 10);
exec(2, 20);
join_any
$display("@%t fork join_any exited", $time);
$display("@%t fork join_none entered", $time);
fork
exec(3, 30);
exec(4, 40);
join_none
$display("@%t fork join_none exited", $time);
wait fork;//等待fork结束再继续执行
disable fork;//直接结束fork继续执行
$display("@%t ini_proc1 exited", $time);//无wait 10000,有wait 50000,有disable 10000
end
endmodule
时序控制使用延迟控制或者事件等待来完成时序控制。
#使用延迟控制:#10 x = y ;- 事件(event)控制使用
@来完成:@r x = y; @(posedge clock) x = y; wait语句可以与事件或者表达式结合:
3.3 线程间同步与通信
3.3.1 事件(event)
触发事件用->。
`timescale 1ns/1ps
module tb;
event e1, e2, e3;
task automatic wait_event(event e, string name);
$display("@%t start waiting event %s", $time, name);
@e;//等待事件@
$display("@%t finist waiting event %s", $time, name);
endtask
initial begin
fork
wait_event(e1, "e1");
wait_event(e2, "e2");
wait_event(e3, "e3");
join
end
initial begin
fork
begin #10ns -> e1; end//触发事件 ->
begin #20ns -> e2; end
begin #30ns -> e3; end
join
end
endmodule
等待信号的时候要用ref
module tb2;
bit e1, e2, e3;
task automatic wait_event(ref bit e, input string name);
$display("@%t start waiting event %s", $time, name);
@e;
$display("@%t finist waiting event %s", $time, name);
endtask
initial begin
fork
wait_event(e1, "e1");
wait_event(e2, "e2");
wait_event(e3, "e3");
join
end
initial begin
$display("before fork, e1 = %0d", e1);
fork
begin #10ns e1 = !e1; end
begin #20ns e2 = !e2; end
begin #30ns e3 = !e3; end
join
$display("after fork, e1 = %0d", e1);
end
endmodule
等待事件
@:边沿触发wait():电平触发wait_order(a,b,c):按顺序触发,事件从左到右依次完成
3.3.2 旗语(semaphore)
- 旗语在创建的时候会为其分配固定的钥匙数量
- 使用旗语的进程必须要先获得钥匙才可以继续执行
- 旗语钥匙的数量可以有多个,等待旗语钥匙的进程也可以同时有多个
- 常用于互斥,对共享资源的访问控制
创建旗语:semaphore sm; sm = new(N=0),new括号里面的数字就是旗语钥匙的数量。
从旗语获取一个或多个钥匙(阻塞型):get(N=1),将钥匙归还:put(N=1)
尝试获取一个或多个钥匙而不会被阻塞(非阻塞型):try_get(N=1),可以拿到正常执行,没有拿到返回0。
旗语的等待遵循先进先出(FIFO)。
`timescale 1ns/1ns
module tb;
semaphore mem_acc_key;
int unsigned mem[int unsigned];
task automatic write(int unsigned addr, int unsigned data);
mem_acc_key.get();
#1ns
mem[addr] = data;
mem_acc_key.put();
endtask
task automatic read(int unsigned addr, output int unsigned data);
mem_acc_key.get();
#1ns
if(mem.exists(addr))
data = mem[addr];
else
data = 'x;
mem_acc_key.put();
endtask
initial begin
int unsigned data = 100;
mem_acc_key = new(1);
forever begin
fork
begin
#10ns;
write('h10, data+100);
$display("@%t write with data %d",$time,data);
end
begin
#10ns;
read('h10, data);
$display("@%t read with data %d",$time,data);
end
join
end
end
endmodule
3.3.3 信箱(mailbox)
信箱相当于FIFO来使用。当信箱写满时,后续写入的动作被挂起,直到信箱有空间才可以继续写入。
- 创建信箱:
new(int count = 0),可以限定大小,如果不传入参数,默认为不限定大小 - 将信息写入信箱:
put() - 试着写入信箱但不会阻塞:
try_put() - 获取信息:
get()同时会取出数据,peek()不会取出数据 - 试着取出数据但不会阻塞:
try_get()\try_peek() - 获取信箱信息的数目:
num()
module tb;
mailbox #(int) mb;//可以指定信箱中的数据类型是int
initial begin
int data;
mb = new(8);
forever begin
case ($urandom() % 2)
0 : begin
if(mb.num() < 8) begin
data = $urandom_range(0, 10);
mb.put(data);
$display("mb put data %0d", data);
end
end
1 : begin
if(mb.num() > 0) begin
mb.get(data);
$display("mb get data %0d", data);
end
end
endcase
end
end
endmodule
3.4 虚方法(多态)
在父类和子类中声明的虚方法,其方法名、参数名、参数方向等都应该保持一致。
在调用虚方法时,它将调用句柄指向对象的方法,而不受句柄类型的影响。
在父类方法前添加关键字virtual,子类可以不声明virtual。
module tb;
class BasePacket;
int A = 1;
int B =2 ;
function void printA;
$display ( "BasePacket: :A is %d",A);endfunction : printA
virtual function void printB;
$display ( "BasePacket: :B is %d",B);endfunction : printB
endclass : BasePacket
class My_Packet extends BasePacket;
int A = 3;
int B = 4 ;
function void printA;
$display ( "My_Packet: :A is %d", A);
endfunction : printA
virtual function void printB;
$display("My_Packet: :B is %d",B);
endfunction : printB
endclass : My_Packet
BasePacket P1 = new;
My_Packet P2 = new;
initial begin
P1.printA; // displays 'BasePacket: :A is 1'
P1.printB; // displays 'BasePacket: :B is 2'
P1 = P2; // P1 has a handle to a My_packet object
P1.printA; // displays 'BasePacket: :A is 1'
P1.printB;// displays 'My _Packet::B is 4 ' latest derived method
P2.printA; // displays 'My_Packet: :A is 3'
P2.printB; // displays 'My_Packet: :B is 4'
end
endmodule
3.5 类型转换
静态转换:Verilog对整数和实数类型,或者不同位宽的向量之间进行隐式转换。转换时指定目标类型,并在要转换的表达式前加上单引号即可。
int i;
real r;
i = int '(10.0 - 0.1);
r = real '(42);
动态转换:将子类的句柄赋值给父类的句柄。但是将父类的句柄赋值给子类句柄的时候会报错,可以使用$cast(sub_handle, base_handle)将父类句柄转换为子类句柄,只要该父类句柄指向的是一个子类的对象。
function int $cast( singular dest _var, singular source_exp ) ;
//或者
task $cast( singular dest_var, singular source_exp );
module tb;
class BasePacket;
endclass : BasePacket
class My_Packet extends BasePacket;
endclass : My_Packet
BasePacket P1 = new;
My_Packet P2 = new;
My_Packet P3 = new;
initial begin
P1 = P2; // 子类赋值给父类,父类P1指向子类对象P2
$cast(P3, P1); // 父类赋值给子类,子类P3指向父类对象P1,前提父类P1指向相同的子类类型My_Packet
end
endmodule
4.1 覆盖率概述
伴随着复杂SoC系统的验证难度系数成倍增加,无论是定向测试还是随机测试,我们在验证的过程中终究需要回答两个问题:
-
是否所有设计的功能在验证计划中都已经验证?
-
代码中的某些部分是否从未执行过?
覆盖率就是用来帮助我们在仿真中回答以上问题的指标。
一旦通过覆盖率来量化验证,我们可以在更复杂的情况下捕捉一些功能特性是否被覆盖:
-
当我们在测试X特性的时候,Y特性是否也在同一时刻被使能和测试?
-
是否可以精简我们已有的测试来加速仿真,并且取得同样的覆盖率?
-
覆盖率在达到一定的数值的时候,是否停滞,不再继续上升?
简单而言,覆盖率就是用来衡量验证精度和完备性的数据指标。覆盖率可以告诉我们在仿真时设计的哪些结构被触发,当然,它也可以告诉我们设计在仿真时的哪些结构从未被触发过
只有满足以下三个条件,才可以在仿真中实现高质量的验证:
- 测试平台必须产生合适的激励来触发一个设计错误
- 测试平台仍然需要产生合适的激励使得被触发的错误可以进一步传导到输出端口
- 测试平台需要包含一个监测器(monitor)用来监测被激活的设计错误,以及在它传播的某个节点(内部或者外部)可以捕捉到它
4.2 覆盖率种类
-
没有任何一种单一的覆盖率可以完备地去衡量验证过程
-
及时我们可以达到100%的代码覆盖率(隐性覆盖率),但这并不意味着100%的功能覆盖率(显性覆盖率)。原因在于代码覆盖率并不是用来衡量设计内部的功能运转,或者模块之间的互动,或者功能时序的触发等。
-
类似地,我们即便达到了100%功能覆盖率,也可能只达到了90%的代码覆盖率。原因可能在于我们疏漏了去测试某些功能,或者一些实现的功能并没有被描述。
-
从上述关于代码覆盖率和功能覆盖率简单的论述就可以证明,如果想要得到全面的验证精度,我们就需要多个覆盖率种类的指标。

-
如果将上述两个分类的方式(隐性/显性、功能描述/设计实现)进行组合,那么可以将代码覆盖率、断言覆盖率以及功能覆盖率分别置入到不同的象限。
-
但是需要注意,目前有一个象限仍然处于研究阶段,没有隐性的可以从功能描述生成某种覆盖率的方法,这也是为什么功能覆盖率依然需要人为定义的原因。
4.3 代码覆盖率
-
跳转覆盖率(toggle):用来衡量寄存器跳转的次数(0->1,1->0);端口跳转覆盖率经常用来测试IP模块之间的基本连接性,例如检查一些输入端口是否没有连接,或者已经连接的两个端口的比特位数是否不匹配,又或者一些已经连接的输入是否被给定的固定值等,都可以通过跳转覆盖率来发现问题
-
行覆盖率(statement/line):用来衡量源代码哪些代码行被执行过,以此来指出哪些代码行没有被执行过
-
分支覆盖率(branch):分支覆盖率是用来对条件语句( if/else, case,?😃,指出其执行的分支轨迹。例如判断下列分支的布尔表达式为true或者false:
if(parity == ODD || parity == EVEN) begin -
条件覆盖率(condition/expression):条件覆盖率是用来衡量一些布尔表达式中各个条件真伪判断的执行轨迹。例如下列if条件语句中的两个条件是否各自衡量为true/false:
if(parity ==ODD || parity ==EVEN) begin //parity ==ODD或者parity != ODD //paraity ==EVEN或者parity !=EVEN -
状态机覆盖率(FSM):仿真工具由于可以自动识别状态机,因此在收集覆盖率时,也可以将覆盖率状态的执行情况监测到。每个状态的进入次数,状态之间的跳转次数,以及多个状态的跳转顺序都可以由仿真工具记录下来。
4.4 功能覆盖率
-
功能验证的目标在于确定设计有关的功能描述是否被全部实现了?
-
这一检查中可能会存在一些不期望的情况:①—些功能没有被实现;②—些功能被错误地实现了;③—些没有被要求的功能也被实现了
-
功能覆盖率是最好地可以协助在回归测试时自动监测哪些功能被激活的方法。
-
创建功能覆盖率模型需要完成以下两个步骤:
- 从功能描述文档提取拆分需要测试的功能点
- 将功能点量化为与设计实现对应的SV功能覆盖代码
4.4.1 覆盖组(covergroup)
- 覆盖组可以采集任何可见的变量,比如程序或模块变量、接口信号或者设计中的任何信号
- 在类中的覆盖组也可以采集类的成员变量覆盖组应该定义在适当的抽象层次上
- 对任何事务的采样都必须等到数据被待测设计接收到以后
- 一个类也可以包含多个覆盖组,每个覆盖组可以根据需要将它们使能或者禁止,一个覆盖组可以有多个覆盖点
enum { red, green , blue ] color ;
bit [ 3:0] pixel_adr, pixel_offset, pixel_hue;
covergroup g2 e (posedge clk) ;
Hue : coverpoint pixel_hue;
offset: coverpoint pixel_offset;
Axc: cross color, pixel_adr; // cross 2 variables
all: cross color,Hue,offset; // cross 1 VARs and 2 CPs
endgroup
g2 cg_inst = new();//要进行例化
- 将covergroup定义在类中,声明一个匿名的覆盖组类型和一个覆盖组变量cov1,一个类中可以有多个覆盖组
class xyz;
bit [3:0] m_x;
int m_y;
bit m_z ;
covergroup cov1 @m_z; // embedded covergroup
coverpoint m_x ;
coverpoint m _y ;
endgroup
covergroup cov2 @(posedge clk);
coverpoint m_x;
endgroup
function new() ;
cov1 = new ;
cov2 = new ;
endfunction
endclass
4.4.2 覆盖点coverpoint
-
一个covergroup可以包含一个或者多个coverpoint,一个coverpoint可以用来采样数据或者数据的变化,cross使用交叉覆盖。
-
一个coverpoint可以对应多个bin (仓)
-
这些仓可以显性指定,也可以隐性指定
-
coverpoint对数据的采样发生在covergroup采样的时候
-
可以通过
iff在一些情况下禁止coverpoint的采集covergroup g4 ; coverpoint s0 iff ( !reset) ; endgroup -
一般需要对覆盖点重新命名一个name,便于后面的交叉覆盖
covergroup cg ( ref int x , ref int y, input int c) ; coverpoint x; //创建CP x b: coverpoint y; //创建CP b cx: coverpoint x; //创建CP cx option.weight = c; bit [ 7:0] d: coverpoint y[31:24];//创建cP d e: coverpoint x { option.weight = 2 ; } cross x, y { //创建crossCP xXy option.weight = c; } endgroup
4.4.3仓bin
-
关键词bins可以用来将每个感兴趣的数值均对一个独立的bin,或者将所有值对应到一个共同的bin
bit [9:0]v_a; covergroup cg @(posedge clk); coverpoint v_a { bins a = {[O:63],65} ; bins b[] = { [127:150],[148:191] } ; bins c[] = { 200,201,202 } ; bins d = { [1000:$] } ; bins others[] = default; } endgroup -
covergroup里面的参数也可以被传递到bin的定义中
covergroup cg (ref int ra,input int low, int high ) @(posedge clk) ; coverpoint ra { bins good = { [low : high] }; bins bad[] = default; } endgroup ... int va , vb ; cg c1 = new ( va, 0,50 ) ; cg c2 = new ( vb,120,600 ) ; -
在定义bin时,可以使用with来进一步限定其关心的数值,with可以用表达式或者函数来衡量
a : coverpoint x { bins mod3[] = { [0:255] } with (item % 3 ==0); } coverpoint b { bins func[] = b with (myfunc(item)) ; } -
值变化覆盖,用
*表示连续的重复;用=>表示非相邻的重复次数,在下一个时序必须紧跟下一个指定值变化;用->表示非相邻的重复次数,下一次值变化可以在->结束后的任何时刻。//值的变化 value1 =>value2 value1 =>value3 =>value4 =>value5 //一串值的变化 range_list1 =>range_list2 1,5 =>6,7 //值变化时的连续重复次数 trans_item [*repeat_range ] 3 [*5]//表示3=>3=>3=>3=>3 3 [*3:5]//表示(3=>3=>3 ), (3=>3=>3=>3 )或(3=>3=>3=>3=>3 ) //除了使用=>来表示相邻采样点的变化,也可以使用->来表示非相邻采样点的数值变化,在=>序列后的下一个时序必须紧跟=>序列的最后一个事件 3 [->3]//表示...=>3...=>3...=>3 1=>3 [->3]=>5//表示1...=>3...=>3...=>3 =>5 //与[-> repeat_range ]类似的有[= repeat_range ]也表示非连续的循环,只是与->有区别的在于,跟随->序列的下一次值变化可以发生在->结束后的任何时刻。 3 [=2]//表示...=>3...=>3 1=>3 [=2]=>6//表示1...=>3...=>3...=>6bit [4:1] v_a; covergroup cg e @(posedge clk) ; coverpoint v_a { bins sa = (4=>5 =>6),([7:9] ,10=>11,12); bins sb[] = (4=>5 =>6),([7:9],10=>11,12); bins sc = (12 =>3 [->1]); } endgroup -
未指定bins则会自动生成,若变量是枚举类型,bin数量是枚举类型的所有组合的和;若变量是整型(m位宽),bin数量是m位宽数的2的m次方或auto_bin_max选项的较小值。
-
ignore_bins用来将其排除在有效统计的bin集合之外
covergroup cg23 ; coverpoint a { ignore_bins ignore_vals = { 7,8} ; ignore_bins ignore_trans = (1=>3=>5); } endgroup -
illegal_bins用来指出采样到的数值为非法制,如果illegal_bins被采样到,那么仿真将报错
covergroup cg3 ; coverpoint b { illegal_bins bad_vals = { 1,2,3}; illegal_bins bad_trans = (4=>5=>6); } endgroup
4.4.4 交叉覆盖率cross
-
covergroup可以在两个或者更多的coverpoint或者变量之间定义交叉覆盖率(cross coverage)
-
在对a和b产生交叉覆盖率之前,系统会先为它们隐性产生对应的coverpoint和bin,每个coverpoint都有16(2^4)个自动产生的bin,两个coverpoint交叉以后将生成256(16*16)个交叉的bin
bit [3:0] a, b; covergroup cov @ (posedge clk) ; aXb : cross a, b; endgroup -
被声明为default/ignore/illegal的bin将不会参与cross coverage的运算。交叉覆盖率只允许在同一个covergroup中定义的CP(coverpoint)参与运算
-
除了系统会自动为交叉覆盖率生成bin以外,用户还可以自己定义交叉覆盖率的bin,使用
binsof()的参数可以是coverpoint或者变量,表示对应的bin总和,可以利用binsof()对其结果做进—步的过滤int i,j; covergroup ct; coverpoint i { bins i[] = { [0: 1] } ; } coverpoint j{ bins j[]= { [0:1] } ; } x1: cross i,j; x2: cross i,j{ bins i_zero = binsof(i) intersect { 0 }; } endgroup /* 交叉x1自动分配产生bin: <i[O],j[0]> <i[1],j[O]> <i[01,j[1]> <i[11,j[1]> 交叉x2自定义产生bin: i_zero(自定义bin for <i[0],j[0]> and <i[O],j[1]>) <i[1],j[0]>(保留自动生成的bin) <i[1],j[1]>(保留自动生成的bin) */ bit [7:0] v_a, v_b; covergroup cg e(posedge clk); a: coverpoint v_a { bins a1 = { [O:63] }; bins a2 = { [64 :127]} ; bins a3 = { [128:191] } ; bins a4 = { [192:255] }; } b: coverpoint v_b { bins b1 = {0 }; bins b2= { [1:84] }; bins b3 = { [85:169] } ; bins b4 = { [170:255] }; } c : cross a, b { bins c1 = ! binsof(a) intersect { [100:200] };// 4 products bins c2 = binsof(a.a2) || binsof(b.b2);// 7 products bins c3 = binsof(a.a1) && binsof(b.b4);// 1 product } endgroup /* c1中,需要对a排除a2/a3/a4,保留a1,因此与b的交叉结果是<a1,b1>, <a1,b2>,<a1,b3>,和<a1,b4> c2中,包括a2与{b1,b2,b3,b4}的交叉以及b2与{a1,a2,a3,a4}的交叉,最终交叉结果是<a2,b1>,<a2,b2>,<a2,b3>,<a2,b4>, <a1,b2>, <a3,b2>和<a4,b2> c3中只包含<a1,b4> 由于上述的3个cross中有重叠的数值组合,最终共有10个有效组合 a交叉b的理论结果是16个数值组合,排除用户指定的10个,另外剩余的6个将做为保留的自动数值组合结果<a3,b1>,<a4,b1>, <a3,b3>, <a4,b3>,<a3,b4>和<a4,b4> */
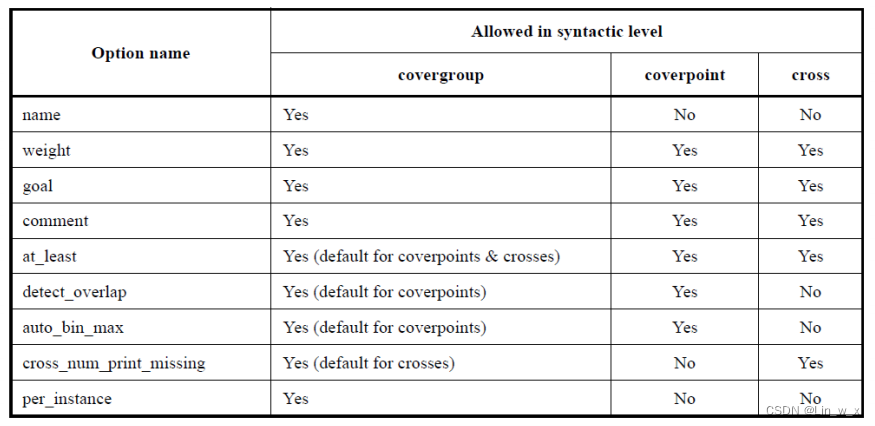
4.4.5 指定覆盖率选项
- 覆盖率选项可以在covergroup、coverpoint或者cross中分别设置
- 常见的参数,譬如weight可以在covergroup设置来表示它实例的比重,也可以在coverpoint/cross中设置来表示它们在covergroup中的比重,默认值是1
- per_instance如果设置为1,将会记录每个covergroup实例的覆盖率数据,默认值是0
- comment则是用来对covergroup/coverpoint/cross做进一步的说明,方便在覆盖率数据分析时阅读理解
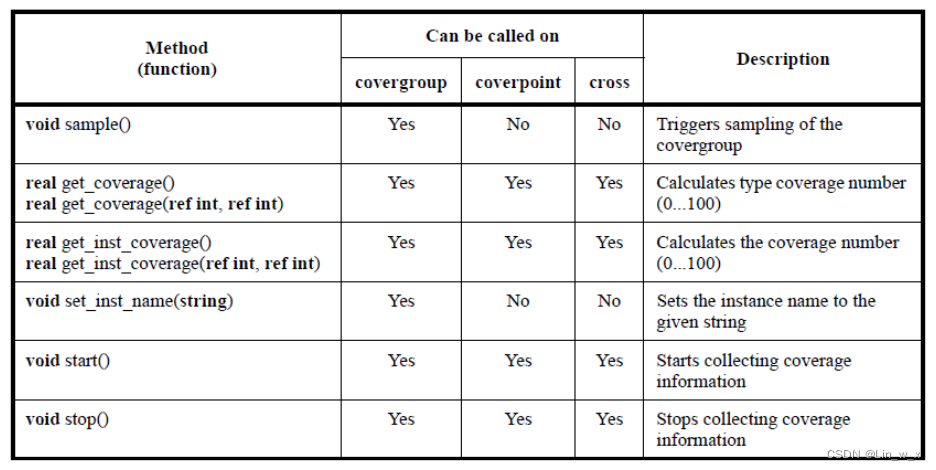
4.4.6 预定义覆盖率方法
5.1 断言概述
Assertion
- 断言是设计的属性的描述。
- 如果一个在仿真中被检查的属性不像我们期望的那样表现,那么这个断言将失败。
- 如果一个被禁止在设计中出现的属性在仿真过程中发生,那么这个断言也将失败。
- 一系列的属性可以从设计的功能描述中推知,并且被转换成为断言。
- 这些断言可以在功能仿真中不断地被监视。
- 相同的断言既可以在仿真中使用,也可以在形式验证中复用。
5.2 即时断言(immediate assertion)
-
基于仿真事件的语义。
-
测试表达式的求值就像在过程块中其它表达式一样。
-
即时断言本质不是时序相关的,而是立即被求值。
-
必须放在过程块的定义中。
-
只能用于动态模拟。
always_comb begin a_ia: assert (a && b); end
5.3 并发断言(concurrent assertion)
-
基于时钟周期。
-
在时钟边缘根据调用的变量采样值计算测试表达式。
-
可以放到过程块、模块、接口或者一个程序(program)的定义中。
-
可以在形式验证和动态仿真验证工具中使用。
a_cc: assert property(@(posedge clk) not (a && b));
5.4 建立SVA(System Verilog Assertion)块
-
SVA用sequence来表示这些事件,其基本语法是:
sequence name_of_sequence; < test expression> ; endsequence -
许多序列可以逻辑伙计有序组合生成更复杂的序列。SVA用property来表示这些复杂的有序行为,其基本语法是:
property name_of_property; < test expression >; or < complex sequence expressions >; endproperty -
属性(property)是仿真过程中被验证的单元。
-
属性必须在仿真过程中被断言来发挥作用。
-
SVA提供了assert来检查属性。
assertion_name: assert property(property_name) ; -
属性检查的默认都是正确的条件,属性也可以被禁止发生。禁止属性即表示期望属性永远为假,当属性为真时,断言失败。
sequence s6 ; @(posedge clk) a ##2 b; endsequence property p6 ; not s6;//禁止属性 endproperty a6: assert property (p6); -
SV语言被定义成每当一个断言检查失败,仿真器会默认打印一条错误信息,而对于成功的断言,仿真器则不会打印消息。
建立SVA检查器的步骤:
5.4.1 序列sequence
序列内建方法:
$rose(expression or signal):当信号/表达式由0变成1时返回真。$fe11(expression or signal):当信号/表达式由1变成0时返回真。$stable(expression or signal):当信号/表达式不发生变化时返回真。
//在时钟上升沿时刻采样前一采样为0,后一次采样为1时为true
sequence s2;
@(posedge clk) $rose(a);
endsequence
序列中的逻辑关系:
-
序列s3在时钟上升沿检查,信号a或b是高电平
sequence s3; @(posedge clk) a||b; endsequence
序列中的形式参数:
-
通过在序列定义形式参数,使得序列可以被重用*到设计中具有相似行为的信号上。
sequence s3_lib (a, b); a || b ; endsequence //进行嵌套 sequence s3_lib_inst1; s3_lib(reql, req2) ; endsequence
序列中的时序关系:
-
对于需要几个时钟周期才能完成的事件,即时序检查,SVA中会用
##来表示时钟周期延迟。//a为高后经过两拍b也为高则为true sequence s4 ; @(posedge clk) a ##2 b; endsequence
5.4.2 SVA中的时钟定义
在序列、属性和断言语句中都可以定义时钟。建议在属性中指定时钟,并保持序列独立于时钟,这样可以提高基本序列定义的可重用性。
//在序列里面定义时钟,不推荐
sequence s5;
@(posedge clk) a ##2 b;
endsequence
property p5 ;
s5 ;
endproperty
a5 : assert property(p5);
//在属性里面定义时钟,推荐,可重用性
sequence s5a;
a ##2 b;
endsequence
property p5a;
@(posedge clk) s5a;
endproperty
a5a : assert property(p5a);
5.4.3 蕴含操作符
蕴含( implication)等效于一个if-then结构。
蕴含的左边叫做先行算子(antecedent),右边叫做后续算子(consequent) 。
先行算子是约束条件,当其成功时,后续算子才会被计算。如果先行算子不成功,那么整个属性就默认为"空成功"(vacuous success) 。
蕴含结构只能用在属性定义中,不能在序列中使用。
蕴含可以分为交叠蕴含(overlapped implication)和非交叠蕴含(non-overlapped implication) 。
交叠蕴含:
- 交叠编含用符号
|->表示。 - 它表示如果先行算子匹配,则在同一个周期计算后续算子的表达式。
- p8检查a在给定时钟上升沿是否给高电平,如果为高,信号b在相同的时钟边沿也必须为高。
property p8 ;
@(posedge clk) a |-> b ;
endproperty
a8 : assert property (p8 ) ;
非交叠蕴含:
- 交叠蕴含用符号
|=>表示。 - 它表示如果先行算子匹配,则在下一个周期计算后续算子的表达式。
- p9检查a在给定时钟上升沿是否给高电平,如果为高,信号b在下一个时钟边沿也必须为高。
property p9;
@(posedge clk) a |=> b;
endproperty
a9: assert property (p9 );
5.4.4 描述延迟的方法
有限时序:
- p12检查a&&b在任何给定的时钟上升沿为真。
- 如果表达式为真,则在接下来的1~3个周期内,信号c应该至少在一个时钟周期为高。
property p12;
@(posedge clk) (a && b) |-> ##[1: 3] c;
endproperty
a12: assert property (p12);
无限时序:
- 在时序窗口的窗口上线可以使用
$定义,表明时序没有上限,这叫做"可能性"运算符。 - 检验器不停地检查表达式是否成功直到仿真结束。
- 因为这种方式会对仿真性能产生巨大的负面影响,所有不推荐使用无限时序窗口,最好总是使用有限的时序窗口上限。
property p14;
@(posedge clk)a |-> ##[1:$] b ##[0∶$] c;
endproperty
a14 : assert property (p14);
ended结构:
- 既可以基于序列的起始点来同步序列,也可以基于序列的结束点来同步序列。
sequence s15a;
@(posedge clk) a ##1 b;
endsequence
sequence s15b;
@(posedge clk) c ##1 d;
endsequence
property pl5a;
s15a |=> s15b;
endproperty
property p15b;
s15a.ended |->##2 s15b.ended;
endproperty
a15a : assert property(p15a);
a15b : assert property(p15b);
5.4.5 SVA中的操作符
选择操作符:
- SVA允许属性和序列中使用逻辑运算符。
property p17;
@(posedge clk) c ? d == a : d == b;
endproperty
a17 : assert property (p17) ;
$past构造:
- SVA提供了一个内嵌的系统任务
$past,它可以得到信号在几个时钟周期之前的值。默认情况下,它提供信号在前一个时钟周期的值。$past(signal_name , number of clock cycles)
//满足c、d都为高时检查前两个周期a&&b是否为高
property p19;
@(posedge clk) (c && d) |-> ($past((a&&b),2) == 1’b1);
endproperty
a19 : assert property (p19);
连续重复运算符[*n]、连续重复和可能性运算符:
- 表明信号或者序列将在指定数量的时钟周期内连续地匹配。信号的每次匹配之间都有一个时钟周期的隐藏延迟。
signal or sequence [*n]
property p21;
@(posedge clk)$rose ( start) |-> ##2 ( a [*3])##2 stop##1 l stop;
endproperty
a21: assert property (p21);
- 连续重复的次数也可以是一个窗口。
a[*1:5]表示信号a从某个时钟周期开始重复1~5次。$表示无限。
property p24;
@(posedge clk)$rose (start) |-> ##2 (a[*1:$]) ##1 stop;
endproperty
跟随重复运算符[->]:
- p25检查如果start信号在任何时钟上升沿拉高,那么两个时钟周期后,信号a连续或者间断地出现3次为高,接着信号stop在下一个时钟周期为高。
property p25;
@(posedge clk)$rose (start) |-> ##2 (a[->3]) ##1 stop;
endproperty
非连续重复运算符[=]:
- 非连续重复运算符[=]表明,在信号stop有效匹配的前一个时钟周期,信号a不一定需要有有效的匹配,不需要紧跟着下一个周期就判断。
property p26;
@(posedge clk) $rose(start) |-> ##2 (a[=3]) ##1 stop ##1 ! stop;
endproperty
and结构:
- 二进制操作符and可以用来逻辑地组合两个序列。当两个序列都成功时,整个属性才成功。
- 两个序列必须具有相同的起始点,但是可以有不同的结束点。
- 检验的起始点是第一个序列的成功时的起始点,而检验的结束点是使得属性最终成功的另一个序列成功时的结束点。
sequence s27a;
@(posedge clk) a## [1:2] b;
endsequence
sequence s27b;
@(posedge clk) c## [2:3] d;
endsequence
property p27;
@(posedge clk) s27a and s27b;
endproperty
intersect构造:
- intersetc与and操作符相似,它有一个额外的要求。两个序列必须在相同时刻开始且结束于同一时刻,换句话说,两个序列的长度必须相等。
sequence s28a ;
@(posedge clk) a ##[1:2] b;
endsequence
sequence s28b ;
@(posedge clk) c ##[2:3] d ;
endsequence
property p28;
@(posedge clk) s28a intersect s28b;
endproperty
or构造:
- or可以用来逻辑地组合两个序列。只要其中一个序列成功,整个属性就成功。
sequence s29a;
@(posedge clk) a ##[1:2] b;
endsequence
sequence s29b;
@(posedge clk) c ##[2:3] d;
endsequence
property p29;
@(posedge clk) s28a or s28b;
endproperty
first match构造:
- 任何时候,使用了逻辑操作符如and/or指定了时间窗,就有可能出现一个检验具有多个匹配的情况。
- first__match构造可以确保只用第一次序列匹配,而丢弃其它的匹配。
- 当多个序列被组合在一起,first_match可以帮助在指定时间窗内只选择第一次匹配。
sequence s30a ;
@(posedge clk) a ##[1:3] b;
endsequence
sequence s3 ob;
@(posedge clk) c ##[2:3] d;
endsequence
property p30 ;
@(posedge clk) first_match (s30a or s30b);
endproperty
throughout构造:
- 当要求在检验序列的整个过程中,某个条件必须一直为真时,可以使用throughout操作符。
(expression) throughout (sequence)
property p31 ;
@(posedge clk) $fell(start) |-> (!start) throughout
(##1 (!a && !b) ##1 (c[->3]) ##1( a&&b)) ;
endproperty
within构造:
- within允许在一个序列中定义另一个序列。
seq1 within seq2 - 这表示seq1在seq2的开始到结束范围内发生,且seq2的开始点必须在seq1的开始点之前发生,seq2的结束点必须在seq1的结束点之后结束。
sequence s32a ;
@(posedge clk)
((!a && !b) ##1 (c[->3]) ##1 (a&&b));
endsequence
sequence s32b;
@(posedge clk)
$fell(start) ##[5:10] $rose(start) ;
endsequence
sequence s32;
@(posedge clk) s32a within s32b;
endsequence
property p32 ;
@(posedge clk) $fell(start) │-> s32;
endproperty
SVA内建的系统函数:
$onehot(expr),检验表达式满足"one-hot",即表达式是否只有一位为1。$onehotO(expr),检验表达式是否只有一位或者没有任何位为1。$isunknown(expr),检验表达式任何位是否有X或者Z。$countones(expr),计算向量中为1的位数。
disable iff:
- 在一些情况中,如果一些条件为真,则我们不应该执行检验。
- 例如在复位时,一般不需要执行检验。
- disable iff 可以用来禁止在一些条件下的属性检验。
disable iff (expr) <property>
property p34;
@(posedge clk)
disable iff (reset)
$rose (start) |=> a [=2] ##1 b[=2] ##1 !start ;
endproperty
蕴含中的if…else:
- 蕴含属性的后续算子中可以使用if…else语句。
property p_if_else ;
@(posedge clk)
($fell(start) ##1 (a||b)) |->
if(a)
(c[->2] ##1 e)
else
(d[->2] ##1 f );
endproperty
SVA中的多时钟定义:
- 在SVA中处理多时钟同设计中处理多时钟问题一样,需要额外的小心。
- SVA允许序列或者属性使用多个时钟定义来采样独立的信号或者子序列。
- SVA会自动地同步不同信号或子序列使用的时钟域。
sequence s_multiple_clocks ;
@(posedge clk1) a ##1 @(posedge clk2) b;
endsequence
property p_multiple_clocks;
@(posedge clk1) s1 ##1 @(posedge clk2) s2 ;
endproperty
-
使用##0会产生混淆,即在信号a匹配后究竟哪个时钟才是最近的时钟,这将会引起竞争,因此不允许使用。
-
使用##2也不允许,因为不可能同步到时钟clk2的最近的上升沿。
-
按照以上的规定,SVA允许使用非交叠蕴含符
|=>来实现多时钟序列/属性描述。
property p_ multiple_clocks_implied;
@(posedge clk1) s1 |=> @(posedge clk2) s2 ;
endproperty
- SVA禁止使用交叠蕴含符
|->来实现多时钟序列/属性描述。
property p_multiple_clocks_implied_illegal;
@(posedge clk1) s1 |-> @(posedge clk2) s2 ;
endproperty
expect构造:
- expect与Verilog中的等待语句类似,区别在于expect语句等待的是属性的成功检验。
- expect构造后的代码是作为一个阻塞语句来执行。
- expect构造语法与assert构造块相似。
- expect语句允许在一个属性成功或者失败后使用一个执行块。
initial
begin
@(posedge clk);
#2ns cpu_ready = 1'b1 ;
expect (@(posedge clk) ##[1∶16] memory_ready == 1 'b1)
$display("Hand shake successful\n" );
else
begin
$display("Hand shake failed: exiting\n");
$finish();
end
for (i=0 ; i<64; i++)
begin
send_packet();
$display("PACKET %0d sent\n" , i ) ;
end
end
SVA中的局部变量:
- 在序列或者属性内部可以局部定义变量,而且可以对这种变量进行赋值。
- 变量接着子程序放置,用逗号隔开。
- 如果子序列匹配,那么变量赋值语句执行。
- 每次序列被尝试匹配时,会产生变量的一个新的备份。
property p_local_var1;
int lvar1;
@(posedge clk)
($rose (enable1) , lvar1 = a) |-> ##4 (aa == (lvar1*lvarl* lvar1));
endproperty
SVA中调用子程序:
- SVA可以在序列每次成功匹配时调用子程序。
- 同一序列中定义的局部变量可以作为参数与传给这些子程序。
- 对于序列的每次匹配,子程序调用的执行与它们在序列定义中的顺序相同。
sequence s_display1;
@(posedge clk)
($rose(a), $display("signal a arrived at %t\n",$time));
endsequence
sequence s_display2;
@(posedge clk)
($rose(b), $display ("signal b arrived at %t\n" ,$time) ) ;
endsequence
property p_display_window;
@(posedge clk)
s_display1 |-> ##[2:5] s_display2 ;
endproperty
将SVA与设计连接:
-
可以在模块定义中内建或者内联检验器。
-
可以将检验器与模块、模块实例或者一个模块的多个实例绑定。
-
除此以外,通过接口interface去监测设计内部信号,再将SVA嵌入到接口中也是一种可复用性高的SVA连接方式。
SVA与功能覆盖率:
- SVA通过cover与属性property结合,可以用来检查例如协议和其它时序的覆盖情况。
<cover_name> : cover property(property_name) - cover语句的结果包含以下信息:
- 属性被尝试检验的次数·属性成功的次数
- 属性失败的次数
- 属性空成功的次数
- cover语句也可以有执行块,譬如覆盖成功匹配时,可以调用函数或者任务,或者更新一个局部变量。
s1 |-> @(posedge clk2) s2 ;
endproperty
expect构造:
+ expect与Verilog中的等待语句类似,区别在于expect语句等待的是属性的成功检验。
+ expect构造后的代码是作为一个阻塞语句来执行。
+ expect构造语法与assert构造块相似。
+ expect语句允许在一个属性成功或者失败后使用一个执行块。
```systemVerilog
initial
begin
@(posedge clk);
#2ns cpu_ready = 1'b1 ;
expect (@(posedge clk) ##[1∶16] memory_ready == 1 'b1)
$display("Hand shake successful\n" );
else
begin
$display("Hand shake failed: exiting\n");
$finish();
end
for (i=0 ; i<64; i++)
begin
send_packet();
$display("PACKET %0d sent\n" , i ) ;
end
end
SVA中的局部变量:
- 在序列或者属性内部可以局部定义变量,而且可以对这种变量进行赋值。
- 变量接着子程序放置,用逗号隔开。
- 如果子序列匹配,那么变量赋值语句执行。
- 每次序列被尝试匹配时,会产生变量的一个新的备份。
property p_local_var1;
int lvar1;
@(posedge clk)
($rose (enable1) , lvar1 = a) |-> ##4 (aa == (lvar1*lvarl* lvar1));
endproperty
SVA中调用子程序:
- SVA可以在序列每次成功匹配时调用子程序。
- 同一序列中定义的局部变量可以作为参数与传给这些子程序。
- 对于序列的每次匹配,子程序调用的执行与它们在序列定义中的顺序相同。
sequence s_display1;
@(posedge clk)
($rose(a), $display("signal a arrived at %t\n",$time));
endsequence
sequence s_display2;
@(posedge clk)
($rose(b), $display ("signal b arrived at %t\n" ,$time) ) ;
endsequence
property p_display_window;
@(posedge clk)
s_display1 |-> ##[2:5] s_display2 ;
endproperty
将SVA与设计连接:
-
可以在模块定义中内建或者内联检验器。
-
可以将检验器与模块、模块实例或者一个模块的多个实例绑定。
-
除此以外,通过接口interface去监测设计内部信号,再将SVA嵌入到接口中也是一种可复用性高的SVA连接方式。
SVA与功能覆盖率:
- SVA通过cover与属性property结合,可以用来检查例如协议和其它时序的覆盖情况。
<cover_name> : cover property(property_name) - cover语句的结果包含以下信息:
- 属性被尝试检验的次数·属性成功的次数
- 属性失败的次数
- 属性空成功的次数
- cover语句也可以有执行块,譬如覆盖成功匹配时,可以调用函数或者任务,或者更新一个局部变量。















 1199
1199











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









