









文章信息

团队:ETIS - CY Cergy Paris University, University of Ljubljana,
关键词:自监督异常检测(SSAD),深度伪造识别,对比学习
概述
提出了软差异的数据增强方法,细化了两类图片差异的位置和类型;使用约束对比学习损失将增强样本和增强原型拉近,使模型学习到对图片较好的表征。通过计算测试样本与各原型的距离和给出异常分数,作为异常检测的判断。
使用技术
异常检测
K个规整分散的团代表了K种区域上的时域和频域修改,并用对比学习训练网络映射增广样本靠近对应的原型,描述了正常样本在各区域时域和频域的内容。OOD样本因为多次远离原型,计量的与各原型的总距离较大,因此异常分数较大。且距离较大的部分,应该是被篡改,而不是因为被增广。
软差异“Soft Discrepancies”
软差异,修改脸部16个patch之一的时域/ 频域信息,保存为增强样本

其中的数据增强:
使用幅度小于 20 的 RGB 偏移,限制为 0.3 的 HSV 偏移,以及最大比例为 0.1 的亮度和对比度的随机缩放。对于频域中的局部增强,随机考虑以下运算符之一:下采样因子为 2 或 4,锐化范围在 0.2 和 0.5 之间,以及质量因子在 30 和 70 之间的 JPEG 压缩。
优点:修改小,肉眼难见;
训练
定义球面上16个均匀分布的顶点为硬原型,即16种增广方式各自对应的基准。训练时使用对比学习将增广样本与其原型拉近,定义对比损失L-sc和约束对比回归损失L-BCR。将预测和实际标签记为损失L-GUI. 两部分组成训练整体损失。


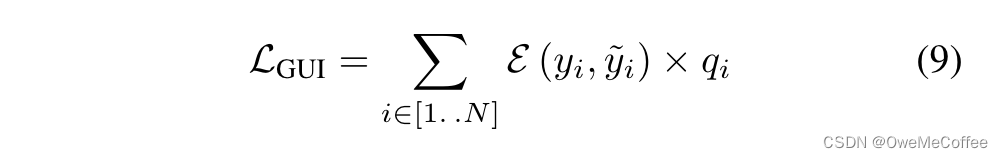
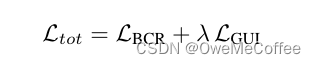
测试
定义样本的K个特征映射与各原型的cos距离为异常分数。相当于从K次(时域+频域)去测量样本与原型的差异,利用异常样本在一些区域的时域或频域的差异拉大异常分数,实现异常检测。
效果
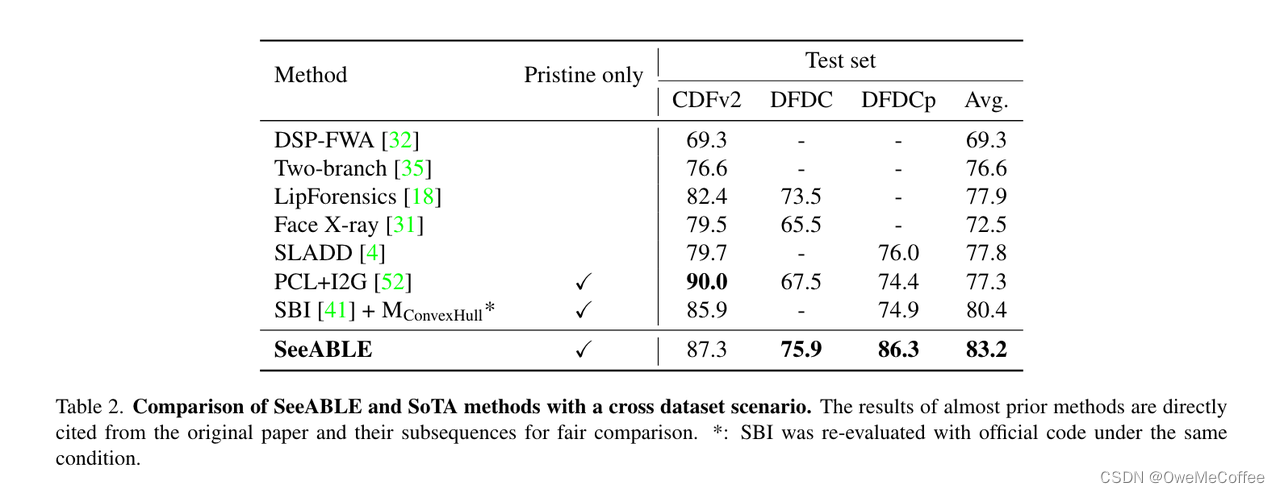
在使用更简单的模型时,DFDC 预览数据集在检测精度方面比 SoTA 方法提高 +10%

















 317
317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









