







目录
1. 方差分析(ANOVA)结合 Dunnett 多重比较
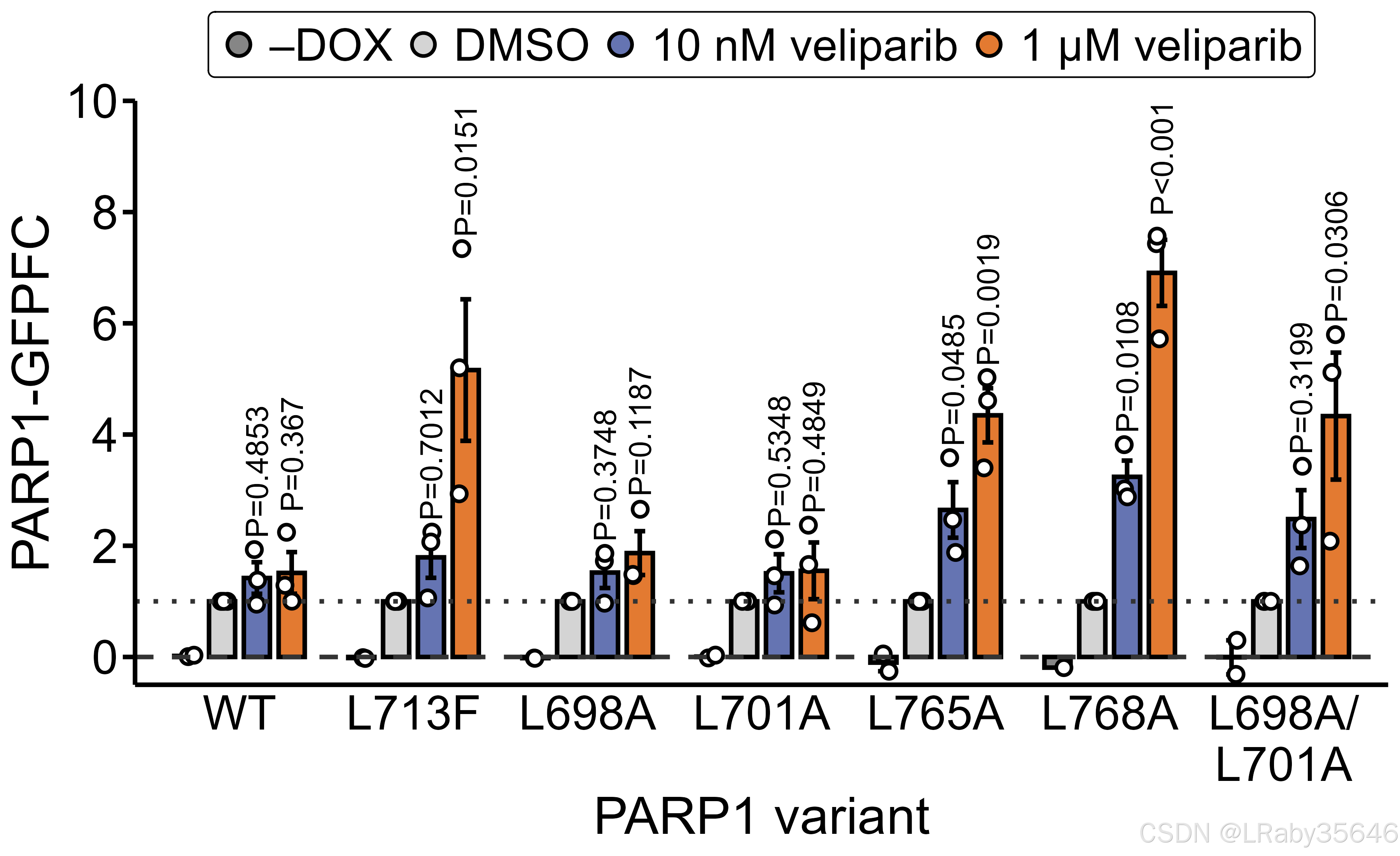
源于:Coupling cellular drug-target engagement to downstream pharmacology with CeTEAM论文Fig2c
原始数据🔗原始数据
方差分析(ANOVA)结合 Dunnett 多重比较 是一种在 ANOVA 显示组间存在显著差异时,进一步用于多重比较的方法,尤其适用于比较多个实验组和一个控制组之间的差异。
方差分析(ANOVA)
方差分析(ANOVA)是一种用于检验多个样本均值是否存在显著差异的方法。通过比较组间方差和组内方差的比值(F 值),我们可以判断至少是否有两个组之间的均值存在显著差异。
Dunnett 多重比较
Dunnett 多重比较 是在 ANOVA 检验后,用于比较多个实验组与一个控制组之间的差异的事后检验方法。它适用于有多个实验组(处理组),但只有一个控制组的情况。
ANOVA + Dunnett 结合使用
在进行 ANOVA 后,如果你发现有显著的组间差异(即至少有两组的均值不同),你可以使用 Dunnett 多重比较 来进一步检验哪些实验组与控制组之间有显著差异。Dunnett 比较的是实验组与控制组之间的差异,而不是各个实验组之间的差异。
操作步骤:
- 进行 ANOVA 检验,首先判断是否存在显著的组间差异。如果 ANOVA 显示存在显著差异(p 值小于显著性水平),继续进行下一步。
- 使用 Dunnett 多重比较,选择一个控制组(通常是未处理组或标准治疗组),将所有其他实验组与控制组进行比较。
- 进行多重比较检验,Dunnett 会调整每一对实验组与控制组之间的 p 值,从而降低因多重比较引起的错误。
举例说明
假设你有 4 个实验组(A、B、C、D)和一个控制组(E)。你想知道这些实验组与控制组之间是否有显著差异。
- ANOVA 检验:首先进行 ANOVA,检验所有组的均值是否有显著差异。如果 ANOVA 显示显著(p < 0.05),说明至少有两个组的均值存在差异。
- Dunnett 多重比较:然后使用 Dunnett 方法将 A、B、C、D 与 E 进行一对一比较,而不是比较 A、B、C、D 之间的差异。通过这种方法,你可以知道哪些实验组的均值与控制组有显著差异。
library(tidyverse)
library(reshape2)
library(ggfun)
library(broom)
library(DescTools) #事后比较(post-hoc comparison)
library(car) #leveneTest方差齐性检验
data = readxl::read_xlsx("/home/Graph/bar_plot/data-Dunnett.xlsx")
# 宽数据转换为长数据
# 使用factor固定绘图顺序,并使用mutate创建新变量
df <- melt(data, id = c('group','treat')) %>%
mutate(group = factor(group, levels = c("WT", "L713F", "L698A", "L701A",
"L765A","L768A","L698A/\r\nL701A")),
treat = factor(treat, levels = c("–DOX", "DMSO", "10 nM veliparib","1 µM veliparib")))
#####统计分析############################################################################
### 统计分析
# 进行 ANOVA 检验和事后比较(post-hoc comparison)
results <- df %>%
filter(treat != "–DOX") %>% # 文章去除 –DOX controls
group_by(group) %>% # 按照 group 列,分组进行统计分析
summarise(
levene_test = list(leveneTest(value ~ treat, data = cur_data())), # 进行方差齐性检验,即方差是否相等。value是因变量,traet是自变量
anova = list(aov(value ~ treat, data = cur_data())), # 进行方差分析,检验各组均值是否有差异
multi_compare = list(DunnettTest(value ~ treat, data = cur_data(), control = "DMSO")) # 进行多重比较,比较多个组与一个控制组之间的差异
)
# 提取方差齐性检验结果
levene_results <- results %>%
transmute(group, levene_df = map(levene_test, broom::tidy)) %>% # 返回指定的列group,以及产生新列levene_df
unnest(cols = levene_df) # 展开成平铺格式
print(levene_results)
# 提取 ANOVA 结果
anova_results <- results %>%
transmute(group, anova_df = map(anova, broom::tidy)) %>%
unnest(cols = anova_df) %>% # 展开成平铺格式
unique()
# 提取事后比较结果(Dunnett)
multi_compare_results <- results %>%
transmute(group,
multi_compare_df = map(multi_compare, ~ {
df <- as.data.frame(.x$`DMSO`)
df$comparison <- rownames(df)
return(df)
})) %>%
unnest(cols = multi_compare_df) %>% # 展开成平铺格式
mutate(
group1 = "DMSO",
group2 = str_replace(comparison, paste0("-",group1), "")
)
# 整理表格:添加显著性标记
df_lab <- df %>%
group_by(group, treat) %>%
slice_max(value, with_ties = FALSE) %>% # 在最大值处添加显著性标记
left_join(multi_compare_results,
join_by(group == group, treat == group2))%>% # 连接数据的表格和多重比较的表格
mutate(pval = case_when(is.na(pval) ~ NA,
pval < 0.001 ~ "P<0.001",
.default = paste0("P=", round(pval, 4))), # 保留 4 位小数
group = factor(group, levels=c("WT", "L713F", "L698A", "L701A",
"L765A","L768A","L698A/\r\nL701A")),
treat = factor(treat, levels = c("–DOX", "DMSO", "10 nM veliparib",
"1 µM veliparib")))
#####绘图
pal = c("#868686", "#d4d4d4", "#6574b2","#e37a31") # 设置颜色
ggplot(data = df, aes(x = group, y = value)) +
geom_bar(aes(fill = treat), #根据 treat 列的值填充不同颜色
stat = "summary", fun = "mean", #表示条形图展示的是均值
color = "black", size = 1,# 柱状图边框的颜色与宽度
position = position_dodge2(padding = 0.25), width = 0.8) + # padding空值条形图间隔
stat_summary(aes(group = treat), #指定分组变量
geom = "errorbar",fun.data = "mean_se", #添加误差条,计算均值和标准误差,均值 ± 标准误差
width = 0.25, position = position_dodge(width = 0.8),# width = 0.8 设置了条形之间的间距(误差条也会遵循相同的设置
size = 1) +
geom_jitter(aes(color = treat), #根据 treat 列的值设置点的颜色
position = position_jitterdodge(jitter.width = 0.15), #添加抖动效果,使点不重叠
shape = 21, fill = "white", size = 2.5, stroke = 1.2) +
geom_text(data = df_lab, aes(x = group, y = value + 1.4, group = treat, label = pval), #定义文本标签的位置和内容
position = position_dodge(width = 0.8), #调整文本标签位置,使其与条形图对齐
angle = 90, size = 5) +
geom_hline(yintercept = 0, linetype = 2, color = "grey20", size = 1)+ # 添加水平线
geom_hline(yintercept = 1, linetype = 3, color = "grey20", size = 1)+
scale_fill_manual(values = pal, guide = "none") +
scale_color_manual(values = c("black", "black", "black","black")) +
guides(color = guide_legend(override.aes = list(fill = pal, size = 4.2))) +
scale_y_continuous(limits = c(-0.5, 10), #设置 y 轴的显示范围为从 -0.5 到 10
expand = c(0, 0),# 控制 y 轴的扩展,expand = c(0, 0) 表示 y 轴的范围没有额外的空白空间(上下都没有扩展)。
breaks = seq(0, 10, 2)) + # y轴刻度步长为2
labs(x = "PARP1 variant", y = "PARP1-GFPFC")+
theme_classic() +
theme(axis.title = element_text(color = 'black',size = 24),
axis.ticks.x = element_blank(), # 不显示x轴刻度线
axis.ticks.y = element_line(linewidth = 1, color = 'black'), # y轴刻度线宽度,颜色,步长长度
axis.ticks.length.y = unit(0.2, "cm"),
axis.line = element_line(linewidth = 1, color = 'black'),
axis.text = element_text(color = 'black',size = 22),
legend.title = element_blank(),# 图例标签不写
legend.text = element_text(color = 'black',size = 21),# 图例文本
legend.position = "top",
legend.background = element_roundrect(color = "#000000", fill = "white")) #在图例外面添加圆角矩形边框
ggsave("/home/Graph/bar_plot/groups-bar-dot-errorbar-Dunnett.png", width = 9, height = 5.5, dpi = 400)
ggsave("/home/Graph/bar_plot/groups-bar-dot-errorbar-Dunnett.pdf", width = 9, height = 5.5)
1. Levene's Test - 方差齐性检验
目的:检验不同组(由自变量 treat 指定)的方差是否相等。
为什么首先进行 Levene's Test?
- Levene's Test 是进行 ANOVA 之前的前提检验。方差齐性(homogeneity of variance)是 ANOVA 分析的一项基本假设,即假设不同组的方差是相等的。如果方差不齐,ANOVA 可能无法得出准确的结论。
- Levene's Test 检验零假设是各组方差相等。如果 p 值小于某个显著性水平(例如 0.05),就拒绝零假设,意味着各组的方差显著不同。这时,应该谨慎使用 ANOVA 进行方差分析。
2. ANOVA - 方差分析
目的:检验不同组(由 treat 指定)的均值是否存在显著差异。
为什么进行 ANOVA?
- 在 Levene's Test 检验方差齐性假设通过后(即方差相等),接下来可以使用 ANOVA 来比较不同处理组之间的均值差异。
- ANOVA 检验零假设是各组的均值相等。如果 p 值小于显著性水平(如 0.05),则拒绝零假设,意味着至少有一组的均值与其他组显著不同。
3. Dunnett's Test - 事后比较(Post-hoc test)
目的:在 ANOVA 检验显著差异之后,进行多重比较,找出具体哪些组之间存在差异,特别是与对照组(如 DMSO)之间的差异。
为什么进行 Dunnett's Test?
- Dunnett's Test 是一种多重比较检验方法,用于在多组间进行事后分析,通常用于与一个对照组(这里是
DMSO)进行比较。 - 当 ANOVA 显示存在显著差异时,Dunnett's Test 可以告诉你哪些组与对照组之间存在显著差异。与单纯的 ANOVA 检验相比,Dunnett's Test 可以有效控制多重比较带来的第一类错
递进关系:
- Levene's Test → ANOVA → Dunnett's Test
- Levene's Test 首先检验方差齐性。如果方差不齐,可以考虑使用非参数检验方法;如果方差齐,则进行 ANOVA。
- 如果 ANOVA 检验显示组间有显著差异,那么可以进一步使用 Dunnett's Test 来进行对照组与其他组之间的比较。
如果在 Levene's Test 中,7 个组中有一个组的 p 值小于 0.05,表明方差不齐,可以采取以下几种方式:
- 使用 Kruskal-Wallis Test,进行非参数检验。
- 使用 Welch ANOVA,适用于方差不齐的情况。
- 对数据进行适当的 转换,使方差齐性假设得到满足。
- 使用 稳健的多重比较方法,如 Games-Howell Test,进行事后分析。
- 考虑是否需要 排除不满足方差齐性假设的组,但这会损失数据。
2. 方差分析(ANOVA)结合 LSD 多重比较
原始数据🔗原始数据
源于:Viral proteins resolve the virus-vector conundrum during hemipteran-mediated transmission by subverting salicylic acid signaling pathway论文,Fig2c
LSD(最小显著差异)多重比较
在 ANOVA 结果显著的情况下,LSD(Least Significant Difference)方法是进行事后多重比较的一种常用方法。它用于比较具体哪些组之间存在显著差异。
LSD 方法的步骤:
- 前提条件:首先你需要通过 ANOVA 检验出整体有显著差异(即 p 值小于显著性水平)。
- 计算 LSD 值:LSD 值是基于样本大小、均值和方差计算的。
- 进行成对比较:然后你计算每一对组之间的差异,并检查这些差异是否大于 LSD 值。如果差异大于 LSD 值,则表示这两组的均值显著不同。
ANOVA + LSD 的结合使用
通常,在进行 ANOVA 后,如果我们发现组间差异显著(p 值小于显著性水平),接下来的任务就是确定具体哪些组之间有差异。这时可以使用 LSD 多重比较 来进行成对比较。
操作步骤:
- 先进行 ANOVA 检验,判断是否有显著的组间差异。
- 如果 ANOVA 显示显著差异,则使用 LSD 方法进行成对组间的比较,找出哪些组之间存在显著差异。
代码
library(tidyverse)
library(reshape2)
library(broom)
library(DescTools) #事后比较(post-hoc comparison)
library(car) #leveneTest方差齐性检验
library(ggbreak) #截断坐标轴
library(ggpubr) #添加显著性标记
library(ggprism)
data = readxl::read_xlsx("/home/Graph/bar_plot/data-LSD.xlsx")
# 宽数据转换成长数据
# 使用factor固定绘图顺序,并使用mutate创建新变量
data_long <- melt(data, id=c('group','treat')) %>%
mutate(group = factor(group, levels=c("Control", "1.0 mM SA")),
treat = factor(treat, levels = c("Wild type", "TbCSB βC1-line1", "TbCSB βC1-line3")))
# 进行 ANOVA 检验和事后比较(post-hoc comparison)
results <- data_long %>%
group_by(group) %>% #按照 group 列,分组进行统计分析
summarise(
levene_test = list(leveneTest(value ~ treat, data = cur_data())), # 进行方差齐性检验
anova = list(aov(value ~ treat, data = cur_data())), #进行方差检验
) %>%
mutate(
multi_compare = map(anova, ~ PostHocTest(.x, method = c("lsd"))), #进行LSD检验
)
# 提取方差齐性检验结果
levene_results <- results %>%
transmute(group, levene_df = map(levene_test, broom::tidy)) %>%
unnest(cols = levene_df) # 展开成平铺格式
print(levene_results)
# 提取 ANOVA 结果
anova_results <- results %>%
transmute(group, anova_df = map(anova, broom::tidy)) %>%
unnest(cols = anova_df) %>% # 展开成平铺格式
unique()
print(anova_results)
# 提取事后比较结果(LSD)
multi_compare_results <- results %>%
transmute(group, multi_compare_df = map(multi_compare, ~ as.data.frame(.x$treat) %>% rownames_to_column(var = "comparison"))) %>%
unnest(cols = multi_compare_df) %>% # 展开成平铺格式
filter(grepl("Wild type", comparison)) %>% # 按照文章,保留包含 'Wild type' 的比较,如果想要所有比较的结果,直接将这行删除。
mutate(
group1 = "Wild type",
group2 = str_replace(comparison, paste0("-",group1), "")
)
print(multi_compare_results)
# 整理表格:添加显著性标记
data_sig_label <- data_long %>%
rstatix::group_by(group) %>%
rstatix::t_test(value ~ treat, ref.group = "Wild type") %>% # 执行 t 检验,指定 "Wild ,如果想要所有的比较结果,直接将ref.group = "Wild type"删除。type" 作为参考组,即所有其他组将与 "Wild type" 进行比较。
rstatix::adjust_pvalue(p.col = "p", method = "none") %>% # 调整 p 值
rstatix::add_significance(p.col = "p.adj") %>%
rstatix::add_xy_position(x = "group", dodge = 0.8, step.increase = 0.075) %>% #获取位置,用于添加显著性标记
left_join(multi_compare_results,
join_by(group == group, group1 == group1, group2 == group2)) %>% # 连接数据的表格和多重比较的表格
mutate(pval = round(pval, 3), # 保留 3 位小数
p.signif = case_when(pval < 0.05 & pval >= 0.01 ~ "*",
pval < 0.01 & pval >= 0.001 ~ "**",
pval < 0.001 ~ "***",
.default = "n.s.")) # n.s.表示 不显著
##作图
pal = c("#848588", "#e0833c", "#5166af") # 设置颜色
ggplot(data = data_long, aes(x = group, y = value)) +
geom_bar(aes(fill = treat),
stat = "summary", fun = "mean", color = "grey20", #表示条形图展示的是均值
position = position_dodge2(padding = 0.35), width = 0.8,
alpha = 0.6, size = 1, show.legend = FALSE) +
stat_summary(aes(group = treat),
geom = "errorbar",fun.data = "mean_se", #表示添加误差条,计算均值和标准误差
width = 0.25, position = position_dodge(width = 0.8),
size = 1) +
geom_jitter(aes(fill = treat),
position = position_jitterdodge(jitter.width = 0.23), #添加抖动效果,使点不重叠
shape = 21, color = "grey20", size = 2.5, stroke = 0.6) +
stat_pvalue_manual(data_sig_label, label = 'p.signif', #添加显著性标记,并指定用于标签的列名
label.size = 7,
fontface = "bold",
hide.ns = F, #是否隐藏非显著性标记,F表示不隐藏
bracket.size = 1, #设置括号的线条粗细
bracket.nudge.y = -1, #设置括号在y轴方向上的偏移量,负值表示向下偏移
tip.length = 0.05) + #设置括号尖端的长度
scale_fill_manual(values = pal) +
guides(fill = guide_legend(override.aes = list(size = 4.2))) +
scale_y_continuous(limits = c(0, 4000), expand = c(0, 0), breaks = seq(0, 2, 0.5)) +
scale_x_discrete(expand = c(0, 0)) +
labs(y = "Relative expression of PR1a") +
theme_prism() +
theme(axis.title.x = element_blank(),
axis.title.y = element_text(color = 'black',size = 24),
axis.ticks.length = unit(0.25, "cm"),
axis.text.x = element_text(color = 'black',size = 22),
axis.text.y = element_text(color = 'black',size = 22),
axis.line.y.right = element_blank(),
axis.ticks.y.right = element_blank(),
axis.text.y.right = element_blank(),
legend.title = element_blank(),
legend.text = element_text(color = 'black',size = 18),
legend.position = "top") +
scale_y_break(c(2, 100), scales = 1, space = 0.5, #从 2 到 100 之间的区间会被断开
ticklabels = seq(1000, 4000, 1000), expand = FALSE) #指定断轴之后的 y 轴刻度标签
ggsave("/home/Graph/bar_plot/groups-bar-dot-errorbar-break-LSD.png", width = 8, height = 6, dpi = 600)
ggsave("/home/Graph/bar_plot/groups-bar-dot-errorbar-break-LSD.pdf", width = 8, height = 6)
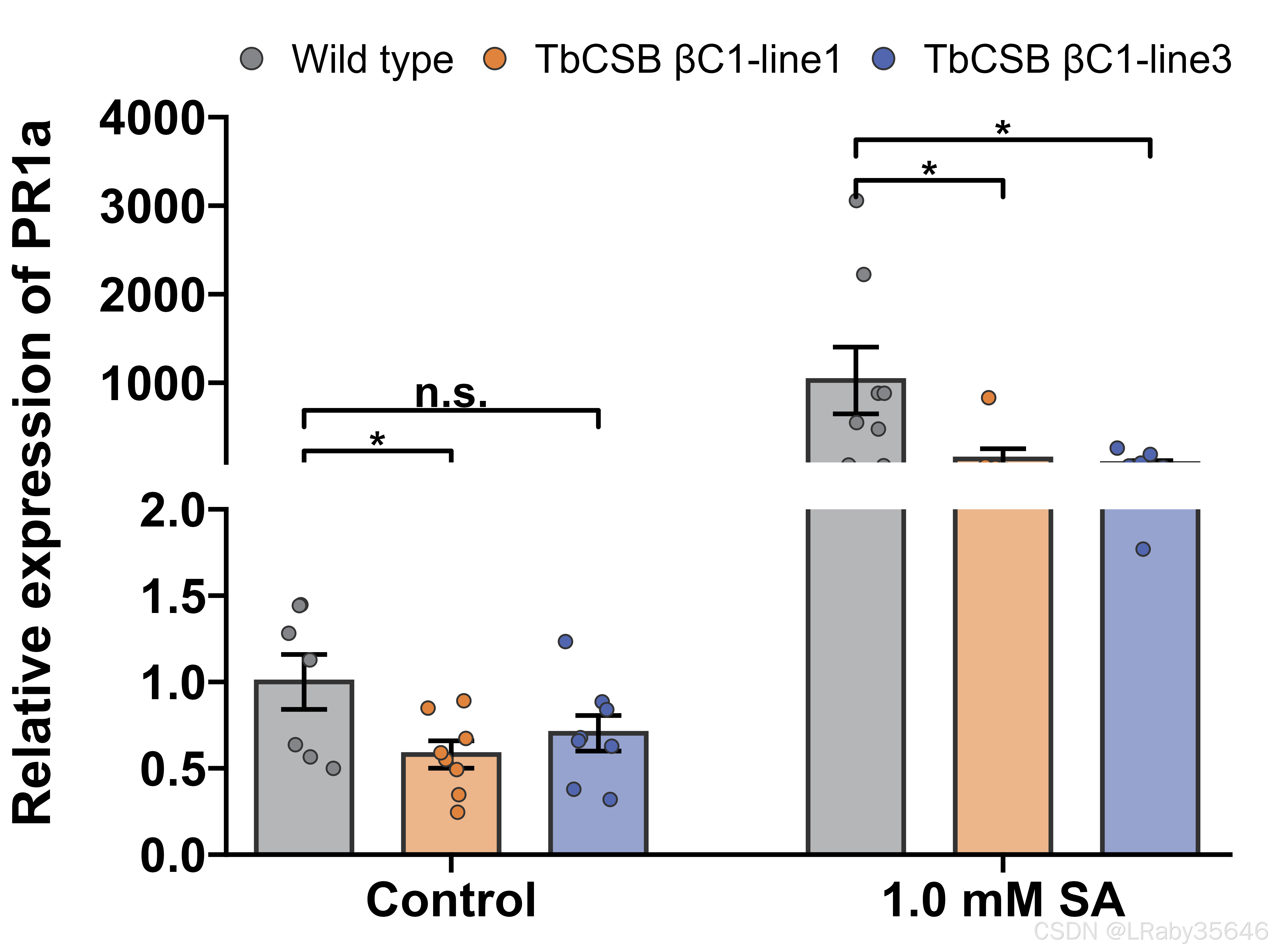
注意🌈:LDS代码中,进行完方差齐性检验之后发现并不是所有的组p>0.05,按理说并不适合后面的ANOVA与LDS(可以使用Welch's ANOVA 或 非参数检验(如 Kruskal-Wallis 检验)),但是只是为了举例,还是进行了后续的分析。
# 整理表格:添加显著性标记
data_sig_label <- data_long %>%
rstatix::group_by(group) %>%
rstatix::t_test(value ~ treat, ref.group = "Wild type") %>% # 执行 t 检验,指定 "Wild type" 作为参考组,即所有其他组将与 "Wild type" 进行比较。
rstatix::adjust_pvalue(p.col = "p", method = "none") %>% # 调整 p 值
rstatix::add_significance(p.col = "p.adj") %>%
rstatix::add_xy_position(x = "group", dodge = 0.8, step.increase = 0.075) %>% #获取位置,用于添加显著性标记
left_join(multi_compare_results,
join_by(group == group, group1 == group1, group2 == group2)) %>% # 连接数据的表格和多重比较的表格
mutate(pval = round(pval, 3), # 保留 3 位小数
p.signif = case_when(pval < 0.05 & pval >= 0.01 ~ "*",
pval < 0.01 & pval >= 0.001 ~ "**",
pval < 0.001 ~ "***",
.default = "n.s.")) # n.s.表示 不显著上述代码中p、p.adj与pval有什么关系?
1. p:
p是 原始的 p 值,即 t 检验 得到的未经过调整的 p 值。在rstatix::t_test()中,t 检验会返回 p 值,表示组间均值差异的显著性。- 这就是每次 t 检验计算的 未经调整 的原始 p 值。
2. p.adj:
p.adj是 调整后的 p 值,即通过对原始 p 值进行 多重比较校正 后得到的值。通常会使用 Benjamini-Hochberg(FDR) 或 Bonferroni 校正 等方法来调整 p 值,以减少在多个比较中产生的假阳性率(Type I 错误)。- 在代码中,使用
rstatix::adjust_pvalue(p.col = "p", method = "none")来调整 p 值。method = "none"表示 不进行多重比较校正,即p.adj=p。但是如果你选择其他调整方法(例如method = "bonferroni"或method = "fdr"),则p.adj将与p不同。
3. pval:
pval是 格式化后的 p 值。在mutate(pval = round(pval, 3))中,代码将pval四舍五入到 3 位小数,使其更适合显示。pval最终用于 显著性标记(即p.signif列)来为每个比较结果添加显著性标记(如*,**,***或"n.s.")。pval是经过处理的、用于生成显著性标记的 p 值,通常是调整后的 p 值(p.adj)或者原始 p 值(p)的格式化版本。
3. Dunnett 多重比较与LSD多重比较的区别
1. Dunnett 多重比较:
- Dunnett Test 是一种用于 控制组与实验组之间的比较 的多重比较方法。
- 它的目的是检验所有实验组(即处理组)与 单一控制组(通常是未经处理的对照组)之间的均值差异是否显著。Dunnett 测试相对保守,并通过调整 p 值来减少假阳性率(即误判差异显著的概率)。
- Dunnett Test 特别适用于当你有一个控制组,并且希望将其与多个不同的实验组进行比较时。
示例:
假设你有 4 个组:
- 控制组(DMSO)
- 10nM Veliparib 组
- 50nM Veliparib 组
- 100nM Veliparib 组
使用 Dunnett Test 时,你将仅比较 DMSO 组 与其他组(例如,10nM Veliparib 组, 50nM Veliparib 组, 100nM Veliparib 组)之间的均值差异。
2. LSD 多重比较:
- LSD Test(最小显著差异法)是一种更 宽松 的多重比较方法,它比较所有组之间的均值差异,而不仅限于控制组与实验组的比较。
- LSD 测试在进行多组比较时,假设 方差齐性 和 正态性 假设成立,且每组间的均值差异可以通过计算最小显著差异来判断。它的计算方法比较简单,但相对来说容易受到 Type I 错误(假阳性)的影响。
- LSD Test 可以用于任意两组之间的均值比较,因此它会执行所有可能的两两比较。
示例:
假设你有相同的 4 个组:
- DMSO 组
- 10nM Veliparib 组
- 50nM Veliparib 组
- 100nM Veliparib 组
使用 LSD Test 时,你将会比较所有可能的组间差异,包括:
- DMSO 组 vs 10nM Veliparib 组
- DMSO 组 vs 50nM Veliparib 组
- DMSO 组 vs 100nM Veliparib 组
- 10nM Veliparib 组 vs 50nM Veliparib 组
- 10nM Veliparib 组 vs 100nM Veliparib 组
- 50nM Veliparib 组 vs 100nM Veliparib 组
4. 方差分析(ANOVA)结合+Turkey多重比较
library(tidyverse)
library(reshape2)
library(broom)
library(DescTools) #事后比较(post-hoc comparison)
library(car) #leveneTest方差齐性检验
library(ggbreak) #截断坐标轴
library(ggpubr) #添加显著性标记
library(ggprism)
data = readxl::read_xlsx("/home/Graph/bar_plot/data-LSD.xlsx")
# 宽数据转换成长数据
# 使用factor固定绘图顺序,并使用mutate创建新变量
data_long <- melt(data, id=c('group','treat')) %>%
mutate(group = factor(group, levels=c("Control", "1.0 mM SA")),
treat = factor(treat, levels = c("Wild type", "TbCSB βC1-line1", "TbCSB βC1-line3")))
# 进行 ANOVA 检验和事后比较(post-hoc comparison)
results <- data_long %>%
group_by(group) %>% #按照 group 列,分组进行统计分析
summarise(
levene_test = list(leveneTest(value ~ treat, data = cur_data())), # 进行方差齐性检验
anova = list(aov(value ~ treat, data = cur_data())), #进行方差检验
) %>%
mutate(
multi_compare = map(anova, ~ TukeyHSD(.x)) # 使用 Tukey 多重比较
)
# 提取方差齐性检验结果
levene_results <- results %>%
transmute(group, levene_df = map(levene_test, broom::tidy)) %>%
unnest(cols = levene_df) # 展开成平铺格式
print(levene_results)
# 提取 ANOVA 结果
anova_results <- results %>%
transmute(group, anova_df = map(anova, broom::tidy)) %>%
unnest(cols = anova_df) %>% # 展开成平铺格式
unique()
print(anova_results)
# 提取事后比较结果(Tukey)
multi_compare_results <- results %>%
transmute(group, multi_compare_df = map(multi_compare, ~ as.data.frame(.x$treat) %>% rownames_to_column(var = "comparison"))) %>%
unnest(cols = multi_compare_df) %>% # 展开成平铺格式
mutate(
group1 = str_extract(comparison, "^[^\\-]+"), # 提取 group1
group2 = str_extract(comparison, "(?<=\\-).+$") # 提取 group2
)
print(multi_compare_results)
# 整理表格:添加显著性标记
data_sig_label <- data_long %>%
rstatix::group_by(group) %>%
rstatix::t_test(value ~ treat) %>% # 执行 t 检验,不指定 ref.group,允许对所有组进行两两比较
rstatix::adjust_pvalue(p.col = "p", method = "none") %>% # 调整 p 值
rstatix::add_significance(p.col = "p.adj") %>%
rstatix::add_xy_position(x = "group", dodge = 0.8, step.increase = 0.075) %>% # 获取位置,用于添加显著性标记
left_join(multi_compare_results,
join_by(group == group, group1 == group1, group2 == group2)) %>% # 连接数据的表格和多重比较的表格
mutate(pval = round(pval, 3), # 保留 3 位小数
p.signif = case_when(pval < 0.05 & pval >= 0.01 ~ "*",
pval < 0.01 & pval >= 0.001 ~ "**",
pval < 0.001 ~ "***",
.default = "n.s.")) # n.s.表示不显著
# 作图
pal = c("#848588", "#e0833c", "#5166af") # 设置颜色
ggplot(data = data_long, aes(x = group, y = value)) +
geom_bar(aes(fill = treat),
stat = "summary", fun = "mean", color = "grey20", #表示条形图展示的是均值
position = position_dodge2(padding = 0.35), width = 0.8,
alpha = 0.6, size = 1, show.legend = FALSE) +
stat_summary(aes(group = treat),
geom = "errorbar",fun.data = "mean_se", #表示添加误差条,计算均值和标准误差
width = 0.25, position = position_dodge(width = 0.8),
size = 1) +
geom_jitter(aes(fill = treat),
position = position_jitterdodge(jitter.width = 0.23), #添加抖动效果,使点不重叠
shape = 21, color = "grey20", size = 2.5, stroke = 0.6) +
stat_pvalue_manual(data_sig_label, label = 'p.signif', # 添加显著性标记,并指定用于标签的列名
label.size = 7,
fontface = "bold",
hide.ns = F, # 是否隐藏非显著性标记,F表示不隐藏
bracket.size = 1, # 设置括号的线条粗细
bracket.nudge.y = -1, # 设置括号在y轴方向上的偏移量,负值表示向下偏移
tip.length = 0.05) + # 设置括号尖端的长度
scale_fill_manual(values = pal) +
guides(fill = guide_legend(override.aes = list(size = 4.2))) +
scale_y_continuous(limits = c(0, 4000), expand = c(0, 0), breaks = seq(0, 2, 0.5)) +
scale_x_discrete(expand = c(0, 0)) +
labs(y = "Relative expression of PR1a") +
theme_prism() +
theme(axis.title.x = element_blank(),
axis.title.y = element_text(color = 'black',size = 24),
axis.ticks.length = unit(0.25, "cm"),
axis.text.x = element_text(color = 'black',size = 22),
axis.text.y = element_text(color = 'black',size = 22),
axis.line.y.right = element_blank(),
axis.ticks.y.right = element_blank(),
axis.text.y.right = element_blank(),
legend.title = element_blank(),
legend.text = element_text(color = 'black',size = 18),
legend.position = "top") +
scale_y_break(c(2, 100), scales = 1, space = 0.5, # 从 2 到 100 之间的区间会被断开
ticklabels = seq(1000, 4000, 1000), expand = FALSE) # 指定断轴之后的 y 轴刻度标签
ggsave("/home/Graph/bar_plot/groups-bar-dot-errorbar-break-Tukey.png", width = 8, height = 6, dpi = 600)
ggsave("/home/Graph/bar_plot/groups-bar-dot-errorbar-break-Tukey.pdf", width = 8, height = 6)
LSD(Least Significant Difference) 和 Tukey HSD(Honestly Significant Difference) 其实是非常相似的多重比较方法,它们都是用来比较多个组之间的均值差异的 事后检验(post-hoc tests)。它们的主要区别在于 控制多重比较问题 的方式以及适用的场景。
LSD 与 Tukey 的相似之处:
- 目的相同:两者都是用来 比较多个组之间的差异,并通过计算每对组之间的均值差异来判断显著性。
- 都适用于方差分析(ANOVA)后:这两种方法通常用于 ANOVA 检验之后,当你有多个组,并希望进一步分析哪些组之间有显著差异时。
主要区别:
- 多重比较控制:
- LSD 方法 不进行多重比较校正,因此 容易产生假阳性(Type I 错误),特别是在进行多个比较时。
- Tukey 方法则 会校正多重比较带来的错误,通过使用 更严格的统计标准 来避免在多个比较中错误地发现显著性。
适用场景:
-
LSD:
- 适用于比较较少组数,或者组数较少且你不需要非常严格控制假阳性率的情况。它的优点是 计算简单,并且结果的敏感性较高(容易发现显著差异)。
- 比如,如果你只有 2 或 3 个组,那么 LSD 可能就足够用了。
-
Tukey:
- 适用于组数较多的情况,尤其是在有多个组时,Tukey 方法能够有效控制多重比较的假阳性风险,避免出现错误的显著性。
- 比如,当你有 5 个或更多的组时,Tukey HSD 就比 LSD 更合适,因为它控制了 Type I 错误。

















 1507
1507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









