







 该博客介绍了如何在R中进行单因素非参数差异检验,包括Kruskal-Wallis检验和Dunn test多重比较,并展示了如何使用rcompanion包添加显著性字母标记。通过实例展示了数据准备、差异检验过程以及结果的图形化展示,包括柱形图和箱型图。最后提供了相关代码和数据资源。
该博客介绍了如何在R中进行单因素非参数差异检验,包括Kruskal-Wallis检验和Dunn test多重比较,并展示了如何使用rcompanion包添加显著性字母标记。通过实例展示了数据准备、差异检验过程以及结果的图形化展示,包括柱形图和箱型图。最后提供了相关代码和数据资源。
一、 数据准备
数据包括36个样本,4个处理,7个环境因子,研究目的是为了比较处理间每个环境因子是否存在差异。
# 1.1 设置工作路径
setwd("D:\\EnvStat\\stat")
getwd()#获取工作路径
# 1.2 导入数据
env = read.csv("env.csv",header = TRUE,row.names = 1,stringsAsFactors = FALSE)
dim(env)
head(env) # 第一列为分组信息,2-8列为环境因子数据
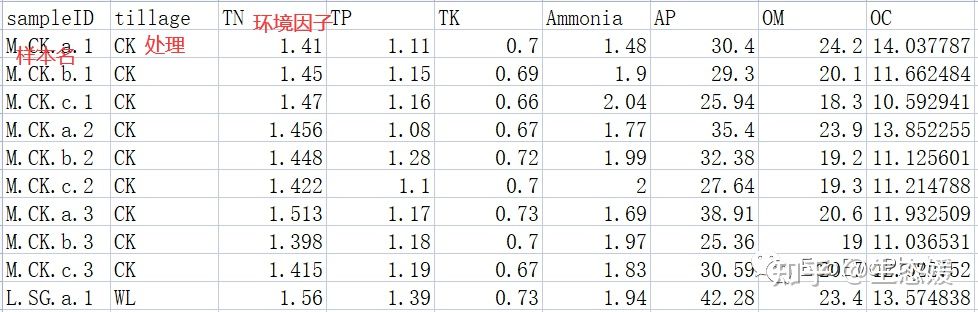
图1|环境因子及分组信息表,env.csv。行为样品名称,列为环境因子名称和分组信息,共有7个环境变量,1个分组信息。
二、 组间差异检验
2.1 单因素非参数差异检验-Kruskal-Wallis rank sum test
library(rstatix)
library(dplyr)
# 批量对7个环境因子进行kruskal-Wallis检验
for (i in 2:8){
assign(paste(names(env[i]),"kw",sep="."),kruskal.test(env[,i],as.factor(env[,1])))
} # assign()将kruskal.test()的运行结果赋予指定变量名
kw = mget(paste(names(env[2:8]),"kw",sep=".")) # mget()提取变量值到kw对象
kw # 列表对象
# 将结果输出到本地
capture.output(kw,file = "kw.list.txt",append = FALSE)

图2|Kruskal-Wallis检验结果。kw列表中包含7个环境因子的kruskal-wallis检验结果。
2.2 多重比较
在R统计-多变量单因素参数、非参数检验及多重比较和R统计-多变量双因素参数、非参数检验及多重比较文章中都写过多重比较方法,这里就不详述了。这里使用FSA包的dunnTest函数进行Dunn test多重比较。
library(FSA)
# 批量对7个环境因子进行Dunn test多重比较
for (i in 2:8){
assign(paste(names(env[i]),"Dunn",sep = "."), dunnTest(env[,i], as.factor(env[,1]),
method="bh")$res); # p值校正选择bh方法。
}
dunn = mget(paste(names(env[2:8]),"Dunn",sep = "."))
dunn$TN.Dunn
# 将结果输出到本地
capture.output(dunn,file = "dunn.list.txt",append = FALSE)
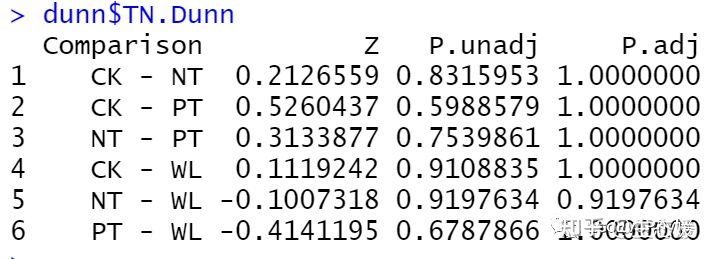
图3|Dunn test多重比较检验结果。dunn列表中包含7个环境因子的检验结果。
2.3 添加显著性字母标记
每个环境因子,包含4个处理,所以使用不同字母表示处理间的显著差异。同一环境因子具有相同字母处理间差异不显著。使用rcompanion包的cldList根据多重比较检验结果自动设置字符标记。
library(rcompanion)
# 字符标记,rcompanion包的cldList可以根据多重比较检验结果自动设置字符标记
for (i in 1:7){
assign(paste(names(dunn[i]),"mark",sep="."),
cldList(P.adj ~ Comparison,
data = dunn[[i]],
threshold = 0.05)) # 设置显著性差异p值的阈值
}
dunn_mark = mget(p 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 180
180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











