







| 论文标题 | EfficientNetV2: Smaller Models and Faster Training |
|---|---|
| 论文作者 | Mingxing Tan, Quoc V. Le |
| 发表日期 | 2021年01月01日 |
| GB引用 | > Mingxing Tan, Quoc V Le. EfficientNetV2: Smaller Models and Faster Training[J]. International Conference on Machine Learning, 2021, 139:10096-10106. |
| DOI | 10.48550/arXiv.2104.00298 |
论文地址:https://proceedings.mlr.press/v139/tan21a/tan21a.pdf
摘要
本文介绍了EfficientNetV2,一种新的卷积网络家族,其训练速度更快且参数效率更高。通过结合训练感知神经架构搜索和缩放技术,优化了训练速度和参数效率。EfficientNetV2模型通过搜索包含新操作如Fused-MBConv的空间来设计。实验表明,EfficientNetV2在训练速度上比最先进的模型快4倍,参数量减少6.8倍。此外,提出了一种改进的渐进学习方法,能自适应调整正则化强度,从而提高训练速度和准确性。EfficientNetV2在ImageNet和CIFAR/Cars/Flowers数据集上取得了显著成果,在预训练后达到了87.3%的准确率,比最近的ViT-L/16模型快5到11倍。
全文摘要
该论文介绍了EfficientNetV2,一个新的卷积网络家族,旨在提高训练速度和参数效率。研究者结合了以训练为导向的神经架构搜索(NAS)和扩展技术,从而共同优化训练速度和模型效率。与以前的模型相比,EfficientNetV2模型在训练速度上提高了多达4倍,且参数量减少至多6.8倍。论文还提出了一种改进的逐步学习方法,通过逐渐增加图像尺寸和自适应调整正则化手段,以提升模型在不同图像尺寸下的表现。
主要结论
- 训练效率提升:EfficientNetV2通过研究之前EfficientNets的训练瓶颈,优化了模型架构并引入了新的操作,如Fused-MBConv,从而有效提高了训练速度和性能。
- 逐步学习方法:改进的逐步学习方法能有效抵消由于增大图像尺寸而引起的准确率下降,通过动态调整正则化技术来提高训练效果,显示出更好的准确性与效率。
- 实验结果:在ImageNet和其他数据集上,EfficientNetV2模型的Top-1准确率达到了87.3%,显著优于以前的模型,包括ViT,并且所需的训练时间减少了5到11倍。
独特之处
EfficientNetV2的核心创新在于综合应用了训练-aware的神经架构搜索和动态正则化的逐步学习方法,这是其相较于之前模型的主要进步。同时,通过更小的模型结构和更快的训练效率,EfficientNetV2证明了在图像识别领域卷积网络仍能与更大、更复杂的Transformer模型竞争,展示了卷积神经网络在效率和准确性上的潜力。
研究问题
如何通过结合训练感知的神经架构搜索和缩放技术来设计更小且训练速度更快的模型?
研究方法
实验研究: 通过训练-aware神经架构搜索和缩放技术联合优化训练速度和参数效率,设计了新的EfficientNetV2模型。这些模型在保持参数效率的同时,显著提高了训练速度。
混合方法研究: 结合了训练-aware神经架构搜索和缩放策略来优化模型的准确性、训练速度和参数大小。通过非均匀缩放策略逐渐增加后期阶段的层数,并使用自适应正则化调整训练过程中的图像大小和正则化强度。
模拟研究: 通过逐步调整训练过程中的图像大小和正则化强度,验证了改进后的渐进学习方法的有效性。该方法允许网络在早期训练阶段学习简单的表示,并随着训练的进行逐渐增加图像大小和正则化强度。
元分析: 通过对多个模型的性能进行综合分析,展示了EfficientNetV2系列模型在ImageNet和CIFAR等数据集上的表现优于之前的模型。
研究思路
论文“EfficientNetV2: Smaller Models and Faster Training”提出了一个新的卷积网络家族,即EfficientNetV2,旨在提高模型的训练速度和参数效率。以下是该论文的研究思路详细描述,包括理论框架、研究方法和创新点。
理论框架和模型
- 理论基础:EfficientNetV2的核心理论基础是通过联合优化训练速度和参数效率来设计神经网络。论文借鉴了先前在高效神经网络设计方面的研究(如EfficientNet系列),并提出了一种新的方法,将训练感知的神经架构搜索(NAS)与模型缩放相结合。
- 模型设计:EfficientNetV2模型在确定结构时,加入了新的操作(例如Fused-MBConv),优化了网络的学习能力,极大地减少了模型规模,同时提高了训练效率。模型在充分考虑了不同层的特征提取能力及其对训练速度的影响后,进行了一系列创新设计。
研究方法
- 训练感知的神经架构搜索(NAS):利用NAS技术,研究团队对网络架构进行了调优,旨在找到最优的网络结构,既能达到较高的准确率,又能提高训练速度。NAS搜索空间包括不同的卷积操作类型、层数、卷积核大小等,选择最佳组合来生成新模型。
- 非均匀缩放策略:相较于传统的均匀缩放方法,EfficientNetV2采用了非均匀缩放策略。在模型缩放阶段,逐步在后期阶段添加更多的层,以此来提高网络容量而不增加过多的计算开销,确保训练速度和参数效率的最佳平衡。
- 改进的渐进学习方法:在训练过程中,该方法逐步增加输入图像的尺寸,同时调整正则化强度。通过在早期阶段使用小图像和较弱的正则化,帮助网络学习简单的特征表达;然后在后期阶段逐渐增大图像尺寸并增加正则化强度,从而避免过拟合,提升精度。
EfficientNet回顾
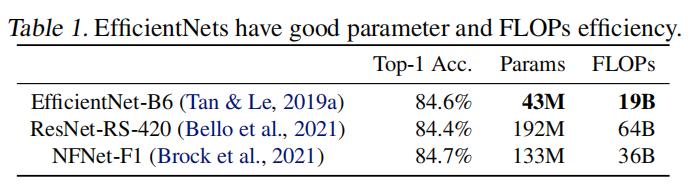
Efficentnet (Tan & Le,2019a) 是一个针对FLOPs和参数效率进行优化的模型家族。它利用NAS来搜索基准EfficientNet-B0,在准确性和FLOPs方面具有更好的权衡。然后使用复合缩放策略对基线模型进行缩放,以获得一系列模型B1-B7。虽然最近的工作声称在训练或推理速度方面有很大的进步,但在参数和FLOPs效率方面,它们通常不如EfficientNet (表1)。在本文中,我们旨在提高训练速度的同时保持参数效率。
理解训练效率
我们研究了EfficientNet(Tan & Le,2019a)的训练瓶颈,即以后称为EfficientNetV1,并提出了一些简单的方法来提高训练速度。
使用非常大的图像大小进行训练很慢:正如之前的工作所指出的那样 (Radosavovic等人,2020),EfficientNet 的大图像尺寸导致显著的内存使用。由于GPU/TPU上的总内存是固定的,我们必须用较小的批处理大小训练这些模型,这大大减慢了训练速度。一个简单的改进是应用修复 (Touvron等人,2019),通过使用比推理更小的图像尺寸进行训练。如表2所示,图像尺寸越小,计算量越少,批量大小就越大,因此训练速度最多可提高2.2倍。值得注意的是,正如 (Touvron等人,2020; Brock等人,2021) 所指出的,使用较小的图像尺寸进行训练也可以带来略好的准确性。但与 (Touvron等人,2019) 不同的是,我们在训练后不会微调任何层。

我们将探索一种更先进的训练方法,通过在训练过程中逐步调整图像的大小和正则化。
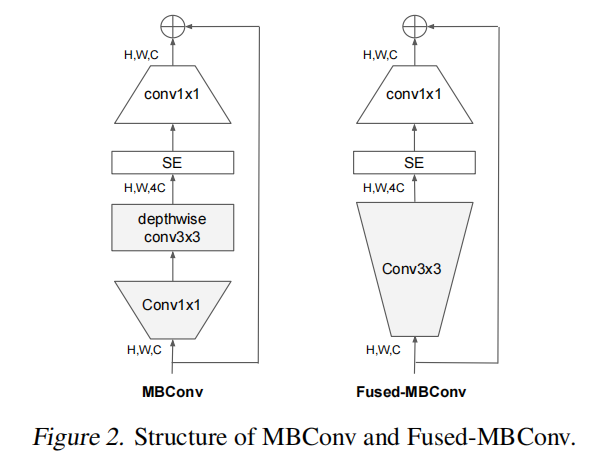
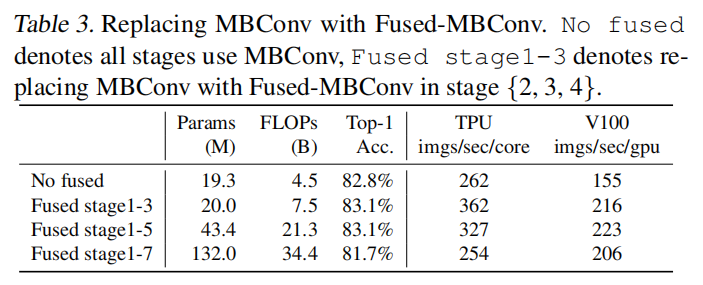
深度卷积在早期层中速度慢,但在后期阶段效果显著:EfficientNet 的另一个训练瓶颈来自广泛的深度卷积 (Sifre,2014)。深度卷积比常规卷积具有更少的参数和FLOPs,但它们通常不能充分利用现代加速器。最近,Fused-MBConv 在 (Gupta & Tan,2019) 中被提出,后来在 (Gupta & Akin,2020; 熊等人,2020; Li等人,2021) 中使用。更好地利用移动或服务器加速器。它将 MBConv中 的深度conv3x3和扩展conv1x1 (Sandler等人,2018; Tan & Le,2019a) 替换为单个常规conv3x3,如图2所示。为了系统地比较这两个构建块,我们逐渐用 Fused-MBConv 取代了原始的 EfficientNet-B4 MBConv (表3)。当应用于早期1-3阶段时,Fused-MBConv 可以通过较小的参数和 FLOPs 开销来提高训练速度,但是如果我们用 Fused-MBConv (阶段1-7) 替换所有块,那么它会显着增加参数和失败,同时也会减慢训练速度。找到这两个构建块 (MBConv 和 Fused-MBConv) 的正确组合并非易事,这促使我们利用神经架构搜索自动搜索最佳组合。
同样扩大每个阶段是次优的:EfficientNet 使用简单的复合缩放规则来等比例地放大所有阶段。例如,当深度系数为2时,网络中的所有阶段都会将层数加倍。但是,这些阶段对训练速度和参数效率的贡献并不相同。本文将采用非均匀缩放策略,逐步增加后期阶段的层数。此外,EfficientNets 激进地扩大图像尺寸,导致内存消耗大且训练缓慢。为了解决这个问题,我们稍微修改了缩放规则,并限制最大图像大小到较小值。
训练感知的NAS和缩放
为此,我们学习了多种提高训练速度的设计选择。为了搜索这些选项的最佳组合,我们现在提出了一种训练感知的NAS。
NAS搜索:我们的训练感知 NAS 框架很大程度上基于以前的 NAS 作品 (Tan et al.,2019; Tan & Le,2019a),但旨在共同优化准确性,参数效率,以及现代加速器的培训效率。特别是,我们使用高效网络作为我们的支柱。我们的搜索空间是一个基于阶段的因子分解空间,类似于 (Tan等人,2019),它包括卷积操作类型 {MBConv,Fused-MBConv} 的设计选择。层数,内核大小 {3 x3,5 x5},扩展比 {1,4,6}。另一方面,我们通过
(1) 删除不必要的搜索选项,如池化跳跃操作,因为它们从未在原始的 EfficientNets 中使用;
(2) 减少了搜索空间的大小。
从骨干重复使用已经在 (Tan & Le,2019a) 中搜索的相同信道大小。由于搜索空间更小,我们可以应用强化学习 (Tan et al.,2019),或者在大小与 EfficientNet-B4 相当的更大的网络上进行简单的随机搜索。具体来说,我们最多采样1000个模型,并在训练图像尺寸减小的情况下训练每个模型大约10个epochs。我们的搜索奖励结合了模型精度 A A A、标准化训练步长时间 S S S和参数大小 P P P,使用简单的加权乘积 A ⋅ S w ⋅ P v A\cdot S^{w}\cdot P^{v} A⋅Sw⋅Pv,其中, w = − 0.07 w =-0.07 w=−0.07和 v = − 0.05 v =-0.05 v
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 9960
9960

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











