






编程基础很弱,需要机器学习,学习记录,按自己理解写的,希望以后能学懂吧,要是有大神看到还请赐教。
torchvision中的数据集使用
dataset和transforms联合使用
首先,怎么下载给定的数据集CIFAR10。
实际是先下载一个压缩文件,然后对压缩文件进行一个解压。
import torchvision
cifar_path = "D:\\Scientific_Research\\Pycharmproject\\Biji\\dataset"
train_set = torchvision.datasets.CIFAR10(root=cifar_path, train=True, download=True)
test_set = torchvision.datasets.CIFAR10(root=cifar_path, train=False, download=True)
# 查看下载数据集
print(test_set[0]) # 运行会发现和前面课程中dataset那种式的,是一个元组。
# 使用Debug看看啥样
# 不太会这里就接着往下边写
print(test_set.classes) # 运行查看是一个列表,里面是数据集中的图片标签。
# 既然是元组,可以使用这样的方法来赋值。
img, target = test_set[0]
print(img)
print(target)
# 发现target为3而非具体类别
print(test_set.classes[3]) # 运行发现3对应‘cat’
CIFAR10数据集简介:
包含6w张32*32的彩色图,共分为10个类别,每个类别6k张图像。5w张图像为训练图,1w为测试图。
由于CIFAR10中的图片为PIL,在Pytorch使用需要转化为tensor数据类型。因此需要与transforms联合使用。
import torchvision
# 联合transforms使用。
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
# 接下来更改通过设置transform进行联合加载数据集
cifar_path = "D:\\Scientific_Research\\Pycharmproject\\Biji\\dataset"
train_set = torchvision.datasets.CIFAR10(root=cifar_path, train=True, download=True,transform=dataset_transform)
test_set = torchvision.datasets.CIFAR10(root=cifar_path, train=False, download=True,transform=dataset_transform)
# 再看看数据集是什么类型
print(type(test_set[0]))
# 既然是tensor就可以放入tensorboard,复习一下。
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs")
for i in range(10):
img, target = test_set[i]
writer.add_image("CIFAR10数据集", img, i)
writer.close()DataLoader的使用
dataset相当于扑克牌,dataloader从dataset中取数据到神经网络中,相当于抓牌。
DataLoader的一些参数:
batch_size:一次抓几张牌。
shuffle:是否打乱顺序,重新洗牌。
number_workers:加载数据选择多少个进程。
drop_last:当有余下的牌时是否舍去。
# 看 CIFAR10中数据集返回的是啥,Ctrl左键CIFAR10看帮助,里边__getitem__返回的是啥。
# DataLoader
import torchvision
from torch.utils.data import DataLoader
cifar_path = "D:\\Scientific_Research\\Pycharmproject\\Biji\\dataset"
test_data = torchvision.datasets.CIFAR10(root=cifar_path, train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# 加载测试集
test_loader = DataLoader(dataset=test_data, batch_size=4, shuffle=True, num_workers=0, drop_last=False)
# 查看测试数据集第一张图片及target
img, target = test_data[0]
print(img.shape)
print(target)
# 此处batch_size=4 指取0123 并进行打包,返回imgs和targets。
# 那么怎么取出test_loader中的返回呢
for data in test_loader:
imgs,targets=data
print(imgs.shape)
print(targets)接下来讲解了取样Sample及batch64输入tensorboard循环,代码如下:
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
cifar_path = "D:\\Scientific_Research\\Pycharmproject\\Biji\\dataset"
test_data = torchvision.datasets.CIFAR10(root=cifar_path, train=False, transform=torchvision.transforms.ToTensor(),
download=True)
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=False)
step = 0
for data in test_loader:
imgs, targets = data
writer = SummaryWriter("logs")
writer.add_images("batch64", imgs, step)
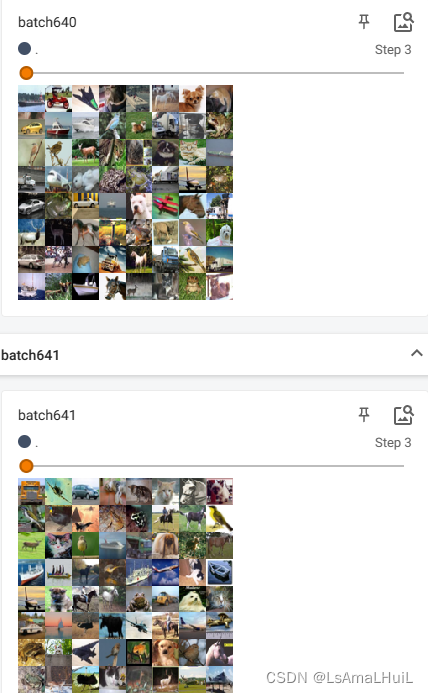
step += 1分两轮选取数据,并演示shuffle为True或False的区别,代码如下:
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
cifar_path = "D:\\Scientific_Research\\Pycharmproject\\Biji\\dataset"
test_data = torchvision.datasets.CIFAR10(root=cifar_path, train=False, transform=torchvision.transforms.ToTensor(),
download=True)
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=False)
for i in range(2):
step = 0
for data in test_loader:
imgs, targets = data
writer = SummaryWriter("logs")
writer.add_images("batch64{}".format(i), imgs, step)
step += 1
可以看到,当shuffle为True时,两次循环选取图片不一样。















 149
149











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









