






一、什么是multi-label?
多标签分类(Multilabel classification): 给每个样本一系列的目标标签,即表示的是样本各属性而不是相互排斥的。比如图片中的猫可同时拥有两个标签cat、animal,需要预测出一个概念集合。
2.一般思路如何实现multi-label任务?
要实现这个任务,一种是使用多个模型,可以并行使用两个模型分别预测同一个物体,每个模型对该物体的预测不同。即一个模型预测图片中的猫为cat,另一个预测其为animal。这种方法比较简单实用,但可能满足不了一些场合的单一模型推理要求。
一种是专门设计一个网络同时对物体带有的多个标签进行训练,设计思路:
1.从网络的数据集、输入、损失函数、标签分配策略进行修改。
2.类似multi-task网络的形式,对网络输出做分支并行。
(两种实现方法并不是本文所讲述主题,一言带过~)
二、yolov8中nms函数的multi-label
首先放一段v8中nms源码:
def non_max_suppression(
prediction,
conf_thres=0.25,
iou_thres=0.45,
classes=None,
agnostic=False,
multi_label=False,
labels=(),
max_det=300,
nc=0, # number of classes (optional)
max_time_img=0.05,
max_nms=30000,
max_wh=7680,
):
"""
Perform non-maximum suppression (NMS) on a set of boxes, with support for masks and multiple labels per box.
Args:
prediction (torch.Tensor): A tensor of shape (batch_size, num_classes + 4 + num_masks, num_boxes)
containing the predicted boxes, classes, and masks. The tensor should be in the format
output by a model, such as YOLO.
conf_thres (float): The confidence threshold below which boxes will be filtered out.
Valid values are between 0.0 and 1.0.
iou_thres (float): The IoU threshold below which boxes will be filtered out during NMS.
Valid values are between 0.0 and 1.0.
classes (List[int]): A list of class indices to consider. If None, all classes will be considered.
agnostic (bool): If True, the model is agnostic to the number of classes, and all
classes will be considered as one.
multi_label (bool): If True, each box may have multiple labels.
labels (List[List[Union[int, float, torch.Tensor]]]): A list of lists, where each inner
list contains the apriori labels for a given image. The list should be in the format
output by a dataloader, with each label being a tuple of (class_index, x1, y1, x2, y2).
max_det (int): The maximum number of boxes to keep after NMS.
nc (int, optional): The number of classes output by the model. Any indices after this will be considered masks.
max_time_img (float): The maximum time (seconds) for processing one image.
max_nms (int): The maximum number of boxes into torchvision.ops.nms().
max_wh (int): The maximum box width and height in pixels
Returns:
(List[torch.Tensor]): A list of length batch_size, where each element is a tensor of
shape (num_boxes, 6 + num_masks) containing the kept boxes, with columns
(x1, y1, x2, y2, confidence, class, mask1, mask2, ...).
"""
# Checks
assert 0 <= conf_thres <= 1, f'Invalid Confidence threshold {conf_thres}, valid values are between 0.0 and 1.0'
assert 0 <= iou_thres <= 1, f'Invalid IoU {iou_thres}, valid values are between 0.0 and 1.0'
if isinstance(prediction, (list, tuple)): # YOLOv8 model in validation model, output = (inference_out, loss_out)
prediction = prediction[0] # select only inference output
device = prediction.device
mps = 'mps' in device.type # Apple MPS
if mps: # MPS not fully supported yet, convert tensors to CPU before NMS
prediction = prediction.cpu()
bs = prediction.shape[0] # batch size
nc = nc or (prediction.shape[1] - 4) # number of classes
nm = prediction.shape[1] - nc - 4
mi = 4 + nc # mask start index
xc = prediction[:, 4:mi].amax(1) > conf_thres # candidates
# Settings
# min_wh = 2 # (pixels) minimum box width and height
time_limit = 0.5 + max_time_img * bs # seconds to quit after
multi_label &= nc > 1 # multiple labels per box (adds 0.5ms/img)
prediction = prediction.transpose(-1, -2) # shape(1,84,6300) to shape(1,6300,84)
prediction[..., :4] = xywh2xyxy(prediction[..., :4]) # xywh to xyxy
t = time.time()
output = [torch.zeros((0, 6 + nm), device=prediction.device)] * bs
for xi, x in enumerate(prediction): # image index, image inference
# Apply constraints
# x[((x[:, 2:4] < min_wh) | (x[:, 2:4] > max_wh)).any(1), 4] = 0 # width-height
x = x[xc[xi]] # confidence
# Cat apriori labels if autolabelling
if labels and len(labels[xi]):
lb = labels[xi]
v = torch.zeros((len(lb), nc + nm + 4), device=x.device)
v[:, :4] = xywh2xyxy(lb[:, 1:5]) # box
v[range(len(lb)), lb[:, 0].long() + 4] = 1.0 # cls
x = torch.cat((x, v), 0)
# If none remain process next image
if not x.shape[0]:
continue
# Detections matrix nx6 (xyxy, conf, cls)
box, cls, mask = x.split((4, nc, nm), 1)
if multi_label:
i, j = torch.where(cls > conf_thres)
x = torch.cat((box[i], x[i, 4 + j, None], j[:, None].float(), mask[i]), 1)
else: # best class only
conf, j = cls.max(1, keepdim=True)
x = torch.cat((box, conf, j.float(), mask), 1)[conf.view(-1) > conf_thres]
# Filter by class
if classes is not None:
x = x[(x[:, 5:6] == torch.tensor(classes, device=x.device)).any(1)]
# Check shape
n = x.shape[0] # number of boxes
if not n: # no boxes
continue
if n > max_nms: # excess boxes
x = x[x[:, 4].argsort(descending=True)[:max_nms]] # sort by confidence and remove excess boxes
# Batched NMS
c = x[:, 5:6] * (0 if agnostic else max_wh) # classes
boxes, scores = x[:, :4] + c, x[:, 4] # boxes (offset by class), scores
i = torchvision.ops.nms(boxes, scores, iou_thres) # NMS
i = i[:max_det] # limit detections
# # Experimental
# merge = False # use merge-NMS
# if merge and (1 < n < 3E3): # Merge NMS (boxes merged using weighted mean)
# # Update boxes as boxes(i,4) = weights(i,n) * boxes(n,4)
# from .metrics import box_iou
# iou = box_iou(boxes[i], boxes) > iou_thres # iou matrix
# weights = iou * scores[None] # box weights
# x[i, :4] = torch.mm(weights, x[:, :4]).float() / weights.sum(1, keepdim=True) # merged boxes
# redundant = True # require redundant detections
# if redundant:
# i = i[iou.sum(1) > 1] # require redundancy
output[xi] = x[i]
if mps:
output[xi] = output[xi].to(device)
if (time.time() - t) > time_limit:
LOGGER.warning(f'WARNING ⚠️ NMS time limit {time_limit:.3f}s exceeded')
break # time limit exceeded
return output具体nms如何实现multi-label的预测,可以查看
yolov5 nms详解
但是,值得注意的是,nms其本质是属于一种多余检测框过滤,即将冗余的框按照检测分数选择性过滤。其中实现了所谓的multi-label,因为模型本身对物体进行了预测获取了numclass个数的框,这些框的分数一定是有高低的。将multi-label设置为True,只是将这些框选两个最高分数输出。所以,这就是一个降低阈值的操作,让更多的信息保留下来,实际并不是属于真正multi-label。
有些人可能会觉得,那么既然nms可以对一个物体输出两个类别,那我们只需要在训练准备数据集的时候 ,把一个东西用不同类别标注两遍,然后进行训练,最后使用nms输出两个类别。这样想其实乍一看没什么问题,但模型训练真的是输入两个类别框就能训练两个吗?
众所周知,训练过程需要对预测值pred和真实值target进行loss计算,然后反向传播拟合最优解。要实现两个类别的训练,就需要同时计算两个类别的损失函数,或者损失函数计算时,需要将两个类别同时考虑。那么这个问题就来到yolov8的训练损失函数这块,它是否能够对同一像素的两个类别进行损失函数计算呢?
三、yolov8损失函数计算过程
本文主要讲,detection任务中的损失函数计算过程。分为两个步骤:cls类别损失、bbox检测框损失。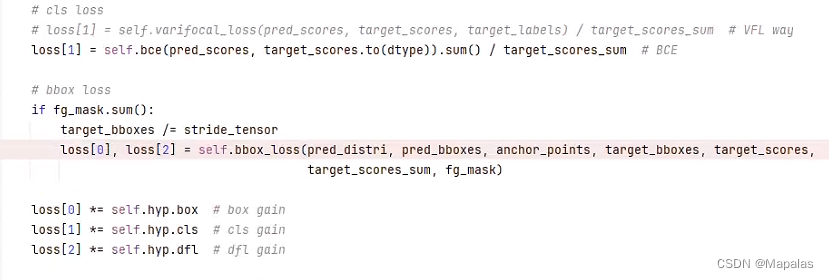
首先看cls_loss类别损失,即 loss[1],它由predscores,targetscores两个输入经过bce损失函数计算得来。那么只需要看这两个参数是否在每个像素拥有两个或以上的类别。直接看targetscores,由非常关键的一步标签分配策略:TaskAlignedAssigner而来。
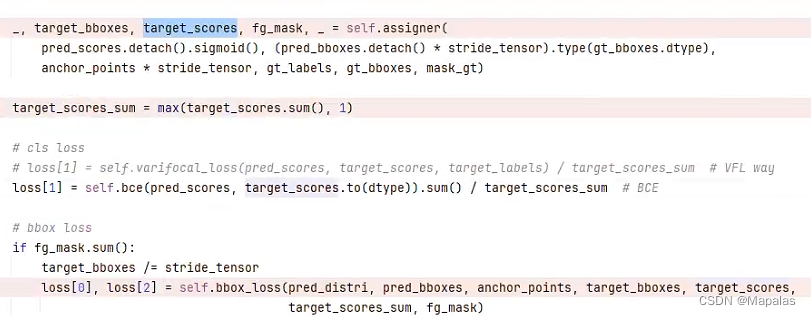

接下来对于详解TaskAlignedAssigner过程,借鉴前人的博客:
TaskAlignedAssigner函数讲解
v8最重要的更新是采取anchor-free的方式,并学习TOOD使用Task-Alignment learning对齐cls与reg任务,那么下面我们对tood的label assignment进行详细解读。
正常对齐的Anchor应当可以预测高分类得分,同时具有精确定位;于此Tood设计了一个新的Anchor alignment metric ,Anchor alignment metric是cls得分以及预测框与GT的IOU相乘得来,将其作为任意anchor的质量评估,在Anchor level 衡量Task-Alignment的水平。并且,Alignment metric 被集成在了 sample 分配和 loss function里来动态的优化每个 Anchor 的预测。
def forward(self, pd_scores, pd_bboxes, anc_points, gt_labels, gt_bboxes, mask_gt):
self.bs = pd_scores.size(0)
self.n_max_boxes = gt_bboxes.size(1)
if self.n_max_boxes == 0:
device = gt_bboxes.device
return (torch.full_like(pd_scores[..., 0], self.bg_idx).to(device), torch.zeros_like(pd_bboxes).to(device),
torch.zeros_like(pd_scores).to(device), torch.zeros_like(pd_scores[..., 0]).to(device),
torch.zeros_like(pd_scores[..., 0]).to(device))
mask_pos, align_metric, overlaps = self.get_pos_mask(pd_scores, pd_bboxes, gt_labels, gt_bboxes, anc_points,
mask_gt)
target_gt_idx, fg_mask, mask_pos = select_highest_overlaps(mask_pos, overlaps, self.n_max_boxes)
# assigned target
target_labels, target_bboxes, target_scores = self.get_targets(gt_labels, gt_bboxes, target_gt_idx, fg_mask)
# normalize
align_metric *= mask_pos
pos_align_metrics = align_metric.amax(axis=-1, keepdim=True) # b, max_num_obj
pos_overlaps = (overlaps * mask_pos).amax(axis=-1, keepdim=True) # b, max_num_obj
# norm_align_metric = (align_metric * pos_overlaps / (pos_align_metrics + self.eps)).amax(-2).unsqueeze(-1)
norm_align_metric = (align_metric / (pos_align_metrics + self.eps)).amax(-2).unsqueeze(-1)
target_scores = target_scores * norm_align_metric
return target_labels, target_bboxes, target_scores, fg_mask.bool(), target_gt_idx
在v8中,label assignment分为3个步骤。首先,根据self.get_pos_mask()计算出正样本的mask,GT与pred_bboxes的iou以及align_metric,其中
align_metric = bbox_scores.pow(self.alpha) * overlaps.pow(self.beta)mask_pos(即正样本的mask)需要通过mask_topk * mask_in_gts * mask_gt相乘获得。mask_in_gts表示在GT内部的mask,GT左上角与右下角的坐标分别与anchor的中心点做差获得bbox_deltas, 当bbox_deltas的值均大于0则说明该点在GT内,即可获得mask_in_gts。
bbox_deltas = torch.cat((xy_centers[None] - lt, rb - xy_centers[None]), dim=2).view(bs, n_boxes, n_anchors, -1)mask_topk 这个很好理解,就是align_metric的topk。align_metric同时考虑了cls与reg,因此可以更好的对齐cls与reg两个任务。cls与reg是模型预测值,两者结合可以很好的估计出该GT在哪些grid表现优秀,用align_metric的topk来选正样本点更为合理。
def get_pos_mask(self, pd_scores, pd_bboxes, gt_labels, gt_bboxes, anc_points, mask_gt):
# get anchor_align metric, (b, max_num_obj, h*w)
align_metric, overlaps = self.get_box_metrics(pd_scores, pd_bboxes, gt_labels, gt_bboxes)
# get in_gts mask, (b, max_num_obj, h*w)
mask_in_gts = select_candidates_in_gts(anc_points, gt_bboxes)
# get topk_metric mask, (b, max_num_obj, h*w)
mask_topk = self.select_topk_candidates(align_metric * mask_in_gts,
topk_mask=mask_gt.repeat([1, 1, self.topk]).bool())
# merge all mask to a final mask, (b, max_num_obj, h*w)
mask_pos = mask_topk * mask_in_gts * mask_gt
return mask_pos, align_metric, overlaps
此时,我们已经获得正样本的mask,但是GT存在交叠的情况,因此一个点可能对应多个GT,我们需要杜绝这种情况,将面积最大的GT赋值给有歧义的点。select_highest_overlaps函数可以完成这样的任务。
def select_highest_overlaps(mask_pos, overlaps, n_max_boxes):
# (b, n_max_boxes, h*w) -> (b, h*w)
fg_mask = mask_pos.sum(-2)
if fg_mask.max() > 1: # one anchor is assigned to multiple gt_bboxes
mask_multi_gts = (fg_mask.unsqueeze(1) > 1).repeat([1, n_max_boxes, 1]) # (b, n_max_boxes, h*w)
max_overlaps_idx = overlaps.argmax(1) # (b, h*w)
is_max_overlaps = F.one_hot(max_overlaps_idx, n_max_boxes) # (b, h*w, n_max_boxes)
is_max_overlaps = is_max_overlaps.permute(0, 2, 1).to(overlaps.dtype) # (b, n_max_boxes, h*w)
mask_pos = torch.where(mask_multi_gts, is_max_overlaps, mask_pos) # (b, n_max_boxes, h*w)
fg_mask = mask_pos.sum(-2)
# find each grid serve which gt(index)
target_gt_idx = mask_pos.argmax(-2) # (b, h*w)
return target_gt_idx, fg_mask, mask_pos
将mask_pos在n_max_boxes维度上叠加,当fg_mask.max() > 1时,说明存在歧义点。找到歧义点的索引mask_multi_gts 以及每个预测框对应的面积最大GT的索引max_overlaps_idx ,将max_overlaps_idx变成onehot形式,将有歧义点的值换成is_max_overlaps就可以祛除歧义。通过mask_pos.argmax(-2)能够获得target_gt_idx ,即可以找到每个点对应的哪个GT。
最后,我们根据target_gt_idx 可以获得计算loss的targets,get_targets逻辑较为清晰不赘述。至此,v8的label assignment讲解完毕。
def get_targets(self, gt_labels, gt_bboxes, target_gt_idx, fg_mask):
"""
Args:
gt_labels: (b, max_num_obj, 1)
gt_bboxes: (b, max_num_obj, 4)
target_gt_idx: (b, h*w)
fg_mask: (b, h*w)
"""
# assigned target labels, (b, 1)
batch_ind = torch.arange(end=self.bs, dtype=torch.int64, device=gt_labels.device)[..., None]
target_gt_idx = target_gt_idx + batch_ind * self.n_max_boxes # (b, h*w)
target_labels = gt_labels.long().flatten()[target_gt_idx] # (b, h*w)
# assigned target boxes, (b, max_num_obj, 4) -> (b, h*w)
target_bboxes = gt_bboxes.view(-1, 4)[target_gt_idx]
# assigned target scores
target_labels.clamp(0)
target_scores = F.one_hot(target_labels, self.num_classes) # (b, h*w, 80)
fg_scores_mask = fg_mask[:, :, None].repeat(1, 1, self.num_classes) # (b, h*w, 80)
target_scores = torch.where(fg_scores_mask > 0, target_scores, 0)
return target_labels, target_bboxes, target_scores
通过上述可以知道,最关键的一步是select_highest_overlaps函数,它将获得在每个像素点上面积最大的唯一GT,target_gt_idx。
至此,往后target_labels, target_bboxes, target_scores都由self.get_targets函数产生
![]()
def get_targets(self, gt_labels, gt_bboxes, target_gt_idx, fg_mask):
"""
Compute target labels, target bounding boxes, and target scores for the positive anchor points.
Args:
gt_labels (Tensor): Ground truth labels of shape (b, max_num_obj, 1), where b is the
batch size and max_num_obj is the maximum number of objects.
gt_bboxes (Tensor): Ground truth bounding boxes of shape (b, max_num_obj, 4).
target_gt_idx (Tensor): Indices of the assigned ground truth objects for positive
anchor points, with shape (b, h*w), where h*w is the total
number of anchor points.
fg_mask (Tensor): A boolean tensor of shape (b, h*w) indicating the positive
(foreground) anchor points.
Returns:
(Tuple[Tensor, Tensor, Tensor]): A tuple containing the following tensors:
- target_labels (Tensor): Shape (b, h*w), containing the target labels for
positive anchor points.
- target_bboxes (Tensor): Shape (b, h*w, 4), containing the target bounding boxes
for positive anchor points.
- target_scores (Tensor): Shape (b, h*w, num_classes), containing the target scores
for positive anchor points, where num_classes is the number
of object classes.
"""
# Assigned target labels, (b, 1)
batch_ind = torch.arange(end=self.bs, dtype=torch.int64, device=gt_labels.device)[..., None]
target_gt_idx = target_gt_idx + batch_ind * self.n_max_boxes # (b, h*w)
target_labels = gt_labels.long().flatten()[target_gt_idx] # (b, h*w)
# Assigned target boxes, (b, max_num_obj, 4) -> (b, h*w, 4)
target_bboxes = gt_bboxes.view(-1, 4)[target_gt_idx]
# Assigned target scores
target_labels.clamp_(0)
# 10x faster than F.one_hot()
target_scores = torch.zeros((target_labels.shape[0], target_labels.shape[1], self.num_classes),
dtype=torch.int64,
device=target_labels.device) # (b, h*w, 80)
target_scores.scatter_(2, target_labels.unsqueeze(-1), 1)
fg_scores_mask = fg_mask[:, :, None].repeat(1, 1, self.num_classes) # (b, h*w, 80)
target_scores = torch.where(fg_scores_mask > 0, target_scores, 0)
return target_labels, target_bboxes, target_scores
可以通过函数代码得知,target_scores的每个像素上的类别都由target_gt_idx决定,且只有一个!!!

target_bboxes的每个像素上的值也有gt_bboxes,target_gt_idx决定,通过每个像素的索引,最终,预测框也只有面积最大的一个!!!

四、总结
综上,yolov8的detection训练过程都是以每个像素最大面积真实目标框来作为loss的target来计算损失率和训练的,所以无法对重叠的多类别框进行训练,即使由nms产生的multi-label框,也不是真正的multi-label网络。如有讲述不对,欢迎各位同行指正!!















 1249
1249











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









