






【Transformer+目标检测】是计算机视觉领域的一种前沿研究方向,它结合了深度学习中的Transformer模型和目标检测技术。该方向旨在通过Transformer的自注意力机制提高目标检测的准确性和鲁棒性,尤其是在处理多模态数据和复杂场景时。相关研究工作通过创新的网络结构和学习策略,不断推动目标检测性能的边界,对自动驾驶、视频监控等应用领域具有重要意义。这些进展不仅加速了人工智能在视觉识别任务中的应用,也为解决目标检测中的挑战性问题提供了新的视角和工具。
为了帮助大家全面掌握【Transformer+目标检测】的方法并寻找创新点,本文总结了最近两年【Transformer+目标检测】相关的15篇顶会顶刊研究成果,这些论文、来源、论文的代码都整理好了,希望能给各位的学术研究提供新的思路。
需要的同学扫码添加我
回复“目标检测15”即可全部领取

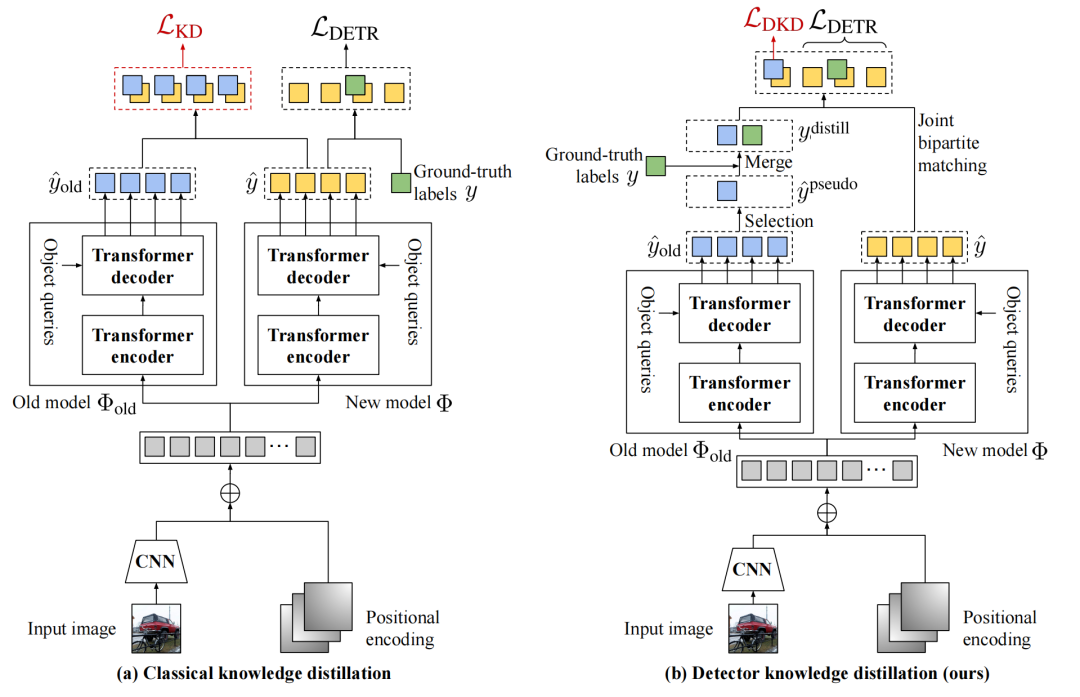
1、Continual Detection Transformer for Incremental Object Detection
方法
- 论文提出了一种名为ContinuaL DEtection TRansformer (CL-DETR)的新方法,用于增量式目标检测(Incremental Object Detection, IOD)。
- CL-DETR旨在解决增量学习中的目标检测问题,即在训练过程中逐步引入新的类别,同时避免灾难性遗忘(catastrophic forgetting)。
- 该方法包含两个关键技术:Detector Knowledge Distillation (DKD) 和 Exemplar Replay (ER)。
- DKD通过选择旧模型中最可靠和信息量最大的预测结果,忽略冗余的背景预测,确保与现有真实标签的兼容性。
- ER通过一种新的校准策略来保持训练集的标签分布,通过精心设计的样本集合来匹配所需的分布。
- CL-DETR还改进了IOD的基准测试协议,避免了在不同训练阶段重复观察相同图像的问题。
创新点
- DKD损失:提出了一种新的检测器知识蒸馏损失,专注于从旧模型中选择最有信心的对象预测,并将它们与新类别的真实标签合并,同时解决冲突,使用标准的联合二分图匹配进行训练。
- 校准策略:改进了ER方法,通过一种新的校准策略来保持训练数据中对象类别的分布,通过精心选择的样本集合来匹配所需的分布,从而更好地匹配训练和测试统计数据。
- 增量学习协议的改进:重新定义了IOD协议,避免了在不同训练阶段重复观察相同图像的问题,这与标准增量学习的定义更为一致。
- 实验验证:在COCO 2017数据集上进行了广泛的实验,证明了CL-DETR在IOD设置下达到了最先进的结果,特别是在与Deformable DETR和UP-DETR等基于transformer的目标检测器结合使用时,相比直接应用KD和ER的方法有显著的性能提升。
- 深入的消融研究:通过消融研究进一步验证了模型选择的合理性,包括对DKD损失和ER校准策略的深入分析,以及对不同超参数设置的鲁棒性分析。
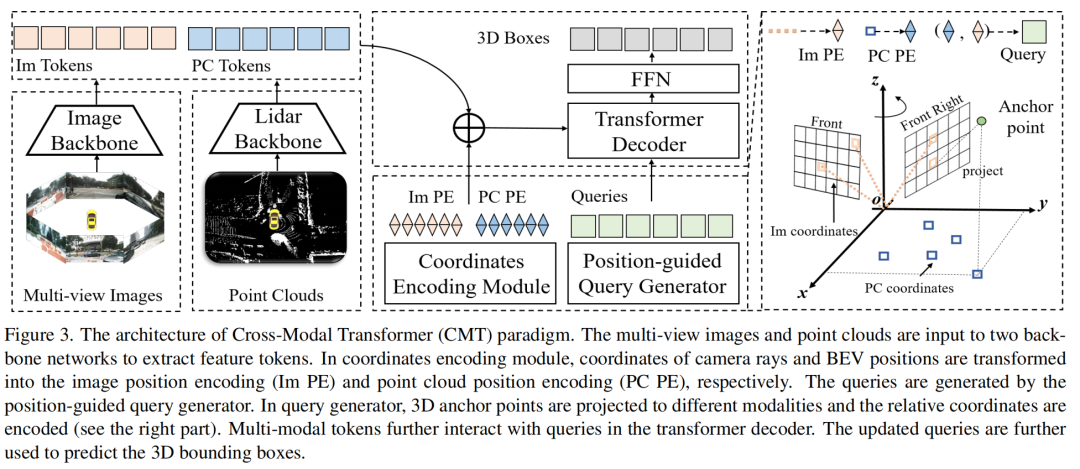
2、Cross Modal Transformer: Towards Fast and Robust 3D Object Detection"
方法
- 论文提出了一种名为Cross Modal Transformer(CMT)的鲁棒3D检测器,用于端到端的3D多模态检测。
- CMT输入图像和点云令牌(tokens),不经过显式的视图转换,直接输出精确的3D边界框。
- 通过编码3D点到多模态特征中来执行多模态令牌的空间对齐。
- CMT的核心设计简单,但性能卓越,在nuScenes测试集上达到了74.1%的NDS(单模型的最新水平),同时保持快速的推理速度。
- CMT即使在缺少激光雷达(LiDAR)的情况下也具有很强的鲁棒性。
创新点
- 跨模态特征对齐:CMT通过坐标编码模块(CEM)隐式地将3D坐标编码到多模态特征中,无需显式的交叉视图特征对齐。
- 位置引导的查询生成:引入了位置引导的查询生成器,每个查询都初始化为一个3D参考点,并且这些点被转换到图像和激光雷达空间中,以执行相对坐标编码。
- 端到端的简单有效框架:CMT提供了一个简单且端到端的管道,避免了复杂的操作,如网格采样和体素池化,同时实现了与现有方法相比的优越性能。
- 鲁棒性:CMT通过掩码模态训练(masked-modal training)策略提高了模型的鲁棒性,即使在缺少激光雷达或相机输入的情况下也能保持性能。
- 无后处理:CMT是一个真正端到端的框架,不需要任何后处理步骤。
- 在nuScenes数据集上的SOTA性能:CMT在nuScenes数据集上实现了最先进的3D检测性能,为未来的研究提供了一个简单的基线。
- 快速推理速度:CMT在保持高精度的同时,还具有快速的推理速度,这对于实时应用至关重要。
需要的同学扫码添加我
回复“目标检测15”即可全部领取

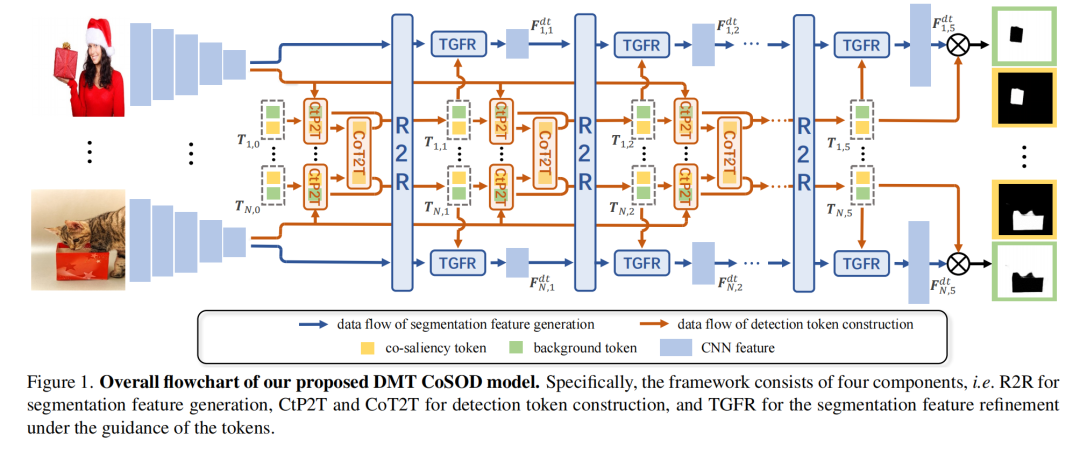
3、Discriminative Co-Saliency and Background Mining Transformer for Co-Salient Object Detection
方法
- 论文提出了一种基于Transformer的框架,称为Discriminative co-saliency and background Mining Transformer (DMT),用于共同显著目标检测(Co-Salient Object Detection, CoSOD)。
- DMT框架通过多个经济的多粒度相关性模块来显式地挖掘共同显著性(co-saliency)和背景信息,并有效地建模它们之间的区分度。
- 首先,提出了一个区域到区域的相关性模块(Region-to-Region correlation module, R2R),用于在保持计算效率的同时,引入图像间的关系到像素级分割特征。
- 使用两种预定义的token,通过对比引导的像素到token相关性模块(Contrast-induced Pixel-to-Token correlation module, CtP2T)和共同显著性token到token相关性模块(Co-saliency Token-to-Token correlation module, CoT2T)来挖掘共同显著性和背景信息。
- 设计了一个token引导的特征细化模块(Token-Guided Feature Refinement module, TGFR),以提高分割特征在学到的token指导下的可区分性。
- 通过迭代相互促进的方式进行分割特征提取和token构建。
创新点
- 双变量FG&BG建模:DMT从共同显著性和背景信息的显式探索出发,有效地建模了它们之间的区分度,这与以往主要关注前景而忽略背景的CoSOD方法不同。
- 多粒度相关性模块:提出了R2R、CtP2T和CoT2T等计算经济的多粒度相关性模块,用于图像间和图像内关系的建模,提高了关系的复杂性并减少了计算负担。
- 对比引导的像素到token相关性:CtP2T模块通过考虑共同显著性与背景之间的对比关系来提取token,增强了token之间的可区分性。
- token引导的特征细化:TGFR模块使用学到的token作为指导来细化分割特征,提高了特征对于共同显著性和背景区域的可区分性。
- 迭代相互促进:DMT通过迭代部署CtP2T和CoT2T利用分割特征来更新token,然后采用TGFR来细化相应的解码器特征,有效促进了学习过程,从而获得更准确的CoSOD结果。
需要的同学扫码添加我
回复“目标检测15”即可全部领取
















 270
270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









