







 文章介绍了地平线和华科团队在ICLR上发表的论文,提出了一种端到端的方法,用于生成实例级别的地图标线,通过排列等效模型处理点集预测和方向信息,论文还探讨了关键的排列模型和边损失。
文章介绍了地平线和华科团队在ICLR上发表的论文,提出了一种端到端的方法,用于生成实例级别的地图标线,通过排列等效模型处理点集预测和方向信息,论文还探讨了关键的排列模型和边损失。

01 背景和阅读之前
家人们大家好,我是老张。今天分享的论文出自地平线和华科,发表在ICLR上。工作背景是端到端的生成实例级别的地图标线,地图标线分为人行道、分割线、路沿3个类别,并预测线的方向。

我看到论文的效果图就在想,如果这种端到端的方法可以表征各种不规则的几何形状,那显然拥有不小的可拓展性,除了自动驾驶中预测地面标线,还有许多其他应用场景。
看论文之前,由于我没有关注过这个任务,所以先想了想这个任务可能会怎么做:
-
最朴素的想法应该是看作一个分割任务(Seg),把每条线实例分割出来,相信有不少工作也是这么做的。但有两个问题:
- 分割首先就很难端到端,分割出类别的概率图是一块一块的连通域,要想得到宽度为1px的细线,可以用卷积来实现类似【图像处理-侵蚀】的操作;但是仍然不好预测线的方向,还需要另一个头预测特征图中点的方向性。
- 其次是性能,由于任务关心的就那几条特定线或者形状,如果做全图分割,后很多地方的计算是浪费的。
-
从图中看,作者是将预测不规则几何图形表示为预测点集,那问题变得像姿态估计(Pose Estimation),也就是估计图片中人的动作姿态,都是预测一些特殊的点,并将这些点连起来,需要明确:
-
如何确定哪些点属于同一个实例
-
如何确定同一个实例中的点间连接顺序
-
如先框出实例,再预测实例内部的点,画了个丑图示意一下:预测黑色的实例的框可能不好学,毕竟线在框中所包含的语义信息很少,预测实例框更可能是蓝色这样。
-
- 所以比较好的表示应该是自底向上的,先预测属于同一实例的所有点,再想办法把点连起来。所以论文会如何端到端的预测点之间的连接呢:)
02 方法
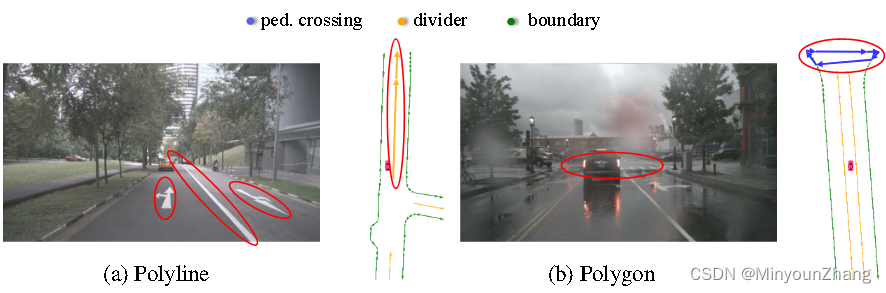
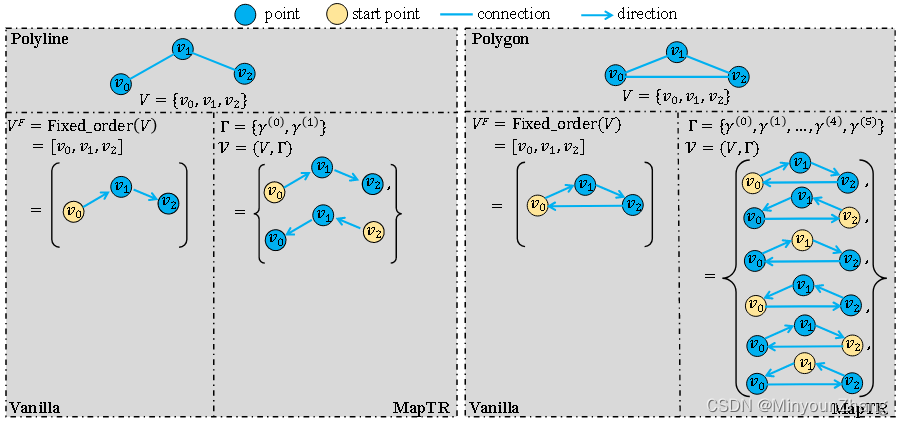
首先就要说到本文提出的排列等效模型,用来增广GT(Groud Truth,标注真值,后文都缩写为GT)点列的排列方式。作者将道路标线点集抽象为表示的两种几何形状,线和多边形,标注的点序列是顺序的,需要关心的是点序列的方向性:
- 如果gt是一条线,将扩充为两种连接方式:如上图左所示,左侧点作为起始或右侧点作为起始;
- 如果gt是多边形,每个点都可能作为多边形的起始点。N个点都可以作为起始点,有顺时针逆时针2种连接方式,扩充为2 * N种连接方式,如上图右所示;
贴一下代码吧,一条线时num_shifts等于2,多边形时num_shifts等于多变形点个数 * 2
@property
def shift_fixed_num_sampled_points_v4(self):
"""
args: single image point list [instances_num, fixed_num, 2]
return:shifts point list [instances_num, num_shifts, fixed_num, 2]
"""
fixed_num_sampled_points = self.fixed_num_sampled_points
instances_list = []
is_poly = False
# is_line = False
for fixed_num_pts in fixed_num_sampled_points:
# [fixed_num, 2]
is_poly = fixed_num_pts[0].equal(fixed_num_pts[-1])
pts_num = fixed_num_pts.shape[0]
shift_num = pts_num - 1
shift_pts_list = []
if is_poly 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1563
1563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









