






1.Introducton
本文是2021年会议NAACL上的一篇文章。在这篇文章中,作者提出了一种具有多层结构的类型感知图卷积神经网络模型(T-GCN)。
2.Model
2.1 Type-aware Graph Construction
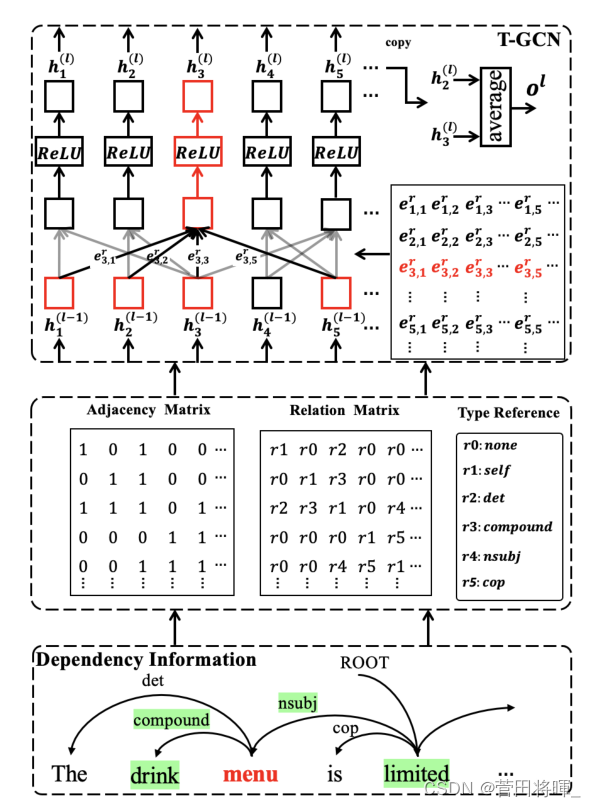
这一部分主要介绍如何构建类型感知图。我们知道,在以往的文章中,学者们更多的是关注词与词的依赖关系,从而忽略了词与词之间的关系类型。如果只是关注依赖关系,那么就无法判断词与词之间关联的重要性,从而会误导模型的“判断”。本文中作者通过三个步骤向我们介绍了关系类型图的构建。
首先:通过一些现有的工具包,从而获得依赖结果。
其次:作者使用了 作为领接矩阵来存放
和
的依赖关系,如果
和
之间有依赖关系那么
的值为1,否则为0。用
来存放
和
的依赖关系类型,每一种依赖关系都对应了不同的值。
最后:为了利用关系类型,作者利用了一个转变矩阵将映射为
。
具体构造过程以及模型大概如下图所示。
2.2 T-GCN
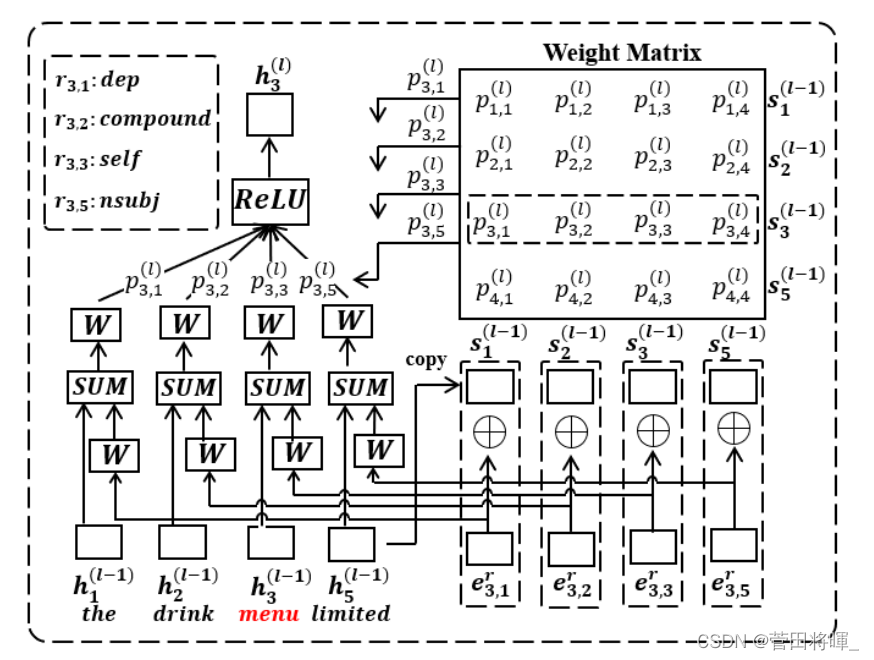
模型的主要部分中,作者设置了一个L层的T-GCN,并且对于每一层中图的边,作者会根据它们对任务的贡献,进行加权。
首先,我们知道,对于和
之间的每一条边,我们已经得到了他们之间的关系类型对应的数值。于是,在这里作者将其与隐藏状态的值进行了连接。得到了
和
。
随后,作者将计算的值带入到了权重计算公式,得到了权重
。之后通过一个可训练的矩阵
,将
“融入”隐藏状态中
。
最后,作者将计算的权重还有隐藏状态的值带入到了图卷积公式中。得到了下一层i的隐藏状态的值。
ps:这里的 指的是当前需要计算隐藏状态的词的下标,
值得是这个句子中词的下标。
具体的模型运作过程如下图所示。
2.3 Attentive Layer Ensemble
在这里作者认为每一层的T-GCN都有他们独特的能力去编码上下文的信息。因此为了这种能力,作者提出了一种关注的层集成全面学习所以T-GCN层。(原文:we propose to comprehensively learn from all T-GCN layers with attentive layer ensemble.)
首先,作者将每一层的输出的隐藏状态的向量进行一个平均,得到
。随后通过一个加权平均得到最后的结果
。
2.4 Encoding and Decoding with T-GCN
对于编码,作者是介绍了两种不同的编码的方式。
1.是将句子作为输入放到编码器中
,最后得到初始的隐藏向量。
2.是将句子-方面对作为输入放到编码器中,得到初始的隐藏向量。
对于解码,作者先将T-GCN的输出放入一个全连接层,最后再对得到的结果做一个softmax得到最后的情感结果。
3.Experiments
实验结果:
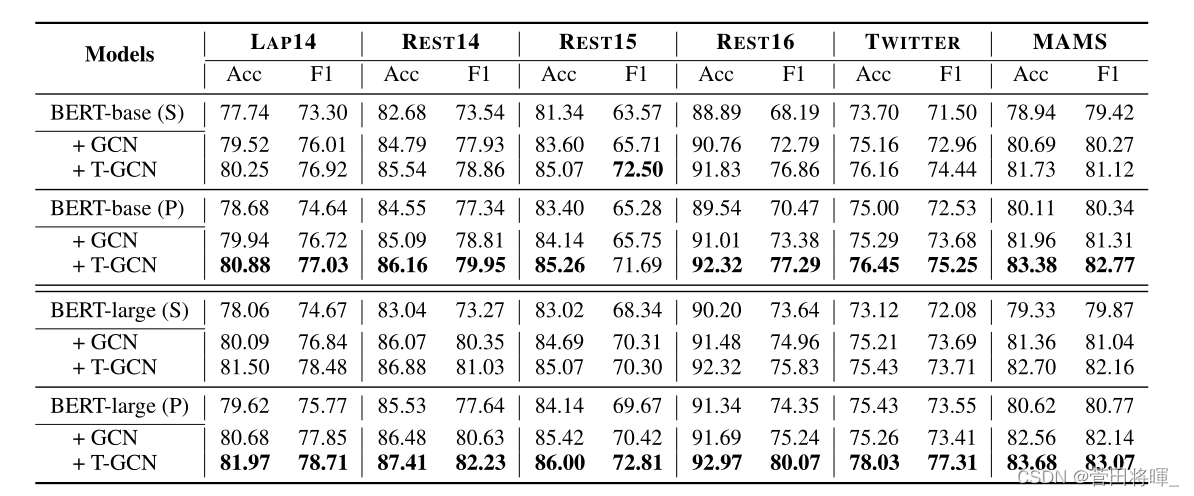
模型比较:
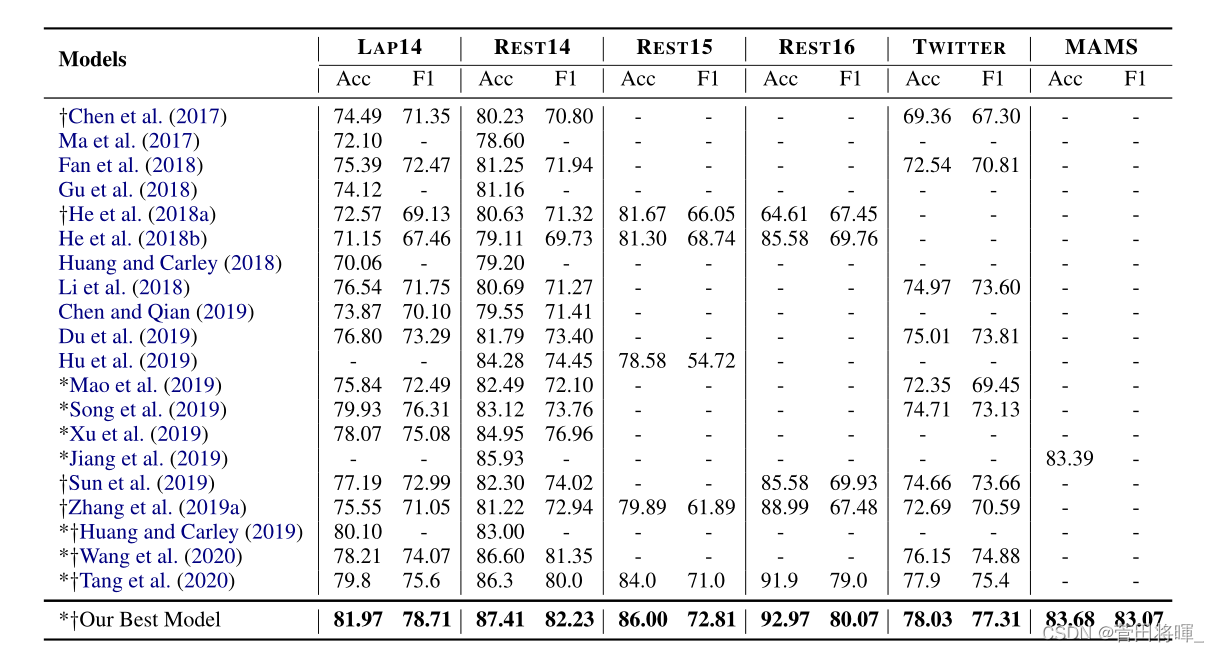
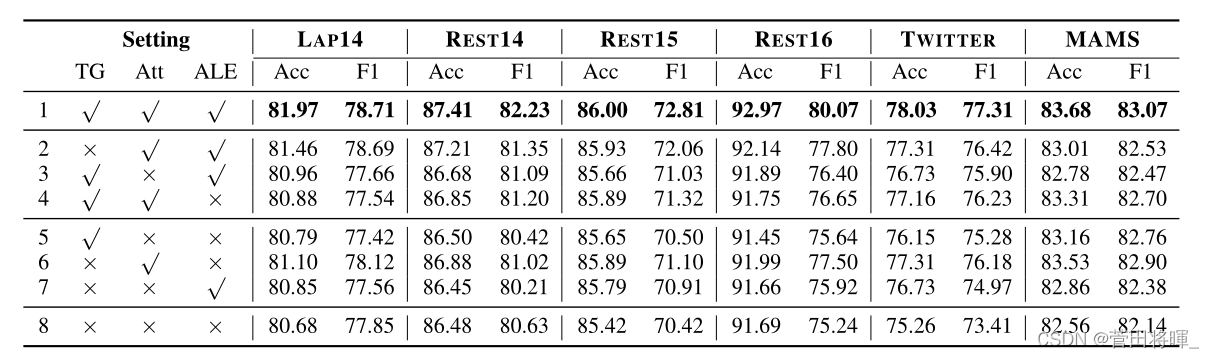
消融实验:
4.Conclusion
在这篇文章中,作者提出了一种基于T-GCN的ABSA神经网络方法,其中输入图建立在输入句子的依赖树上。具体来说,图中的边是在输入句子的依赖关系和类型的基础上构造的;对于每个单词,作者使用注意来加权T-GCN中与之相关联的所有此类类型感知边缘;作者还应用注意层集成从不同的T-GCN层全面学习上下文信息。在六个广泛使用的英语基准数据集上的实验结果证明了我们的方法的有效性,在所有数据集上都取得了最先进的性能。进一步的分析表明,将类型信息纳入模型以及将注意力集成应用于多层次学习的有效性。















 2877
2877











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









