









 本文分享CTR/推荐领域一篇论文,指出当前CTR方法缺乏对用户潜在兴趣建模及考虑兴趣变化趋势的问题。论文设计兴趣提取层和兴趣变化层,引入auxiliary loss监督GRU学习,采用AUGRU捕捉用户兴趣变化,并对核心代码进行分析。
本文分享CTR/推荐领域一篇论文,指出当前CTR方法缺乏对用户潜在兴趣建模及考虑兴趣变化趋势的问题。论文设计兴趣提取层和兴趣变化层,引入auxiliary loss监督GRU学习,采用AUGRU捕捉用户兴趣变化,并对核心代码进行分析。
本次要分享的论文是 CTR/推荐 领域内又一篇论文,论文链接dien,参考的实现代码 mouna-dien。和之前分享CTR论文类似,本论文难度不大,读起来较容易。
文章目录
论文动机及创新点
-
利用用户历史行为数据,对用户的兴趣演变进行建模对CTR效果至关重要,但是目前大部分CTR方法 将行为表征直接视为兴趣,缺乏对具体行为背后潜在利益的专门建模。此外,很少有研究考虑到兴趣的变化趋势。
-
众所周知,并非所有用户的行为都严格依赖于每个相邻的行为。每个用户都有不同的兴趣,每个兴趣都有自己的发展轨迹。对于任何目标ad,现有模型只能得到一条固定的兴趣演化轨迹,因此这些模型会受到兴趣漂移的干扰。
-
本论文为了很好的捕捉用户的兴趣 变化,为此设计了两个网络层,分别是
- 兴趣提取层(interest extractor layer),用GRU网络从用户历史行为中提取到用户每个时刻的兴趣信息,为了防止GRU得不到足够的监督信号,论文中专门设计了 auxiliary loss,使用连续行为数据 来监督GRU每一步的隐状态学习。这使得隐藏状态具有足够的能力来表示用户潜在的兴趣。
- 兴趣变化层(interest evolving layer),在interest extractor layer 上进行Attention计算(候选ad与GRU隐状态),得到每个时刻的注意力得分,然后利用interest extractor layer 上每个时刻注意力得分和隐状态,在上面再搭一层GRU网络,不同的是这个GRU网络中的更新门,引入了注意力得分,由此该机制在论文中称为 attentional update gate (AUGRU)
模型
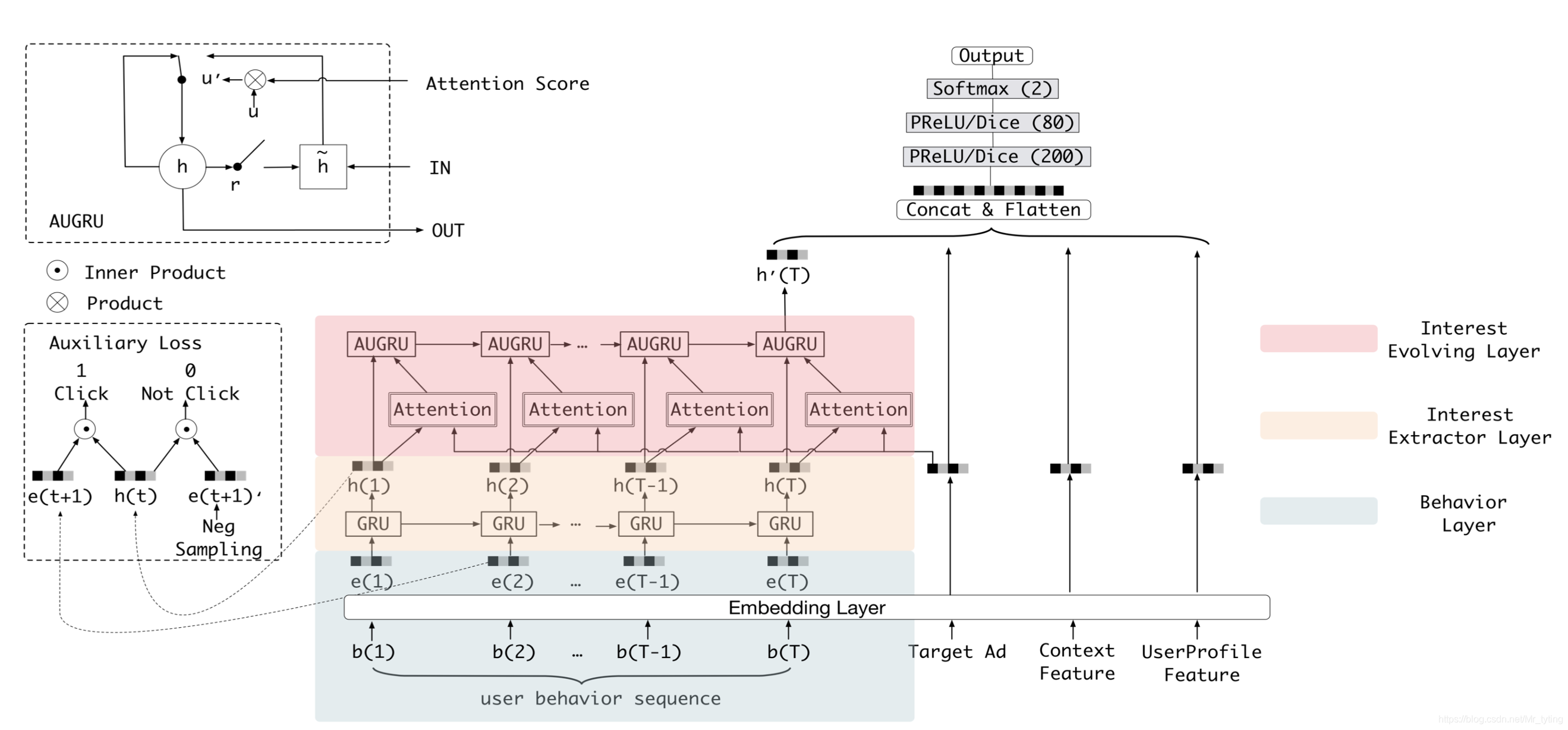
Behavior Layer
- user behavior sequence:按时间排序的用户行为(访问过goods_id),其中 b i b_i bi 为onehot编码形式,长度为T
- Target Ad:用来推荐的候选广告
- Context Feature:时间等一些特征
- UserProfileFeature:用户画像特征,例如性别、年龄等一些onehot特征
Behavior Layer 层会将上述高维稀疏的onehot特征转换成 低维稠密的embedding向量。
Interest Extractor Layer
简单来说,就是在Behavior Layer上搭一层GRU网络
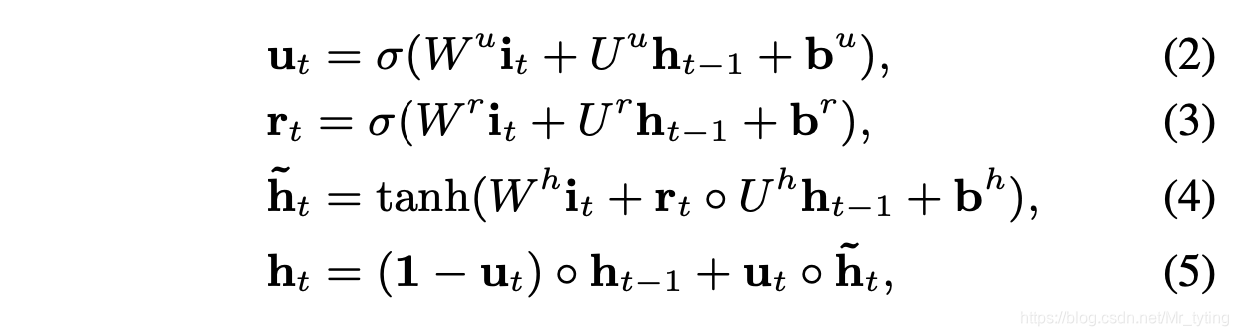
上述公式中
u
t
u_t
ut为更新门,
r
t
r_t
rt 为重置门,
σ
\sigma
σ 为sigmoid 函数,
∘
\circ
∘ 表示 元素点乘,
i
t
i_t
it 为Behavior Layer中的
e
t
e_t
et,
h
t
h_t
ht 为GRU中第t时刻的隐状态。
但是 h t h_t ht 仅能捕捉行为之间的依赖关系,不能有效的表示用户兴趣
在上述GRU网络里,如何施加监督信号呢? 如果仅在最后一个时刻施加一个是否点击的信号,对于t < T时刻的 h t h_t ht 都得不到足够的监督。
我们知道,用户每个时刻的兴趣 将直接影响用户下一时刻的行为,因此论文中,设计了一种 auxiliary loss,直接用 b t + 1 b_{t+1} bt+1来监督 h t h_t ht,同时会在item set(除去click item)内随机选取一个负样本也来监督 h t h_t ht。由此在Interest Extractor Layer,可以有N对正负样本的embedding 序列 { e b i , e b ^ i } \{e_b^i, \hat{e_b}^i\} {ebi,eb^i},其中 e b i ∈ R T × n E {e_b^i} \in R^{T \times n_E} ebi∈RT×nE, e b ^ i ∈ R T × n E {\hat{e_b}^i} \in R^{T \times n_E} eb^i∈RT×nE。
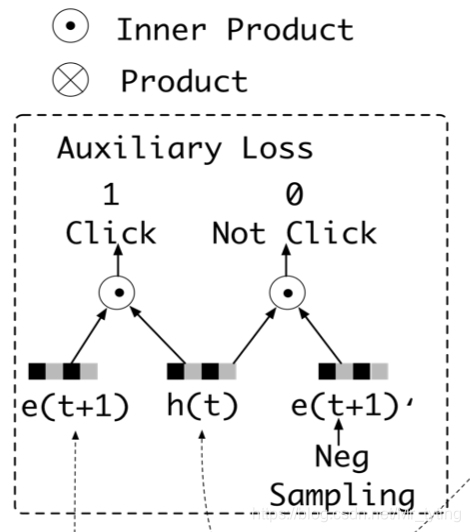
auxiliary loss 数学表达式如下:
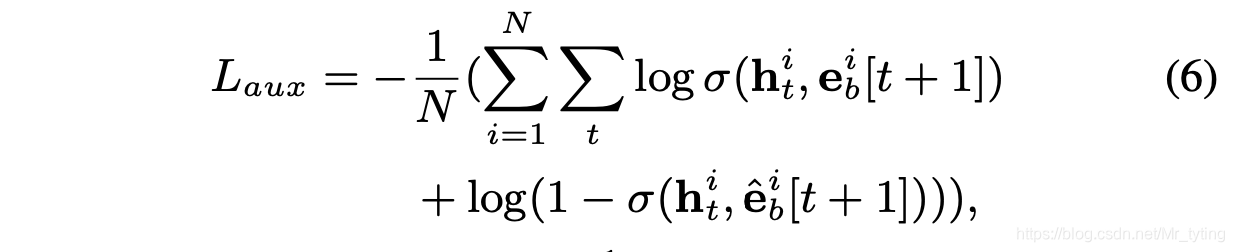
这个 auxiliary loss 比较有意思,有点像交叉熵
Interest Extractor 层 loss数学表达式如下:
L
=
L
t
a
r
g
e
t
+
α
∗
L
a
u
s
L=L_{target}+\alpha * L_{aus}
L=Ltarget+α∗Laus
其中 L t a r g e t L_{target} Ltarget 为最后时刻loss, α \alpha α 为要调节的超参数。
auxiliary loss 的引入有助于GRU的每一时刻都能得到足够的监督,则其每个时刻隐状态有能力表征出兴趣。对于GRU的优化,auxiliary loss 降低了GRU建模长历史行为序列时的反向传播难度。最后,auxiliary loss 为嵌入层的学习提供了更多的语义信息,从而得到了更好的embedding matrix。
Interest Evolving Layer
这一层稍微复杂些,用来捕获用户随时间变化的兴趣趋势。
- 由于兴趣的多样性,兴趣可以漂移。兴趣漂移对行为的影响是用户可能在一段时间内对各种书籍感兴趣,而在另一段时间内需要衣服。
- 虽然兴趣可以相互影响,但每个兴趣都有自己的演变过程,例如书籍和衣服的演变过程几乎是个别的。我们只关注与target ad 相关的演变过程。典型的Attention思想
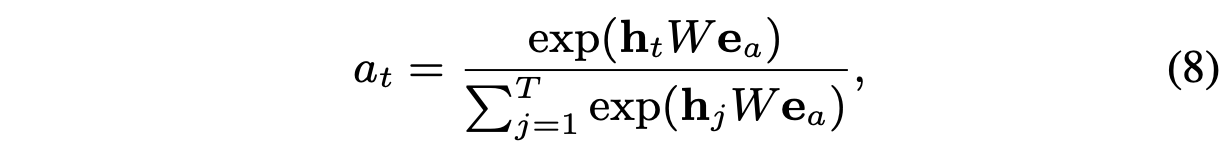
上述公式中,
h
t
h_t
ht 表示Interest Extractor Layer 输出的隐状态,可以理解为该时刻的兴趣,
W
e
a
W_{e_a}
Wea 为target ad 的embedding。得到的注意力得分
α
t
\alpha_t
αt 表示
t
t
t 时刻用户兴趣与target ad 的相关性。
接下来,论文中尝试了三种将 注意力机制和GRU 结合的方式
-
GRU with attentional input (AIGRU)
AIGRU 尝试使用注意力得分 来影响 Interest Evolving Layer 的输入
i t ′ = h t ∗ α t i_t^{'}=h_t * \alpha_t it′=ht∗αt
上式中, h t h_t ht 为 t t t 时刻 Interest Extractor Layer 的隐状态, α t \alpha_t αt 为 该隐状态与 target ad 的相关性,理想情况下,与target ad 无关的兴趣( h t h_t ht) 不要在 Interest Evolving Layer 中产生任何影响,但是AIGRU效果并不好,因为即使GRU中输入为0,也能影响GRU隐状态,所以即使与 target ad 相关性很低的兴趣,也能对 Interest Evolving Layer 中产生影响。 -
Attention based GRU(AGRU)
AGRU 直接用 注意力得分 α t \alpha_t αt 来代替GRU 中的 更新门。
i t ′ = h t i_t^{'}=h_t it′=ht
h t ′ = ( 1 − α t ) ∗ h t − 1 ′ + α t ∗ h ~ t ′ h_t^{'}=(1-\alpha_t) * h_{t-1}^{'}+\alpha_t * \tilde{h}_t^{'} ht′=(1−αt)∗ht−1′+αt∗h~t′
其中 h t ′ 、 h t − 1 ′ 、 h ~ t ′ h_t^{'}、h_{t-1}^{'}、\tilde{h}_t^{'} ht′、ht−1′、h~t′ 均表示 AGRU 中的隐状态。该方法尝试用注意力得分来控制当前时刻更新的隐状态。AGRU在兴趣演化过程中弱化了相关性较低的兴趣影响,注意力嵌入到GRU,提高了注意机制的影响力,有助于AGRU克服AIGRU的缺陷。 -
GRU with attentional update gate (AUGRU)
AGRU 中用标量 α t \alpha_t αt 代替GRU中的向量 u t u_t ut,忽略了不同维度的重要性。因此又提出AUGRU。
u ~ t ′ = α t ∗ u t ′ \tilde{u}_t^{'} = \alpha_t * u_{t}^{'} u~t′=αt∗ut′
h t ′ = ( 1 − u ~ t ′ ) ∘ h t − 1 ′ + u ~ t ′ ∘ h ~ t ′ h_t^{'}=(1-\tilde{u}_t^{'}) \circ h_{t-1}^{'}+\tilde{u}_t^{'} \circ \tilde{h}_t^{'} ht′=(1−u~t′)∘ht−1′+u~t′∘h~t′
上式中 u t ′ u_{t}^{'} ut′ 为 AUGRU 原始的 更新门, u ~ t ′ \tilde{u}_t^{'} u~t′ 表示经过注意力得分加权后的更新门, h t ′ 、 h t − 1 ′ 、 h ~ t ′ h_t^{'}、h_{t-1}^{'}、\tilde{h}_t^{'} ht′、ht−1′、h~t′ 均表示 AUGRU 中的隐状态。
论文中采用的是 AUGRU 来捕捉用户兴趣变化。
核心代码分析
读完论文,我感觉特别需要关注 AUGRU 代码是如何实现的,其他的还好。
auxiliary loss
def auxiliary_loss(self, h_states, click_seq, noclick_seq, mask, stag = None):
mask = tf.cast(mask, tf.float32)
click_input_ = tf.concat([h_states, click_seq], -1)
noclick_input_ = tf.concat([h_states, noclick_seq], -1)
click_prop_ = self.auxiliary_net(click_input_, stag = stag)[:, :, 0]
noclick_prop_ = self.auxiliary_net(noclick_input_, stag = stag)[:, :, 0]
click_loss_ = - tf.reshape(tf.log(click_prop_), [-1, tf.shape(click_seq)[1]]) * mask
noclick_loss_ = - tf.reshape(tf.log(1.0 - noclick_prop_), [-1, tf.shape(noclick_seq)[1]]) * mask
loss_ = tf.reduce_mean(click_loss_ + noclick_loss_)
return loss_
def auxiliary_net(self, in_, stag='auxiliary_net'):
bn1 = tf.layers.batch_normalization(inputs=in_, name='bn1' + stag, reuse=tf.AUTO_REUSE)
dnn1 = tf.layers.dense(bn1, 100, activation=None, name='f1' + stag, reuse=tf.AUTO_REUSE)
dnn1 = tf.nn.sigmoid(dnn1)
dnn2 = tf.layers.dense(dnn1, 50, activation=None, name='f2' + stag, reuse=tf.AUTO_REUSE)
dnn2 = tf.nn.sigmoid(dnn2)
dnn3 = tf.layers.dense(dnn2, 2, activation=None, name='f3' + stag, reuse=tf.AUTO_REUSE)
y_hat = tf.nn.softmax(dnn3) + 0.00000001
return y_hat
AUGRU
class VecAttGRUCell(RNNCell):
"""Gated Recurrent Unit cell (cf. http://arxiv.org/abs/1406.1078).
Args:
num_units: int, The number of units in the GRU cell.
activation: Nonlinearity to use. Default: `tanh`.
reuse: (optional) Python boolean describing whether to reuse variables
in an existing scope. If not `True`, and the existing scope already has
the given variables, an error is raised.
kernel_initializer: (optional) The initializer to use for the weight and
projection matrices.
bias_initializer: (optional) The initializer to use for the bias.
"""
def __init__(self,
num_units,
activation=None,
reuse=None,
kernel_initializer=None,
bias_initializer=None):
super(VecAttGRUCell, self).__init__(_reuse=reuse)
self._num_units = num_units
self._activation = activation or math_ops.tanh
self._kernel_initializer = kernel_initializer
self._bias_initializer = bias_initializer
self._gate_linear = None
self._candidate_linear = None
@property
def state_size(self):
return self._num_units
@property
def output_size(self):
return self._num_units
def __call__(self, inputs, state, att_score):
return self.call(inputs, state, att_score)
def call(self, inputs, state, att_score=None):
"""Gated recurrent unit (GRU) with nunits cells."""
if self._gate_linear is None:
bias_ones = self._bias_initializer
if self._bias_initializer is None:
bias_ones = init_ops.constant_initializer(1.0, dtype=inputs.dtype)
with vs.variable_scope("gates"): # Reset gate and update gate.
self._gate_linear = _Linear(
[inputs, state],
2 * self._num_units,
True,
bias_initializer=bias_ones,
kernel_initializer=self._kernel_initializer)
value = math_ops.sigmoid(self._gate_linear([inputs, state]))
r, u = array_ops.split(value=value, num_or_size_splits=2, axis=1)
r_state = r * state
if self._candidate_linear is None:
with vs.variable_scope("candidate"):
self._candidate_linear = _Linear(
[inputs, r_state],
self._num_units,
True,
bias_initializer=self._bias_initializer,
kernel_initializer=self._kernel_initializer)
c = self._activation(self._candidate_linear([inputs, r_state]))
u = (1.0 - att_score) * u
new_h = u * state + (1 - u) * c
return new_h, new_h
总结
- 本论文方法虽然简单,但是读起来比较有意思,比如其中的 auxiliary loss、AUGRU的设计,Interest Extractor Layer、Interest Evolving Layer 的网络结构,特别是AUGRU中将注意力得分引入到GRU的更新门中,来控制哪部分兴趣影响最终结果。
参考资料
- https://arxiv.org/abs/1809.03672
- https://github.com/mouna99/dien

















 1206
1206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









