






端到端自动驾驶需要什么样的标注数据
2024年2月,清华大学MARS-LAB和理想汽车合作提出了DriveVLM端到端大模型,即论文《DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models》。
在这个论文中提出了一种数据挖掘和标注的方法,并以此为基础构建了一个超过40个场景类别的自动驾驶数据集SUP-AD。
附赠自动驾驶最全的学习资料和量产经验:链接
构建SUP-AD数据集所用到的数据挖掘和标注方法示意图:
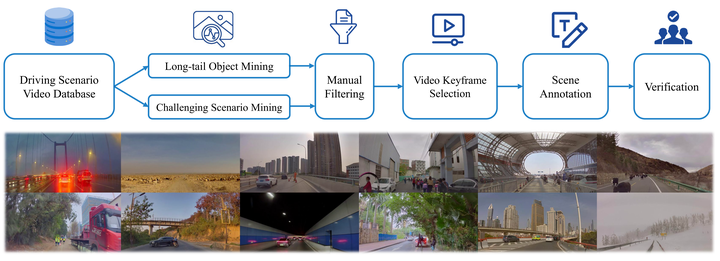

图片来源:《DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models》
具体步骤:
-
筛选数据
-
) 长尾目标挖掘**。**首先预定义一系列长尾目标类别,比如异形车辆、道路杂物和横穿马路的动物等。然后使用基于CLIP的搜索引擎,从海量自动驾驶数据中,挖掘这些长尾场景。
-
) 挑战性场景挖掘。 除了长尾物体外,我们同样对具有挑战性的驾驶场景进行了挖掘。在这些场景的数据中,需要根据不断变化的驾驶条件调整自车(ego vehicle)的驾驶策略。这些场景一般是根据记录的驾驶操作变化得到的,例如急刹车等。
-
) 人工检查,剔除与需求不一致的数据。
-
-
**关键帧选择。**每个挖掘出来的驾驶场景都是一个十几秒视频片段,在这么长的时间跨度中,选取“关键帧”至关重要。在大多数具有挑战性的场景中,关键帧是在需要显著改变速度或方向之前的时刻。根据综合测试,我们选择在实际操作前0.5秒到1秒作为关键帧,以确保改变驾驶决策的最佳反应时间。对于不涉及驾驶行为变化的场景,我们选择与当前驾驶情景相关的帧作为关键帧。
-
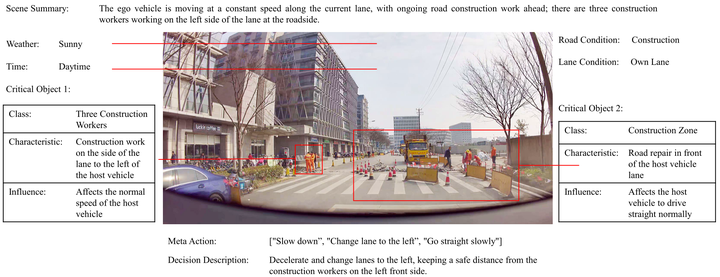
场景标注。 对于选取好关键帧后的数据,由一组标注员进行场景标注,包括任务提到的场景描述、场景分析和规划等内容信息。同时为了便于场景标注,我们开发了一个视频标注工具,能够比较方便的针对特定标注内容进行对应的标注和检查。SUP-AD数据集某个场景关键帧的标注结果如下图所示:
















 639
639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









