






这篇文章是使用CNN做object detection的第一篇论文,提出的方法叫做Region-based CNN,简称R-CNN。这个R-CNN的思路就是我的毕业论文中最为关键的一环,同时很多新的重要的深度学习物体检测方法都是基于这个思路提出的,所以这篇论文的整理也显得尤为重要,但是同时刚开始接触这个论文时候由于基础不扎实,整理起来可谓举步维艰,但是现在借助网上的各种资料,思路也渐渐清晰起来,就来做一个迭代式的整理,想通一点就做一点。
首先是这个论文中的R-CNN模型(转载自http://blog.csdn.net/u011534057/article/details/51218218,虽然这其实是论文中就有的图片,但是转载了还是注明一下):
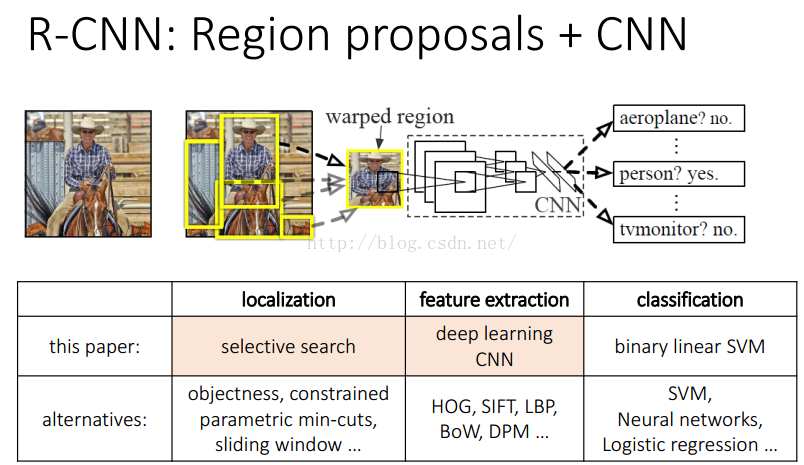
这个模型的流程其实是很清晰的,首先找出物体可能存在的图片区域,将区域resize后输入到CNN网络中,最后对CNN的输出结果做分类。
这里要注明的一点是和传统的CNN最后靠softmax层来输出分类结果不同,这篇论文里面CNN的全链接层后面没有链接softmax,而是直接输出4096个数,然后对于每个分类,训练一个binary SVM,即对于每个类,这个SVM就是判断是还是否。最后的效果,比如20个分类,它就训练21个SVM,其中一个是背景,然后每个SVM都接受CNN的4096个输出,打个分,分最高的获胜。(一开始真是看不懂为什么最后还要有个SVM,论文中说用SVM而不用softmax是因为用了SVM后正确率得到提升)
然后就来说说这个迷惑我最久的所谓”Region based”。一开始我一直没懂为什么不用小窗口走查,后来看资料说小窗口其实就相当于exhausted search,也就是穷举法,那时候CNN效率太低,如果还用穷举法太慢,而且和人脸不同,物体检测的话,因为每个物体的size相差太远,小窗口效率真的是底下的不行,所以这里用了一种叫做寻找region proposals的办法,先找到region proposals(可能存在物体的区域),再将这个region proposal作为CNN的输入。那么这个region proposals又怎么找呢,我一开始也是非常迷惑,还以为是通过CNN来找,真是一头雾水,后来翻查资料才终于知道是用了种数学方法,通过图像分割的手段来获得的region proposals,具体方法叫做selective search[1]。(不想看论文仔细读读这个博客也可以大概理解http://blog.csdn.net/mao_kun/article/details/50576003)
一开始没看懂的CNN训练阶段:在CNN阶段,如果用selective search挑选出来的候选框与物体的人工标注矩形框的重叠区域IoU大于0.5,那么我们就把这个候选框标注成物体类别,否则我们就把它当做背景类别。
仍然不怎么懂的SVM训练阶段:训练方法还是懂,但是至于为何选用SVM,IoU阈值如何设置,我的理解是经验和实验的结果。














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









