






近期,Google旗下的前沿人工智能企业DeepMind汇集了来自 22 种不同机器人类型的数据,创建了 Open X-Embodiment 数据集并开源了出来。该数据集让他们研发的RT-2 机器人在制造和编程方式上有了重大飞跃。
有分析称,在上述数据集上训练的 RT-2-X 在现实世界机器人技能上的表现提高了 2 倍,而且通过学习新数据RT-2-X 掌握了很多新技能。英伟达高级人工智能科学家Jim Fan甚至公开表示,这个数据集可能是机器人的ImageNet时刻。
谷歌开放了X-具身存储库(robotics-transformer-X.github.io)来存储Open X-Embodiment数据集。这是一个开源存储库,包括用于X-具身机器人学习研究的大规模数据以及预训练模型的检查点。
为助力具身机器人技术研究,提高数据准备效率,OpenDataLab(opendatalab.com)整理并上架了DeepMind公开的Open X-Embodiment数据集,欢迎大家下载与探索。
另外寻星计划正在火热进行中,上传原创数据集领好礼,点击参加→寻找最闪亮的 OpenDataLab 数据之星, We want you !
数据集概述
Open X-Embodiment子数据集信息列表:
https://docs.google.com/spreadsheets/d/1rPBD77tk60AEIGZrGSODwyyzs5FgCU9Uz3h-3_t2A9g/edit?pli=1#gid=0
关键词:
● 21个科研机构
● 22个机器人
● 60个已有数据集的融合
● 527个技能
● 160,266个任务
● 1,402,930条数据(共约3600G)
数据处理:
所有源数据集统一转化为RLDS格式。
对于源数据的不同格式和内容,做了以下处理:
1. 对于存在多视角的数据集,仅选择其中“canonical”的一个视角图像(猜测为比较接近top-down第一人称视角/Proprioception的那一个)。
2. 将图像resize到320×256(width×height)。
3. 将原有的动作(比如joint position)都转换为EE的动作,但是该动作量可能为相对值,也可能为绝对值。在模型输出action tokens∈ [0, 255]\in [0, 255]后根据不同的机器人做不同的de-normalization后再下达具体的控制指令。
数据集特征:
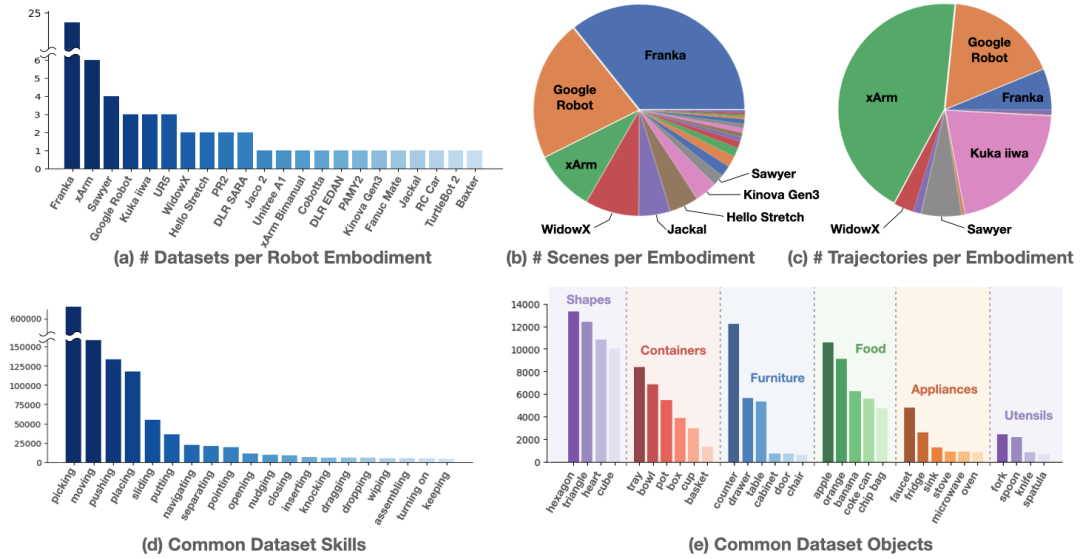
1. 60个数据集中涉及到的机器人有单臂、双臂和四足,Franka占多数。
2. 数据量上,xArm占最大头,主要是language table的数据集体量很大,有44万条;Kuka iiwa主要来自于QT-Opt的贡献;另外就是原来在Everday Robot(现在论文中称为Google Robot)上采集的RT1的数据。
3. 技能上主要还是集中在pick-place上,整体仍呈现长尾分布,尾部有许多如wiping、assembling等难度更高的技能。
4. 主要的场景和被操作物体集中在家庭、厨房场景和家具、食物、餐具等物品。[1]
子数据集介绍
No.1 RoboVQA
● 发布方:不来梅大学
● 发布时间:2019
● 简介:
RobotVQA 以场景RGB(D)图像作为输入并输出相应的场景图。RobotVQA 代表机器人视觉问答。作者展示了 RobotVQA 知识从虚拟世界到现实世界的可转移性以及对机器人控制程序的适用性。
● 下载地址:
https://opendatalab.com/OpenDataLab/RoboVQA
● 论文地址:
https://arxiv.org/pdf/1709.10489.pdf
No.2 RoboNet
● 发布方:卡内基梅隆大学·宾夕法尼亚大学·斯坦福大学
● 发布时间:2020
● 简介:
一个用于共享机器人经验的开放数据库,它提供了来自 7 个不同机器人平台的 1500 万个视频帧的初始池,并研究了如何使用它来学习基于视觉的机器人操作的通用模型。
● 下载地址:
https://opendatalab.com/OpenDataLab/RoboNet
● 论文地址:
https://arxiv.org/pdf/1910.11215v2.pdf
No.3 BridgeData V2
● 发布方:Google·加州大学伯克利分校·斯坦福大学
● 发布时间:2023
● 简介:
BridgeData V2 是一个庞大而多样化的机器人操作行为数据集,旨在 促进可扩展机器人学习的研究。数据集兼容开放词汇、多任务 以目标图像或自然语言指令为条件的学习方法。从数据中学到的技能 推广到新的对象和环境,以及跨机构。
● 下载地址:
https://opendatalab.com/OpenDataLab/BridgeData_V2
● 论文地址:
https://arxiv.org/pdf/2308.12952.pdf
No.4 Language Table
● 发布方:Google
● 发布时间:2022
● 简介:
Language-Table 是一套人类收集的数据集,也是开放词汇视觉语言运动学习的多任务连续控制基准。
● 下载地址:
https://opendatalab.com/OpenDataLab/Language_Table
● 论文地址:
https://arxiv.org/pdf/2210.06407.pdf
No.5 BC-Z
● 发布方:卡内基梅隆大学·宾夕法尼亚大学·斯坦福大学
● 发布时间:2020
● 简介:
作者收集了 100 个操作任务的大规模 VR 远程操作演示数据集,并训练卷积神经网络来模仿 RGB 像素观察的闭环动作。
● 下载地址:
https://opendatalab.com/OpenDataLab/BC_Z
● 论文地址:
https://arxiv.org/pdf/1910.11215v2.pdf
No.6 CMU Food Manipulation(Food Playing Dataset)
● 发布方:卡内基梅隆大学机器人研究所
● 发布时间:2021
● 简介:
使用机械臂和一系列传感器(使用 ROS 进行同步)收集的多样化的数据集,其中包含 21 种具有不同切片和特性的独特食品。通过视觉嵌入网络,该网络利用本体感受、音频和视觉数据的组合,使用三元组损失公式对食物之间的相似性进行了编码。
● 下载地址:
https://opendatalab.com/OpenDataLab/CMU_Food_Manipulation
● 论文地址:
https://arxiv.org/pdf/2309.14320.pdf
No.7 TOTO Benchmark
● 发布方:纽约大学·Meta AI·卡内基梅隆大学
● 发布时间:2022
● 简介:
在线训练离线测试 (TOTO) 是一个在线基准测试,提供:开源操作数据集,访问共享机器人进行评估。
● 下载地址:
https://opendatalab.com/OpenDataLab/TOTO_Benchmark
● 论文地址:
https://arxiv.org/pdf/2306.00942.pdf
No.8 QUT Dynamic Grasping
● 发布方:昆士兰科技大学
● 发布时间:2022
● 简介:
该数据集包含 812 个成功的轨迹,这些轨迹与使用 Franka Panda 机器人机械臂自上而下的动态抓取移动物体有关。物体随机放置在XY运动平台上,该平台可以以不同的速度在任意轨迹中移动物体。该系统使用此处描述的 CoreXY 运动平台设计。设计中的所有部件都可以3D打印或轻松采购。
● 下载地址:
https://opendatalab.com/OpenDataLab/QUT_Dynamic_Grasping
● 论文地址:
https://arxiv.org/pdf/2309.02754.pdf
No.9 Task-Agnostic Real World Robot Play
● 发布方:弗赖堡大学·埃尔朗根-纽伦堡大学
● 发布时间:2023
● 简介:
7-DoF 机械臂和平行钳口抓手执行各种无定向操作任务的情节,大约 1% 的数据使用自然语言嵌入进行注释。通过VR控制器使用远程操作收集情节,告诉用户在没有特定任务的情况下远程操作机器人。每个状态-动作对都编码在 Numpy npz 文件中,由静态和抓手相机、本体感受状态以及与该状态对应的机器人未来动作的 RGB-D 图像组成。
● 下载地址:
https://opendatalab.com/OpenDataLab/Task_Agnostic_Real_World_Robot_Play
● 论文地址:
http://tacorl.cs.uni-freiburg.de/paper/taco-rl.pdf
No.10 Roboturk
● 发布方:斯坦福大学
● 发布时间:2019
● 简介:
RoboTurk 真实机器人数据集收集了有关三个不同现实世界任务的大型数据集:洗衣房布局、塔楼创建和对象搜索。所有三个数据集都是使用 RoboTurk 平台收集的,由众包工作人员远程收集。我们的数据集包含来自 54 个不同用户的 2144 个不同演示。我们提供用于训练的完整数据集和用于探索的数据集的较小子样本。
● 下载地址:
https://opendatalab.com/OpenDataLab/Roboturk
● 论文地址:
https://arxiv.org/pdf/1911.04052.pdf
因篇幅有限,更多机器人学习开源数据集,请访问OpenDataLab:
参考:[1]https://www.zhihu.com/question/624716226

















 1892
1892

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









